前言
这篇文章咱们先简单的叙述下官方刚发布的最新版本中的native部署java语言编写的智能合约的过程然后再说下存证合约的代码实现逻辑,下一篇文章咱们说下如何根据自己公司的业务逻辑定义合约里面的数据结构来实现智能合约
先简单说下关于文档访问慢的问题
官方文档是 https://xuperchain.readthedoc..._documents/XuperModel.html
该文档是在国外部署的,所以国内访问的话,如果自己所在的网络不太好的情况下,打开网页是很慢的,这种情况大家可以将相应版本的文档下载到自己的本地,这样的话 就不会受网速的影响了
下载地址:
https://readthedocs.org/proje...
选择相应的版本即可

版本升级已支持java语言编写的智能合约
大概2020年7月13号左右的时候 官方更新了一版本 在master分支上 该版本已支持了java语言编写的智能合约
接下来咱们首先下拉下最新的代码、然后编译、运行下,这个过程咱之前发过的文章也已经很详细的描述过了,这里就不再赘述了,感兴趣的朋友 可以看下这2篇文章
在百度超级链Xuper上部署智能合约并实现存证功能 和 对百度超级链Xuper使用过程中的进一步理解
native模式下java智能合约的部署
java智能合约是native部署的方式,所以首先需要修改下配置文件以开启native合约部署
`vim 每个节点路径/conf/xchain.yaml
# 管理native合约的配置
native:
enable: true`
启动命令
`nohup ./xchain &
这里没有加--vm ixvm 这个是wasm合约部署的方式`
因为这里修改了配置 所以需要先删除数据,再启动 我这是在本地环境搭建的,所以节点数据都不太重要,要是公司的数据,那么就不需要轻易的修改配置了
编译环境
编译Java sdk:Java版本不低于Java1.8版本
包管理器:maven,mvn版本3.6+
配置maven环境
`vim /etc/profile
export M2_HOME=/Users/mengfanxiao/Documents/third_software/maven/apache-maven-3.6.2
export PATH=$PATH:$M2_HOME/bin
source /etc/profile
mvn -v`
编译合约sdk
`cd xuperchain/core/contractsdk/java
mvn install -f pom.xml`
产出二进制文件target/java-contract-sdk-0.1.0.jar,并自动安装到mvn本地仓库下
编译native合约时,以contractsdk/java/example中的counter合约为例
`cd contractsdk/java/example/counter
mvn package -f pom.xml`
产出二进制文件target/counter-0.1.0-jar-with-dependencies.jar,用于合约部署
合约部署
./xchain-cli native deploy --account XC1111111111111111@xuper --fee 15587517 --runtime java xuperchain/data/javacontract/counter-0.1.0-jar-with-dependencies.jar --cname javacounter
合约调用
- 命令行调用
./xchain-cli native invoke --method Increase -a '{"key":"test"}' javacounter --fee 10
- 通过java sdk 发起合约交易
`@Test
public void invokeContract() throws Exception {
Map
args.put("key", "icexin".getBytes());
Transaction tx = client.invokeContract(account, "native", "javacounter", "increase", args);
System.out.println("invoke txid: " + tx.getTxid());
System.out.println("response: " + tx.getContractResponse().getBodyStr());
System.out.println("gas: " + tx.getGasUsed());
}`
注意这里一定要是native模式
合约查询
- 通过Java sdk 查询
`@Test
public void queryContractJava() throws Exception {
Map
args.put("key", "icexin".getBytes());
Transaction tx = client.queryContract(account, "native", "javacounter", "get", args);
System.out.println("response: " + tx.getContractResponse().getBodyStr());
System.out.println("gas: " + tx.getGasUsed());
}`
native模式下go语言编写的智能合约部署
还是以counter合约文件为例
`cd contractsdk/go/example/counter
go build counter.go`
部署合约文件
./xchain-cli native deploy --account XC1111111111111111@xuper -a '{"creator":"XC1111111111111111@xuper"}' --fee 15587517 --runtime go xuperchain/data/gocontract/counter --cname golangcounter
调用合约文件
- 命令行调用
./xchain-cli native invoke --method Increase -a '{"key":"test"}' golangcounter --fee 10
- Javasdk调用
`@Test
public void invokeContractG0() throws Exception {
Map
args.put("key", "icexin".getBytes());
Transaction tx = client.invokeContract(account, "native", "golangcounter", "increase", args);
System.out.println("invoke txid: " + tx.getTxid());
System.out.println("response: " + tx.getContractResponse().getBodyStr());
System.out.println("gas: " + tx.getGasUsed());
}`
查询合约文件
通过Javasdk查询
`@Test
public void queryContractGo() throws Exception {
Map
args.put("key", "icexin".getBytes());
Transaction tx = client.queryContract(account, "native", "golangcounter", "get", args);
System.out.println("response: " + tx.getContractResponse().getBodyStr());
System.out.println("gas: " + tx.getGasUsed());
}`
分别部署完了java和go语言写的counter合约之后 咱们其实就知道了 流程都是一模一样的
可能出现的异常信息
- 如果报 contract type native not found 说明没有开启native合约配置
- 如果报 context deadline exceeded 说明 你可能用的是旧版本的合约文件 所以需要重新编译下新版本的合约源码生成合约文件
-
- *
上面简单描述了截止目前7月15号基于最新版本部署的过程以及通过native合约部署的方式分别部署和使用go和java2种语言编写的智能合约的过程,下面结合公司的业务来描述下存证智能合约的实现逻辑
存证智能合约目前版本还没有java语言编写的合约模版,大概2周之后才会有
下面咱分析下go语言版本的存证合约的逻辑
先简单说下数据结构
`user对象的数据结构
{
"Owner":"xiaoming" , # 这个表示用户名
"UserFiles":{ # 这个是一个map集合
"filehash":{ # map集合的key是文件hash
"Timestamp":"" # 时间戳
"Hashval":"" # []byte(filehash) 其实也是hash值
}
}
}`
合约部署的时候数据初始化


在合约部署的时候会调用Initialize方法
首先获取到部署命令中的owner参数表示用户名 然后调用链上的方法GetObject来查询该用户名对应的value
智能合约调用的链上的方法就2个 一个是PutObject 将key-value保存到链上
另外一个是GetObject 根据key获取对应的value
如果value为空的话 则初始化一个空的user对象 并转换成json字符串上链保存
合约上链交易的方法

这个方法首先根据owner(代表用户名称)去链上查询对应的value 根据上面的分析 该value保存着一个用户对象,第一次调用的时候该用户对象是里面的属性都没有进行初始化呢 然后调用putFile方法

首先初始化一个UserFile对象 这里面保存了一条上链的信息
将该对象作为一个元素 保存到 user对象里面的userfiles这个map集合中 key是filehash value是userFile
然后将用户对象转换成json字符串保存到链上
合约交易查询

通过用户名称到链上查询到了用户对象

根据filehash遍历该用户对象的userfiles这个map集合 找到对应的userfile元素
截止到这里 是不是发现了 这个存证合约模版的逻辑其实很简单
总结下上面的逻辑
智能合约调用链上的2个方法
- PutObject 将k-v上链保存
- GetObject 通过k查询v
一个数据结构
- 一个user对象 里面有一个map集合 里面的元素是每次上链的数据 可以通过map的key来定位到那一条上链数据
问题发现
filehash重复
大家看过上面的代码有没有发现一个问题
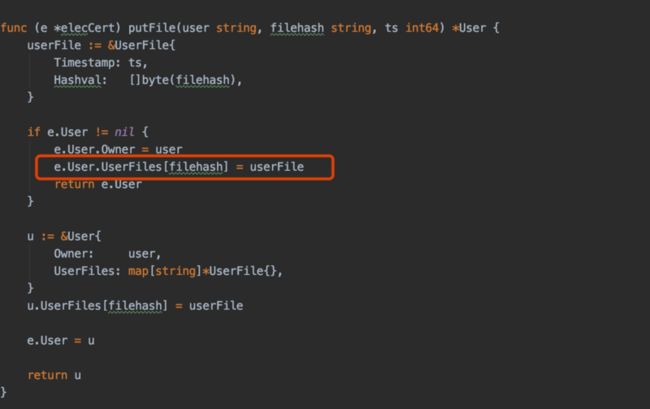
圈红的地方是将单次上链数据userFile 放入map集合中 ,key是filehash,如果2次上传的filehash相同,那么就会把之前的filehash对应的value值给替换掉
但是呢 相同的上链数据却返回不同的交易id,内部实现机制是怎样的和如果根据公司的业务来定义数据结构以实现智能合约等下一篇文章咱们再分析下。
本文使用 mdnice 排版