目录
- Spark学习笔记3——RDD(下)
- 向Spark传递函数
- 通过匿名内部类
- 通过具名类传递
- 通过带参数的 Java 函数类传递
- 通过 lambda 表达式传递(仅限于 Java 8 及以上)
- 常见的转化操作和行动操作
- 基本RDD
- 行动操作
- 不同 RDD 的类型转换
- 持久化
- 向Spark传递函数
Spark学习笔记3——RDD(下)
笔记摘抄自 [美] Holden Karau 等著的《Spark快速大数据分析》
向Spark传递函数
大部分 Spark 的转化操作和一部分行动操作,都需要传递函数后进行计算。如何传递函数下文将用 Java 展示。
Java 向 Spark 传递函数需要实现 Spark 的 org.apache.spark.api.java.function 包中的接口。一些基本的接口如下表:
| 函数名 | 实现的方法 | 用途 |
|---|---|---|
| Function |
R call(T) | 接收一个输入值并返回一个输出值,用于类似map() 和 filter() 等操作中 |
| Function2 |
R call(T1, T2) | 接收两个输入值并返回一个输出值,用于类似aggregate() 和fold() 等操作中 |
| FlatMapFunction |
Iterable call(T) | 接收一个输入值并返回任意个输出,用于类似flatMap() 这样的操作中 |
通过匿名内部类
见上篇笔记例程。
通过具名类传递
class ContainsError implements Function() {
public Boolean call(String x) { return x.contains("error"); }
}
...
RDD errors = lines.filter(new ContainsError());
- 使用具名类在程序组织比较庞大是显得比较清晰
- 可以使用构造函数如“通过带参数的 Java 函数类传递”中所示
通过带参数的 Java 函数类传递
例程
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import java.util.List;
public class Contains implements Function {
private String query;
public Contains(String query) {
this.query = query;
}
public Boolean call(String x) {
return x.contains(query);
}
public static void main(String[] args) {
SparkConf sc = new SparkConf().setAppName("Contains");
JavaSparkContext javaSparkContext = new JavaSparkContext(sc);
JavaRDD log = javaSparkContext.textFile(args[0]);
JavaRDD content = log.filter(new Contains(args[1]));
List contentList = content.collect();
for (String output : contentList) {
System.out.println(output);
}
javaSparkContext.stop();
}
} 测试文本 test.txt
this is a test
this is a simple test
this is a simple test about RDD
let us check it out测试结果
[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class Contains ~/RDDFuncNamedClass.jar ~/test.txt RDD
...
19/09/16 15:06:50 INFO DAGScheduler: Job 0 finished: collect at Contains.java:24, took 0.445049 s
this is a simple test about RDD
...通过 lambda 表达式传递(仅限于 Java 8 及以上)
例程
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.List;
public class LambdaTest {
public static void main(final String[] args) {
SparkConf sc = new SparkConf().setAppName("Contains");
JavaSparkContext javaSparkContext = new JavaSparkContext(sc);
JavaRDD log = javaSparkContext.textFile(args[0]);
JavaRDD content = log.filter(s -> s.contains(args[1]));
List contentList = content.collect();
for (String output : contentList) {
System.out.println(output);
}
javaSparkContext.stop();
}
} 测试文本
使用上文同一个文本
运行结果
[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class Contains ~/RDDFuncNamedClass.jar ~/test.txt check
...
19/09/16 15:27:10 INFO DAGScheduler: Job 0 finished: collect at Contains.java:24, took 0.440515 s
let us check it out
...常见的转化操作和行动操作
Spark 中有不同类型的 RDD,不同的 RDD 可以支持不同的操作。
除了基本的RDD外,还有数字类型的 RDD 支持统计型函数操作、键值对形式的 RDD 支持聚合数据的键值对操作等等。
基本RDD
针对各个元素的转化操作
为了方便,代码在 pyspark 中展示:
# map()
# map() 的返回值类型不需要和输入类型一样
>>> nums = sc.parallelize([1, 2, 3, 4])
>>> squared = nums.map(lambda x: x * x).collect()
>>> for num in squared:
... print "%i " % (num)
...
1
4
9
16
# flatMap()
# 给flatMap() 的函数被分别应用到了输入RDD 的每个元素上。
# 返回的是一个返回值序列的迭代器。
#
>>> lines = sc.parallelize(["hello world", "hi"])
>>> words = lines.flatMap(lambda line: line.split(" "))
>>> words.first()
'hello'map() 和 flatmap() 区别如下:

伪集合操作
RDD 不算是严格意义上的集合,但是一些类似集合的属性让它能够支持许多集合操作,下图展示了常见的集合操作:

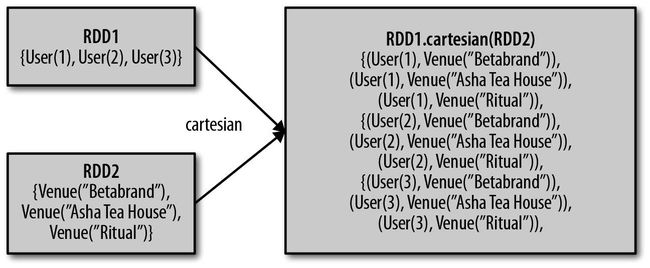
此外,RDD 还支持笛卡尔积的操作:
以下对基本 RDD 的转化操作进行梳理:
- 单个 RDD {1,2,3,3} 的转化操作
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| map() | 将函数应用于RDD 中的每个元 素,将返回值构成新的RDD |
rdd.map(x => x + 1) | {2, 3, 4, 4} |
| flatMap() | 将函数应用于RDD 中的每个元 素,将返回的迭代器的所有内 容构成新的RDD。通常用来切 分单词 |
rdd.flatMap(x => x.to(3)) | {1, 2, 3, 2, 3, 3, 3} |
| filter() | 返回一个由通过传给filter() 的函数的元素组成的RDD |
rdd.filter(x => x != 1) | {2, 3, 3} |
| distinct() | 去重 | rdd.distinct() | {1, 2, 3} |
| sample(withReplacement, fraction, [seed]) | 对RDD 采样,以及是否替换 | rdd.sample(false, 0.5) | 非确定的 |
- 两个 RDD {1,2,3},{3,4,5}的 RDD 的转化操作
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| union() | 生成一个包含两个RDD 中所有元 素的RDD |
rdd.union(other) | {1, 2, 3, 3, 4, 5} |
| intersection() | 求两个RDD 共同的元素的RDD | rdd.intersection(other) | {3} |
| subtract() | 移除一个RDD 中的内容(例如移 除训练数据) |
rdd.subtract(other) | {1, 2} |
| cartesian() | 与另一个RDD 的笛卡儿积 | rdd.cartesian(other) | {(1, 3), (1, 4), ... (3, 5)} |
行动操作
reduce() 与 reduceByKey()
例程1
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
public class SimpleReduce {
public static void main(String[] args) {
SparkConf sc = new SparkConf().setAppName("Contains");
JavaSparkContext javaSparkContext = new JavaSparkContext(sc);
List data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD originRDD = javaSparkContext.parallelize(data);
Integer sum = originRDD.reduce((a, b) -> a + b);
System.out.println(sum);
//reduceByKey,按照相同的key进行reduce操作
List list = Arrays.asList("key1", "key1", "key2", "key2", "key3");
JavaRDD stringRDD = javaSparkContext.parallelize(list);
//转为key-value形式
JavaPairRDD pairRDD = stringRDD.mapToPair(k -> new Tuple2<>(k, 1));
List list1 = pairRDD.reduceByKey((x, y) -> x + y).collect();
System.out.println(list1);
}
} 运行结果
...
19/09/17 17:08:37 INFO DAGScheduler: Job 0 finished: reduce at SimpleReduce.java:21, took 0.480038 s
15
...
19/09/17 17:08:38 INFO DAGScheduler: Job 1 finished: collect at SimpleReduce.java:29, took 0.237601 s
[(key3,1), (key1,2), (key2,2)]
...aggregate()2
例程
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
import java.io.Serializable;
import java.util.Arrays;
import java.util.List;
public class AvgCount implements Serializable {
private AvgCount(int total, int num) {
this.total = total;
this.num = num;
}
private int total;
private int num;
private double avg() {
return total / (double) num;
}
public static void main(String[] args) {
SparkConf sc = new SparkConf().setAppName("Contains");
JavaSparkContext javaSparkContext = new JavaSparkContext(sc);
List data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD rdd = javaSparkContext.parallelize(data);
AvgCount initial = new AvgCount(0, 0);
Function2 addAndCount =
new Function2() {
public AvgCount call(AvgCount a, Integer x) {
a.total += x;
a.num += 1;
return a;
}
};
Function2 combine =
new Function2() {
public AvgCount call(AvgCount a, AvgCount b) {
a.total += b.total;
a.num += b.num;
return a;
}
};
AvgCount result = rdd.aggregate(initial, addAndCount, combine);
System.out.println(result.avg());
}
} 运行结果
[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class AvgCount ~/Spark_RDD_Aggregate.jar
...
19/09/18 15:28:19 INFO DAGScheduler: Job 0 finished: aggregate at AvgCount.java:43, took 0.517385 s
3.0
...常用的行动操作整理
| 函数名 | 目的 | 示例 | 结果 |
|---|---|---|---|
| collect() | 返回RDD 中的所有元素 | rdd.collect() | {1, 2, 3, 3} |
| count() | RDD 中的元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在RDD 中出现的次数 | rdd.countByValue() | {(1, 1), (2, 1), (3, 2)} |
| take(num) | 从RDD 中返回num 个元素 | rdd.take(2) | {1, 2} |
| top(num) | 从RDD 中返回最前面的num 个元素 |
rdd.top(2) | {3, 3} |
| takeOrdered(num) (ordering) |
从RDD 中按照提供的顺序返 回最前面的num 个元素 |
rdd.takeOrdered(2)(myOrdering) | {3, 3} |
| takeSample(withReplace ment, num, [seed]) |
从RDD 中返回任意一些元素 | rdd.takeSample(false, 1) | 非确定的 |
| reduce(func) | 并行整合RDD 中所有数据 (例如sum) |
rdd.reduce((x, y) => x + y) | 9 |
| fold(zero)(func) | 和reduce() 一样, 但是需要 提供初始值 |
rdd.fold(0)((x, y) => x + y) | 9 |
| aggregate(zeroValue) (seqOp, combOp) |
和reduce() 相似, 但是通常 返回不同类型的函数 |
rdd.aggregate((0, 0)) ((x, y) => (x._1 + y, x._2 + 1), (x, y) => (x._1 + y._1, x._2 + y._2)) |
(9,4) |
| foreach(func) | 对RDD 中的每个元素使用给 定的函数 |
rdd.foreach(func) | 无 |
不同 RDD 的类型转换
Spark 中有些函数只能作用于特定类型的 RDD。例如 mean() 和 variance() 只能处理数值 RDD,join() 只能用于处理键值对 RDD。在 Scala 和 Java 中都没有与之对应的标准 RDD 类,故使用这些函数时必须要确保获得了正确的专用 RDD 类。(Scala 为隐式转换)
下表为 Java 中针对专门类型的函数接口:
| 函数名 | 等价函数 | 用途 |
|---|---|---|
| DoubleFlatMapFunction | Function |
用于flatMapToDouble,以 生成DoubleRDD |
| DoubleFunction | Function |
用于mapToDouble,以生成 DoubleRDD |
| PairFlatMapFunction |
Function |
用于flatMapToPair,以生 成PairRDD |
| PairFunction |
Function |
用于mapToPair, 以生成 PairRDD |
例程
以 DoubleFunction 为例:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaDoubleRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.DoubleFunction;
import java.util.Arrays;
public class DoubleRDD {
public static void main(String[] args) {
SparkConf sparkConf=new SparkConf().setAppName("DoubleRDD");
JavaSparkContext javaSparkContext=new JavaSparkContext(sparkConf);
JavaRDD rdd = javaSparkContext.parallelize(Arrays.asList(1, 2, 3, 4));
JavaDoubleRDD result = rdd.mapToDouble(
new DoubleFunction() {
public double call(Integer x) {
return (double) x * x;
}
});
System.out.println(result.mean());
}
} 运行结果
[root@server1 spark-2.4.4-bin-hadoop2.7]# bin/spark-submit --class DoubleRDD ~/Spark_RDD_DoubleRDD.jar
...
19/09/18 16:09:38 INFO DAGScheduler: Job 0 finished: mean at DoubleRDD.java:20, took 0.500705 s
7.5
...持久化
为了避免多次计算同一个 RDD,我们常常对数据进行持久化处理。具体操作可以参见上一节例程。
Tips:
- 在Scala 和Java 中,默认情况下 persist() 会把数据以序列化的形式缓存在JVM 的堆空间中
- 在Python 中,我们会始终序列化要持久化存储的数据,所以持久化级别默认值就是以序列化后的对象存储在JVM 堆空间中
- 当我们把数据写到磁盘或者堆外存储上时,也总是使用序列化后的数据
- 缓存的数据太多,内存中放不下,Spark 会自动利用最近最少使用(LRU)的缓存策略把最老的分区从内存中移除
- unpersist() 可以手动把持久化的RDD 从缓存中移除
持久化级别
| 级 别 | 使用的 空间 |
CPU 时间 |
是否在 内存中 |
是否在 磁盘上 |
备注 |
|---|---|---|---|---|---|
| MEMORY_ONLY | 高 | 低 | 是 | 否 | |
| MEMORY_ONLY_SER | 低 | 高 | 是 | 否 | |
| MEMORY_AND_DISK | 高 | 中等 | 部分 | 部分 | 如果数据在内存中放不下,则溢写到磁盘上 |
| MEMORY_AND_DISK_SER | 低 | 高 | 部分 | 部分 | 如果数据在内存中放不下,则溢写到磁盘上。在内存中存放序列化后的数据 |
| DISK_ONLY | 低 | 高 | 否 | 是 |
P.s.
可以通过在存储级别的末尾加上“_2”来把持久化数据存为两份
摘自天涯泪小武 的博客↩
fold() 和 reduce() 不同的是,需要再加上一个“初始值”来作为每个分区第一次调用时的结果;aggregate() 和 前两者不同的是,返回值类型可以和 RDD 的类型不一致↩