Logstash从Oracle全量、增量、定时抽取数据至ES
Logstash从Oracle全量、增量、定时抽取数据至ES
- 下载Logstash
- Oracle->ES全量
- Oracle->ES增量
- 多管道运行任务
下载Logstash
[https://www.elastic.co/cn/downloads/logstash]
Oracle->ES全量
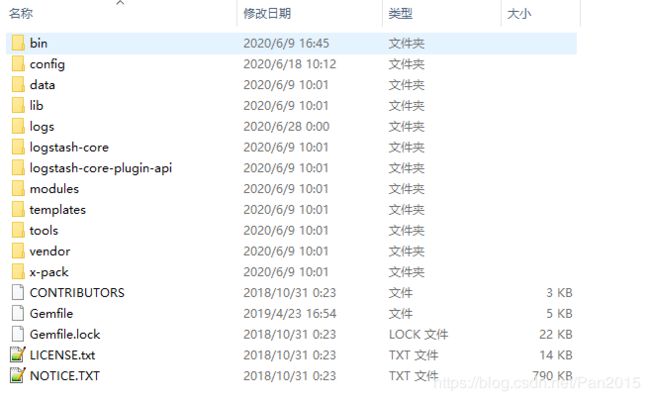
- 解压缩下载的Logstash包,如下图所示
- 在/bin路径下创建 jdbc_orcl_all.config文件
input {
stdin {}
jdbc {
#ES中type
type => "pc_bkrwxxsjx"
#数据库链接信息
jdbc_connection_string => "jdbc:oracle:thin:username/password@//10.4.124.170:1521/orcl"
#用户名
jdbc_user => "username"
#密码
jdbc_password => "password"
#ojdbc6.jar包所在运行logstash程序服务器的路径
jdbc_driver_library => "F:\05_Kettle\oracle_jdbc_jar\ojdbc6.jar"
#驱动类型
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
#源表字段名导入ES后是否忽略大小写
lowercase_column_names=> false
#分页
jdbc_paging_enabled => "true"
#每页数据量
jdbc_page_size => "50000"
#默认时区
jdbc_default_timezone => "UTC"
#执行sql语句或者指定.sql文件路径。statement_filepath => "D:\logstash\oracle_sql\PC_AJWJWPJBXXSJX.sql"
statement => "SELECT * FROM PC_BKRWXXSJX"
#定时设置,corn表达式
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
if[type] == "pc_bkrwxxsjx"{
elasticsearch {
#ES ip:port
hosts => "ip:port"
#ES索引名
index => "pc_bkrwxxsjx"
document_type => "pc_bkrwxxsjx"
document_id => "%{ID}"
}
}
stdout {
codec => json_lines
}
}
3.cmd运行 .\logstash -f .\jdbc_orcl_all.config;
Oracle->ES增量
- 在/bin路径下创建 jdbc_orcl_increment.config文件
注:如下配置文件为多张表增量抽取
input {
stdin {}
jdbc {
#进入ES中index的type
type => "pc_bkrwxxsjx"
#数据库链接信息
jdbc_connection_string => "jdbc:oracle:thin:username/password@//10.4.124.170:1521/orcl"
#用户名
jdbc_user => "username"
#密码
jdbc_password => "password"
#ojdbc6.jar包所在运行logstash程序服务器的路径
jdbc_driver_library => "F:\05_Kettle\oracle_jdbc_jar\ojdbc6.jar"
#驱动类型
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
#源表字段名导入ES后是否忽略大小写
lowercase_column_names=> false
#分页
jdbc_paging_enabled => "true"
#每页数据量
jdbc_page_size => "50000"
#默认时区
jdbc_default_timezone => "UTC"
#增量抽取数据sql或指定路径下的.sql文件
statement => "SELECT * FROM PC_BKRWXXSJX WHERE UPDATE_TIME > :sql_last_value"
#是否使用字段值作为增量标识
use_column_value => true
#增量标识字段名
tracking_column => UPDATE_TIME
#字段类型
tracking_column_type => timestamp
#上次数据存放位置
record_last_run => true
#存储增量标识数据文件路径
last_run_metadata_path => "D:\logstash\logstash\logstash-6.4.3\logstash-6.4.3\config\pc_bkrwxxsjx_parameter.txt"
#是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false
clean_run => false
#定时设置,corn表达式
schedule => "* * * * *"
}
jdbc {
#进入ES中index的type
type => "pc_basicinformtion"
#数据库链接信息
jdbc_connection_string => "jdbc:oracle:thin:username/password@//10.4.124.170:1521/orcl"
#用户名
jdbc_user => "username"
#密码
jdbc_password => "password"
#ojdbc6.jar包所在运行logstash程序服务器的路径
jdbc_driver_library => "F:\05_Kettle\oracle_jdbc_jar\ojdbc6.jar"
#驱动类型
jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver"
#源表字段名导入ES后是否忽略大小写
lowercase_column_names=> false
#是否分页
jdbc_paging_enabled => "true"
#每页数据量
jdbc_page_size => "50000"
#默认时区
jdbc_default_timezone => "UTC"
#增量抽取数据sql或指定路径下的.sql文件
statement => "SELECT * FROM PC_BASICINFORMTION WHERE UPDATE_TIME > :sql_last_value"
#是否使用字段值作为增量标识
use_column_value => true
#增量标识字段名
tracking_column => UPDATE_TIME
#字段类型
tracking_column_type => timestamp
#上次数据存放位置
record_last_run => true
#存储增量标识数据文件路径
last_run_metadata_path => "D:\logstash\logstash\logstash-6.4.3\logstash-6.4.3\config\pc_basicinformtion_parameter.txt"
#是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false
clean_run => false
#定时设置,corn表达式
schedule => "* * * * *"
}
}
filter {
json {
source => "message"
remove_field => ["message"]
}
}
output {
if[type] == "pc_bkrwxxsjx"{
elasticsearch {
#ES ip:port
hosts => "ip:port"
#ES索引名
index => "pc_bkrwxxsjx"
document_type => "pc_bkrwxxsjx"
document_id => "%{ID}"
}
}
if[type] == "pc_basicinformtion"{
elasticsearch {
#ES ip:port
hosts => "ip:port"
#ES索引名
index => "pc_basicinformtion"
document_type => "pc_basicinformtion"
document_id => "%{ID}"
}
}
stdout {
codec => json_lines
}
}
2.cmd运行 .\logstash -f .\jdbc_orcl_increment.config;
多管道运行任务
1.编辑\logstash-6.4.3\config\pipelines.yml
# List of pipelines to be loaded by Logstash
#
# This document must be a list of dictionaries/hashes, where the keys/values are pipeline settings.
# Default values for ommitted settings are read from the `logstash.yml` file.
# When declaring multiple pipelines, each MUST have its own `pipeline.id`.
#
#Example of two pipelines:
- pipeline.id: pc_basicinformtion
pipeline.workers: 1
path.config: "D:\\logstash\\logstash\\logstash-6.4.3\\logstash-6.4.3\\bin\\jdbc_orcl_pc_basicinformtion.config"
pipeline.batch.size: 1
- pipeline.id: pc_bkrwxxsjx
queue.type: persisted
path.config: "D:\\logstash\\logstash\\logstash-6.4.3\\logstash-6.4.3\\bin\\jdbc_orcl_pc_bkrwxxsjx.config"
#
# Available options:
#
# # name of the pipeline
# pipeline.id: mylogs
#
# # The configuration string to be used by this pipeline
# config.string: "input { generator {} } filter { sleep { time => 1 } } output { stdout { codec => dots } }"
#
# # The path from where to read the configuration text
# path.config: "/etc/conf.d/logstash/myconfig.cfg"
#
# # How many worker threads execute the Filters+Outputs stage of the pipeline
# pipeline.workers: 1 (actually defaults to number of CPUs)
#
# # How many events to retrieve from inputs before sending to filters+workers
# pipeline.batch.size: 125
#
# # How long to wait in milliseconds while polling for the next event
# # before dispatching an undersized batch to filters+outputs
# pipeline.batch.delay: 50
#
# # How many workers should be used per output plugin instance
# pipeline.output.workers: 1
#
# # Internal queuing model, "memory" for legacy in-memory based queuing and
# # "persisted" for disk-based acked queueing. Defaults is memory
# queue.type: memory
#
# # If using queue.type: persisted, the page data files size. The queue data consists of
# # append-only data files separated into pages. Default is 64mb
# queue.page_capacity: 64mb
#
# # If using queue.type: persisted, the maximum number of unread events in the queue.
# # Default is 0 (unlimited)
# queue.max_events: 0
#
# # If using queue.type: persisted, the total capacity of the queue in number of bytes.
# # Default is 1024mb or 1gb
# queue.max_bytes: 1024mb
#
# # If using queue.type: persisted, the maximum number of acked events before forcing a checkpoint
# # Default is 1024, 0 for unlimited
# queue.checkpoint.acks: 1024
#
# # If using queue.type: persisted, the maximum number of written events before forcing a checkpoint
# # Default is 1024, 0 for unlimited
# queue.checkpoint.writes: 1024
#
# # If using queue.type: persisted, the interval in milliseconds when a checkpoint is forced on the head page
# # Default is 1000, 0 for no periodic checkpoint.
# queue.checkpoint.interval: 1000
#
# # Enable Dead Letter Queueing for this pipeline.
# dead_letter_queue.enable: false
#
# If using dead_letter_queue.enable: true, the maximum size of dead letter queue for this pipeline. Entries
# will be dropped if they would increase the size of the dead letter queue beyond this setting.
# Default is 1024mb
# dead_letter_queue.max_bytes: 1024mb
#
# If using dead_letter_queue.enable: true, the directory path where the data files will be stored.
# Default is path.data/dead_letter_queue
#
# path.dead_letter_queue:
2.cmd启动。.\logstash
注:在没有参数的情况下启动logstash时,它将读取pipelines.yml文件并实例化文件中指定的所有管道,当使用-e或-f时,Logstash会忽略pipelines.yml文件,并记录对此的警告。