flink监控基于pushgateway+prometheus+grafana构建
先上一个架构图
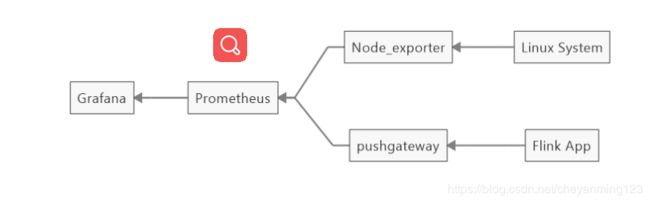
Flink App : 通过report 将数据发出去metric信息
Pushgateway : Prometheus 生态中一个重要工具
Prometheus : 一套开源的系统监控报警框架 (Prometheus 入门与实践)
Grafana: 一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知(可视化工具Grafana:简介及安装)
Node_exporter : 跟Pushgateway一样是Prometheus 的组件,采集到主机的运行指标如CPU, 内存,磁盘等信息
提要
本文主要介绍将flink任务运行的metric发送到Prometheus,通过grafana报表工具展示。
监控的意义
flink流式任务在实时性稳定性方面都有一定的要求,通过Prometheus 采集flink集群的metric,指定一些指标就可以对其进行监控告警。从而能够让开发人员快速反应,及时处理线上问题。
1.Prometheus 简介
Prometheus是一个开源的监控和报警系统。https://prometheus.io/docs/introduction/overview/
2.1特性
- 多维度的数据模型(通过指标名称和标签键值对标识)
- 灵活的查询语言
- 单机工作模式,不依赖于分布式存储
- 通过pull模式(HTTP)收集监控数据
- 通过使用中间件可以支持push监控数据到prometheus
- 通过服务发现或者静态配置发现目标(监控数据源)
- 支持多模式的画图和仪表盘
2.2组件
Prometheus生态系统包含很多组件(大多是都是可选择的)
-
Prometheus server(抓取、存储时间序列数据)
-
client libraries(帮助应用支持prometheus数据采集)
- a push gateway(支持短生命周期的jobs,接收push的监控数据)(prometheus原生支持pull工作模式,为了兼容push工作模式)
- exporters(用于支持开源服务的监控数据采集,比如:HAProxy、StatsD、Graphite等)(也就是agent)
-
alertmanager(处理警报)
2.3架构
下面这张图展示了prometheus的建构和prometheus系统可能需要到的组件:

image.png
3 flink集成prometheus
3.1 flink配置
详细配置参考
https://ci.apache.org/projects/flink/flink-docs-stable/monitoring/metrics.html#cpu
进入flink目录
拷贝 opt目录下的flink-metrics-prometheus-1.7.2.jar 到lib目录。
编辑conf/flink-conf.yml
metrics.reporter.promgateway.class: org.apache.flink.metrics.prometheus.PrometheusPushGatewayReporter
metrics.reporter.promgateway.host: test01.cdh6.local
metrics.reporter.promgateway.port: 9091
metrics.reporter.promgateway.jobName: myJob
metrics.reporter.promgateway.randomJobNameSuffix: true
metrics.reporter.promgateway.deleteOnShutdown: false
3.2 pushgateway安装
参考 https://github.com/prometheus/pushgateway
下载:https://prometheus.io/download/ wget https://github.com/prometheus/pushgateway/releases/download/v0.9.1/pushgateway-0.9.1.linux-amd64.tar.gz
解压:tar -zxvf pushgateway-0.9.1.linux-amd64.tar.gz
启动:./pushgateway &
访问 http://localhost:9091/#

3.3 node_exporter安装
下载:https://prometheus.io/download/ wget https://github.com/prometheus/node_exporter/releases/download/v0.18.1/node_exporter-0.18.1.linux-amd64.tar.gz
解压:tar -zxvf pushgateway-0.9.1.linux-amd64.tar.gz
启动:./node_exporter &
查看进程 netstat -apn | grep -E '9091|3000|9090|9100'
访问url:http://192.168.91.132:9100/metrics
效果如下:

这些都是收集到数据,有了它就可以做数据展示了
3.4 prometheus安装
参考 https://www.jianshu.com/p/3a9ede07d963
下载:wget https://github.com/prometheus/prometheus/releases/download/v2.12.0/prometheus-2.12.0.linux-amd64.tar.gz
本例prometheus和pushgateway安装到同一机器上
编写 prometheus.yml,注意:严格按照.yml文件的编写格式,每行要缩进,否则启动报错!!
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
labels:
instance: 'prometheus'
- job_name: 'linux'
static_configs:
- targets: ['localhost:9100']
labels:
instance: 'localhost'
- job_name: 'pushgateway'
static_configs:
- targets: ['localhost:9091']
labels:
instance: 'pushgateway'启动./prometheus --config.file=prometheus.yml
查看进程 netstat -apn | grep -E '9091|3000|9090|9100'
这个9091端口就是flink-conf.yml 对应的metrics.reporter.promgateway.port: 9091
flink会把一些metric push到9091端口上,然后prometheus采集。
查看 prometheus: ip:9090/targets

如果state 不是 UP 的,等一会就起来了
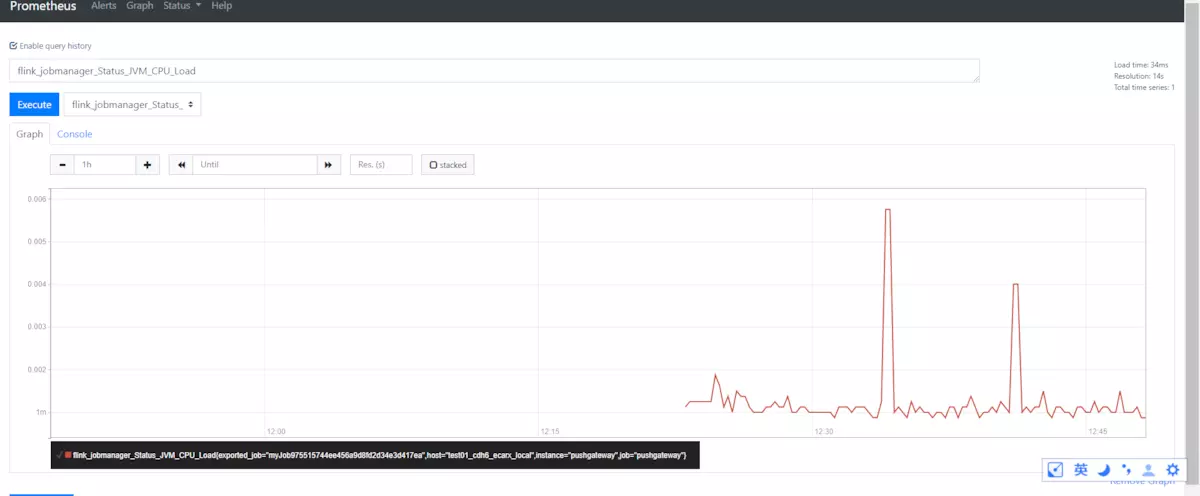
4效果
启动flink集群 .bin/start-cluster.sh
访问 http://localhost:9090
5.grafana安装
下载:wget https://dl.grafana.com/oss/release/grafana-6.3.6.linux-amd64.tar.gz
解压:tar -zxvf grafana-6.3.6.linux-amd64.tar.gz
启动:./bin/grafana-server web &
查看Grafana:

默认用户名密码 : amin/admin
此处不再赘述,配置数据源、创建系统负载监控参考博客:https://www.cnblogs.com/xiao987334176/p/9930517.html#autoid-0-0-0
5.1 启动一个Flink job :
flink run -m yarn-cluster -ynm LateDataProcess -yn 1 -c com.venn.stream.api.sideoutput.lateDataProcess.LateDataProcess jar/flinkDemo-1.0.jar查看任务webUI:
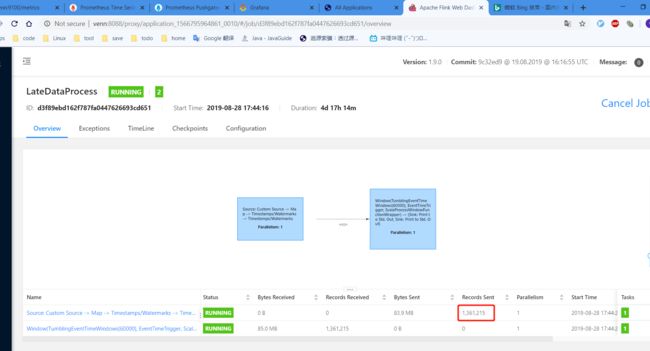
PS:任务已经跑了一段时间了
6、Grafana 中配置Flink监控
由于上面一句配置好Flink report、 pushgateway、prometheus,并且在Grafana中已经添加了prometheus 数据源,所以Grafana中会自动获取到 flink job的metrics 。
Grafana 首页,点击New dashboard,创建一个新的dashboard

选中之后,即会出现对应的监控指标

至此,Flink 的metrics 的指标展示在Grafana 中了
flink 指标对应的指标名比较长,可以在Legend 中配置显示内容,在{{key}} 将key换成对应需要展示的字段即可,如: {{job_name}},{{operator_name}}
对应显示如下:
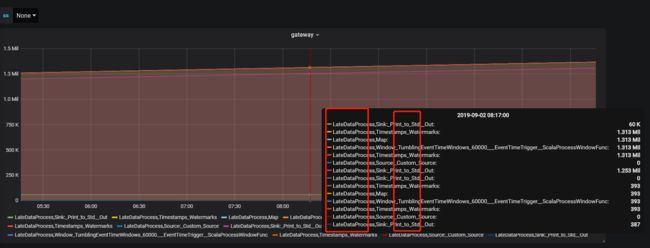
保存
总结
flink metric数据流转的流程是 flink metric -> pushgateway -> prometheus ->grafana