Web框架本质
1.本质
对于所有的Web应用,本质上其实就是一个socket服务端,用户的浏览器其实就是一个socket客户端。
2.原始版Web
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 80))
sk.listen()
while True:
conn, addr = sk.accept()
data = conn.recv(8096)
conn.send(b"OK")
conn.close()
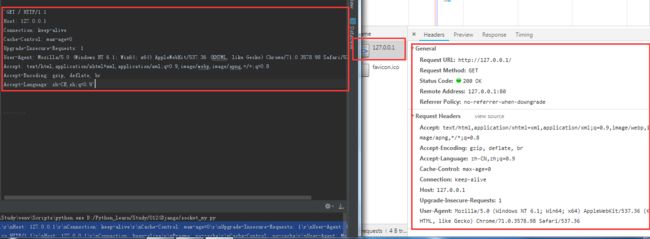
我们在浏览器上输入:http://127.0.0.1/ 就可以看到服务端发来的"ok"了。可以说Web服务本质上都是在这十几行代码基础上扩展出来的。用户的浏览器一输入网址,会给服务端发送数据,那浏览器会发送什么数据?怎么发?这个谁来定? 这个规则就是HTTP协议,以后浏览器发送请求信息也好,服务器回复响应信息也罢,都要按照这个规则来。HTTP协议主要规定了客户端和服务器之间的通信格式,那HTTP协议是怎么规定消息格式的呢?让我们首先打印下我们在服务端接收到的消息是什么。
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 80))
sk.listen(5)
while True:
conn, addr = sk.accept()
data = conn.recv(8096)
print(data) # 将浏览器发来的消息打印出来
conn.send(b"OK")
conn.close()
下图左边就是服务端接收到浏览器的数据,右边是浏览器收到的响应数据。
3.HTTP工作原理
a.客户端连接到Web服务器
一个HTTP客户端,通常是浏览器,与Web服务器的HTTP端口(默认为80)建立一个TCP套接字连接。
b. 发送HTTP请求
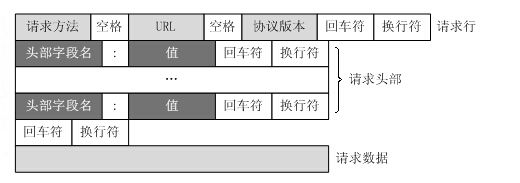
通过TCP套接字,客户端向Web服务器发送一个文本的请求报文,一个请求报文由请求行、请求头部、空行和请求数据4部分组成。
c. 服务器接受请求并返回HTTP响应
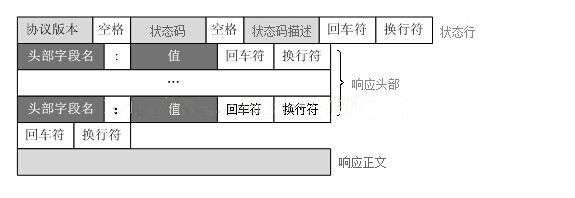
Web服务器解析请求,定位请求资源。服务器将资源复本写到TCP套接字,由客户端读取。一个响应由状态行、响应头部、空行和响应数据4部分组成。
d. 释放连接TCP连接
若connection 模式为close,则服务器主动关闭TCP连接,客户端被动关闭连接,释放TCP连接;若connection 模式为keepalive,则该连接会保持一段时间,在该时间内可以继续接收请求;
e. 客户端浏览器解析HTML内容
客户端浏览器首先解析状态行,查看表明请求是否成功的状态代码。然后解析每一个响应头,响应头告知以下为若干字节的HTML文档和文档的字符集。客户端浏览器读取响应数据HTML,根据HTML的语法对其进行格式化,并在浏览器窗口中显示。
4.HTTP状态码
所有HTTP响应的第一行都是状态行,依次是当前HTTP版本号,3位数字组成的状态代码,以及描述状态的短语,彼此由空格分隔。
状态代码的第一个数字代表当前响应的类型:
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误
虽然 RFC 2616 中已经推荐了描述状态的短语,例如"200 OK","404 Not Found",但是WEB开发者仍然能够自行决定采用何种短语,用以显示本地化的状态描述或者自定义信息。
5.URL
超文本传输协议(HTTP)的统一资源定位符将从因特网获取信息的五个基本元素包括在一个简单的地址中:
- 传送协议。
- 层级URL标记符号(为[//],固定不变)
- 访问资源需要的凭证信息(可省略)
- 服务器。(通常为域名,有时为IP地址)
- 端口号。(以数字方式表示,若为HTTP的默认值“:80”可省略)
- 路径。(以“/”字符区别路径中的每一个目录名称)
- 查询。(GET模式的窗体参数,以“?”字符为起点,每个参数以“&”隔开,再以“=”分开参数名称与数据,通常以UTF8的URL编码,避开字符冲突的问题)
- 片段。以“#”字符为起点
由于超文本传输协议允许服务器将浏览器重定向到另一个网页地址,因此许多服务器允许用户省略网页地址中的部分,比如 www。从技术上来说这样省略后的网页地址实际上是一个不同的网页地址,浏览器本身无法决定这个新地址是否通,服务器必须完成重定向的任务。
5.HTTP协议对收发消息的格式要求
(1)HTTP GET请求的格式:
(2)HTTP响应的格式:
6.自定义版Web框架
import socket
sk = socket.socket()
sk.bind(("127.0.0.1", 80))
sk.listen(5)
# 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
print(data)
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文
conn.send(b'OK')
# 关闭
conn.close()
7.根据不同路径返回不同的内容
"""
完善的web服务端示例
根据不同的路径返回不同的内容
"""
import socket
# 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 80))
# 监听
sk.listen(5)
# 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文
# 根据不同的url返回不同的内容
if url == "/felix/":
response = b'Welcome to felix home
'
elif url == "/lisa/":
response = b'Welcome to lisa home
'
else:
response = b'404! not found!
'
conn.send(response)
# 关闭
conn.close()
8.函数版根据不同路径返回不同的内容
"""
完善的web服务端示例
函数版根据不同的路径返回不同的内容
进阶函数版 不写if判断了,用url名字去找对应的函数名
"""
import socket
# 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 80))
# 监听
sk.listen(5)
# 定义一个处理/felix/的函数
def felix(url):
ret = 'hello {}'.format(url)
return bytes(ret, encoding="utf-8")
# 定义一个处理/xiaohei/的函数
def lisa(url):
ret = 'hello {}'.format(url)
return bytes(ret, encoding="utf-8")
# 定义一个专门用来处理404的函数
def f404(url):
ret = "你访问的这个{} 找不到".format(url)
return bytes(ret, encoding="utf-8")
url_func = [
("/felix/", felix),
("/lisa/", lisa),
]
# 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文
# 根据不同的url返回不同的内容
# 去url_func里面找对应关系
for i in url_func:
if i[0] == url:
func = i[1]
break
# 找不到对应关系就默认执行f404函数
else:
func = f404
# 拿到函数的执行结果
response = func(url)
# 将函数返回的结果发送给浏览器
conn.send(response)
# 关闭连接
conn.close()
9.函数版根据不同路径返回不同的HTML内容
"""
完善的web服务端示例
函数版根据不同的路径返回不同的内容
进阶函数版 不写if判断了,用url名字去找对应的函数名
返回html页面
"""
import socket
# 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 80))
# 监听
sk.listen(5)
# 定义一个处理/felix/的函数
def felix(url):
with open("felix.html", "rb") as f:
ret = f.read()
return ret
# 定义一个处理/lisa/的函数
def lisa(url):
with open("lisa.html", "rb") as f:
ret = f.read()
return ret
# 定义一个专门用来处理404的函数
def f404(url):
ret = "你访问的这个{} 找不到".format(url)
return bytes(ret, encoding="utf-8")
url_func = [
("/felix/", felix),
("/lisa/", lisa),
]
# 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文
# 根据不同的url返回不同的内容
# 去url_func里面找对应关系
for i in url_func:
if i[0] == url:
func = i[1]
break
# 找不到对应关系就默认执行f404函数
else:
func = f404
# 拿到函数的执行结果
response = func(url)
# 将函数返回的结果发送给浏览器
conn.send(response)
# 关闭连接
conn.close()
10.动态网页
"""
完善的web服务端示例
函数版根据不同的路径返回不同的内容
进阶函数版 不写if判断了,用url名字去找对应的函数名
返回html页面
返回动态的html页面
"""
import socket
# 生成socket实例对象
sk = socket.socket()
# 绑定IP和端口
sk.bind(("127.0.0.1", 80))
# 监听
sk.listen(5)
# 定义一个处理/yimi/的函数
def felix(url):
with open("felix.html", "r", encoding="utf-8") as f:
ret = f.read()
import time
# 得到替换后的字符串
ret2 = ret.replace("@@xx@@", str(time.time()))
return bytes(ret2, encoding="utf-8")
# 定义一个处理/xiaohei/的函数
def lisa(url):
with open("lisa.html", "rb") as f:
ret = f.read()
return ret
# 定义一个专门用来处理404的函数
def f404(url):
ret = "你访问的这个{} 找不到".format(url)
return bytes(ret, encoding="utf-8")
url_func = [
("/felix/", felix),
("/lisa/", lisa),
]
# 写一个死循环,一直等待客户端来连我
while 1:
# 获取与客户端的连接
conn, _ = sk.accept()
# 接收客户端发来消息
data = conn.recv(8096)
# 把收到的数据转成字符串类型
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8")
# print(data_str)
# 用\r\n去切割上面的字符串
l1 = data_str.split("\r\n")
# print(l1[0])
# 按照空格切割上面的字符串
l2 = l1[0].split()
url = l2[1]
# 给客户端回复消息
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n')
# 想让浏览器在页面上显示出来的内容都是响应正文
# 根据不同的url返回不同的内容
# 去url_func里面找对应关系
for i in url_func:
if i[0] == url:
func = i[1]
break
# 找不到对应关系就默认执行f404函数
else:
func = f404
# 拿到函数的执行结果
response = func(url)
# 将函数返回的结果发送给浏览器
conn.send(response)
# 关闭连接
conn.close()
HTML网页内容:
felix
web框架的本质
@@xx@@
二、服务器程序和应用程序
对于真实开发中的python web程序来说,一般会分为两部分:服务器程序和应用程序。
服务器程序负责对socket服务器进行封装,并在请求到来时,对请求的各种数据进行整理。
应用程序则负责具体的逻辑处理。为了方便应用程序的开发,就出现了众多的Web框架,例如:Django、Flask、web.py 等。不同的框架有不同的开发方式,但是无论如何,开发出的应用程序都要和服务器程序配合,才能为用户提供服务。
WSGI(Web Server Gateway Interface)就是一种规范,它定义了使用Python编写的web应用程序与web服务器程序之间的接口格式,实现web应用程序与web服务器程序间的解耦。
常用的WSGI服务器有uwsgi、Gunicorn。而Python标准库提供的独立WSGI服务器叫wsgiref,Django开发环境用的就是这个模块来做服务器。
1.wsgiref封装的socket版web框架
"""
根据URL中不同的路径返回不同的内容--函数进阶版
返回HTML页面
让网页动态起来
wsgiref模块版
"""
import time
from wsgiref.simple_server import make_server
# 将返回不同的内容部分封装成函数
def felix(url):
with open("felix.html", "r", encoding="utf8") as f:
s = f.read()
now = str(time.time())
s = s.replace("@@xx@@", now)
return bytes(s, encoding="utf8")
def lisa(url):
with open("lisa.html", "r", encoding="utf8") as f:
s = f.read()
return bytes(s, encoding="utf8")
# 定义一个url和实际要执行的函数的对应关系
list1 = [
("/felix/", felix),
("/lisa/", lisa),
]
def run_server(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息
url = environ['PATH_INFO'] # 取到用户输入的url
func = None
for i in list1:
if i[0] == url:
func = i[1]
break
if func:
response = func(url)
else:
response = b"404 not found!"
return [response, ]
if __name__ == '__main__':
httpd = make_server('127.0.0.1', 8090, run_server)
print("我在8090等你哦...")
httpd.serve_forever()
2.jinja2模板渲染版web框架---完成HTML页面内容的替换
from wsgiref.simple_server import make_server
from jinja2 import Template
def index():
with open("jinjia2.html", "r", encoding="utf-8") as f:
data = f.read()
template = Template(data) # 生成模板文件
# 从数据库中取数据
import pymysql
conn = pymysql.connect(
host="127.0.0.1",
port=3306,
user="root",
password="",
database="userinfo",
charset="utf8",
)
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
cursor.execute("select * from user;")
user_list = cursor.fetchall()
print(user_list)
# 实现字符串的替换
ret = template.render({"user_list": user_list}) # 把数据填充到模板里面
return [bytes(ret, encoding="utf8"), ]
def home():
with open("home.html", "rb") as f:
data = f.read()
return [data, ]
# 定义一个url和函数的对应关系
URL_LIST = [
("/", index),
("/home/", home),
]
def run_server(environ, start_response):
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 设置HTTP响应的状态码和头信息
url = environ['PATH_INFO'] # 取到用户输入的url
func = None # 将要执行的函数
for i in URL_LIST:
if i[0] == url:
func = i[1] # 去之前定义好的url列表里找url应该执行的函数
break
if func: # 如果能找到要执行的函数
return func() # 返回函数的执行结果
else:
return [bytes("404没有该页面", encoding="utf8"), ]
if __name__ == '__main__':
httpd = make_server('', 80, run_server)
print("Serving HTTP on port 8000...")
httpd.serve_forever()
HTML网页内容:
Title
ID
用户名
密码
{% for user in user_list %}
{{user.id}}
{{user.username}}
{{user.password}}
{% endfor %}
网页内容:

三、总结
1.关于HTTP协议:
(1)浏览器往服务端发的叫 请求(request)
请求的消息格式:
请求方法 路径 HTTP/1.1\r\n
k1:v1\r\n
k2:v2\r\n
\r\n
请求数据
(2)服务端往浏览器发的叫 响应(response)
响应的消息格式:
HTTP/1.1 状态码 状态描述符\r\n
k1:v1\r\n
k2:v2\r\n
\r\n
响应正文 <-- html的内容
2. web框架的本质:
socket服务端 与 浏览器的通信
3. socket服务端功能划分:
- a. 负责与浏览器收发消息(socket通信) --> wsgiref/uWsgi/gunicorn...
- b. 根据用户访问不同的路径执行不同的函数
- c. 从HTML读取出内容,并且完成字符串的替换 --> jinja2(模板语言)
4. Python中 Web框架的分类:
- 1. 框架自带a,b,c --> Tornado
- 2. 框架自带b和c,使用第三方的a --> Django
- 3. 框架自带b,使用第三方的a和c --> Flask