第四章:hadoop 启动wordcount实例,包括hadoop自带jar包和eclipsejar包。hdfs常用命令
1,首先介绍启动hadoop自带的wordcount的jar包实例
1.1启动hadoop
hadoop安装目录下:./sbin/start-all.sh
查看进程:jps

1.2 ,进入到home目录下,创建一个文本,随便写点东西

1.3 进入到hadoop安装目录下,模糊查找hadoop 案例jar包

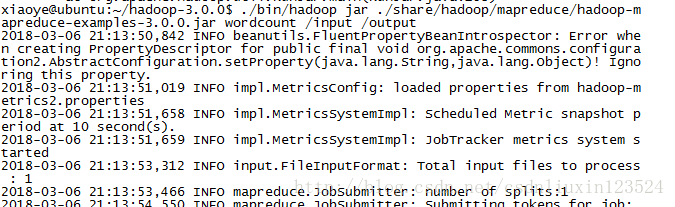
我们用hadoop-mapreduce-examples-3.0.0.jar
1.4 ./bin/hadoop fs -mkdir /input 在hdfs上创建一个目录,用来存放刚才创建的文档
1.5 ./bin/hadoop fs -put ../classes/aa.txt /input 将文档上传到hdfs上
1.6 ./bin/hadoop fs -ls /input 查看
1.7 ./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input /output
运行wordcount
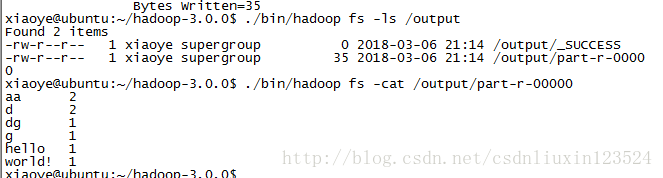
1.9 ./bin/hadoop fs -ls /output 查看出入文件目录
1.10 ./bin/hadoop fs -cat /output/part-r-00000 查看处理后的结果
整体截图如下:

2,在eclipse编写wordcount代码,打包放到hdfs上运行
案例下载地址:https://download.csdn.net/download/csdnliuxin123524/10276666
2.1,eclipse上创建maven工程(自行配置安装maven等)
创建好maven工程后,pom内容如下:
4.0.0
hadoop
wordCount
0.0.1-SNAPSHOT
apache
http://maven.apache.org
org.apache.hadoop
hadoop-core
1.2.1
org.apache.hadoop
hadoop-common
2.7.2
maven-dependency-plugin
false
true
./lib
这里读者只需要拷贝如下部分即可,其余的创建maven工程师会自动填好:
apache
http://maven.apache.org
org.apache.hadoop
hadoop-core
1.2.1
org.apache.hadoop
hadoop-common
2.7.2
maven-dependency-plugin
false
true
./lib
配置好后,maven update 会自动从网上拉取相应的jar包,当然别忘了设置maven的setting文件:
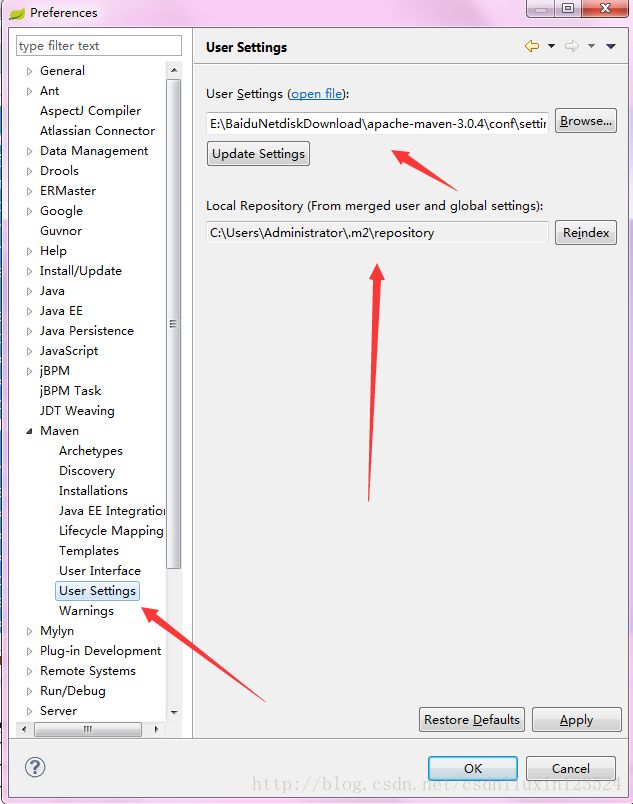
setting使用maven自带的就行了。
下面写三个雷,一个是map,一个reduce,一个是main:
整体如下:

mapper类:
package test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/*
* KEYIN:输入kv数据对中key的数据类型
* VALUEIN:输入kv数据对中value的数据类型
* KEYOUT:输出kv数据对中key的数据类型
* VALUEOUT:输出kv数据对中value的数据类型
*/
public class WordCountMapper extends Mapper{
/*
* map方法是提供给map task进程来调用的,map task进程是每读取一行文本来调用一次我们自定义的map方法
* map task在调用map方法时,传递的参数:
* 一行的起始偏移量LongWritable作为key
* 一行的文本内容Text作为value
*/
@Override
protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {
//拿到一行文本内容,转换成String 类型
String line = value.toString();
//将这行文本切分成单词
String[] words=line.split(" ");
//输出<单词,1>
for(String word:words){
context.write(new Text(word), new IntWritable(1));
}
}
} reduce类:
package test;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/*
* KEYIN:对应mapper阶段输出的key类型
* VALUEIN:对应mapper阶段输出的value类型
* KEYOUT:reduce处理完之后输出的结果kv对中key的类型
* VALUEOUT:reduce处理完之后输出的结果kv对中value的类型
*/
public class WordCountReducer extends Reducer{
@Override
/*
* reduce方法提供给reduce task进程来调用
*
* reduce task会将shuffle阶段分发过来的大量kv数据对进行聚合,聚合的机制是相同key的kv对聚合为一组
* 然后reduce task对每一组聚合kv调用一次我们自定义的reduce方法
* 比如:
* hello组会调用一次reduce方法进行处理,tom组也会调用一次reduce方法进行处理
* 调用时传递的参数:
* key:一组kv中的key
* values:一组kv中所有value的迭代器
*/
protected void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
//定义一个计数器
int count = 0;
//通过value这个迭代器,遍历这一组kv中所有的value,进行累加
for(IntWritable value:values){
count+=value.get();
}
//输出这个单词的统计结果
context.write(key, new IntWritable(count));
}
}
main类:
这里的输入与输出文件路径设置很重要:是主机名:core-site.xml中配置的端口
package test;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountJobSubmitter {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job wordCountJob = Job.getInstance(conf);
//重要:指定本job所在的jar包
wordCountJob.setJarByClass(WordCountJobSubmitter.class);
//设置wordCountJob所用的mapper逻辑类为哪个类
wordCountJob.setMapperClass(WordCountMapper.class);
//设置wordCountJob所用的reducer逻辑类为哪个类
wordCountJob.setReducerClass(WordCountReducer.class);
//设置map阶段输出的kv数据类型
wordCountJob.setMapOutputKeyClass(Text.class);
wordCountJob.setMapOutputValueClass(IntWritable.class);
//设置最终输出的kv数据类型
wordCountJob.setOutputKeyClass(Text.class);
wordCountJob.setOutputValueClass(IntWritable.class);
//设置要处理的文本数据所存放的路径
FileInputFormat.setInputPaths(wordCountJob, "hdfs://ubuntu:9000/input/aa.txt");
FileOutputFormat.setOutputPath(wordCountJob, new Path("hdfs://ubuntu:9000/output/"));
//提交job给hadoop集群
wordCountJob.waitForCompletion(true);
}
} 右键工程
maven update 确保不报错。
maven clean
maven uddate
maven install
经过这几步就能够自动生成jar包,如下:

把jar包拷到桌面上,并把包名改为wc.jar,方便上传,
2.2, eclipse准备好后,就开始虚拟机这边:
在用户的home目录下创建一个classes文件夹,用来存放上传的jar包:
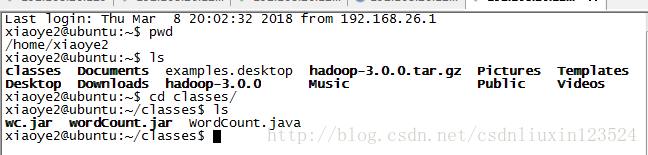
rz上传刚才的jar包
2.3,启动hadoop
启动之前我们先复习下,我们的hadoop配置,这里小编不同于上一篇博文,稍作了修改:
core-site.xml:
hadoop.tmp.dir
/home/xiaoye2/hadoop-3.0.0/tmp
fs.default.name
hdfs://192.168.26.129:9000
这里是IP:9000是hdfs的地址和端口
hdfs-site.xml
#
dfs.datanode.data.dir
/home/xiaoye2/hadoop-3.0.0/hadoop/data
dfs.namenode.name.dir
/home/xiaoye2/hadoop-3.0.0/hadoop/name
dfs.http.address
0.0.0.0:50030
这里就设置成0.0.0.0:50030,是浏览器上的hdfs的地址和端口
mapred-site.xml:
mapred.job.tracker
192.168.26.129:9001
mapred的ip和端口,不过目前还没有用到,小编也不清楚其用处
2.3配置主机名:
su root 切换成root用户
vim /etc/hosts
加入以下内容:
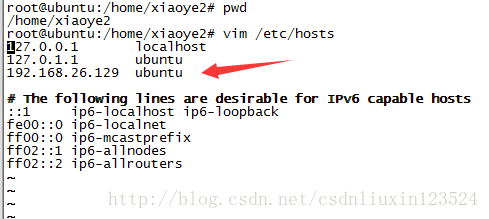
也就是把你的ip地址加进去,并对应现在的主机名。
2.4,配置好之后:格式化namenode
进入到hadoop目录,小编这里是hadoop-3.0.0:

./bin/hadoop namenode -format
再 ./sbin/start-all.sh 启动所有进程
jps查看进程是否全都开启,总共六个:

2.5,再hadoop-3.0.0目录下创建一个文本aa.txt,并随便写的内容,过会我们就分析这个文本的单词出现频率
2.5.1 , 再hdfs上创建一个input目录:./bin/hadoop fs -mkdir hdfs://ubuntu:9000/input/
将aa.txt文件上传到hdfs的input目录下./bin/hadoop fs -put aa.txt hdfs://ubuntu:9000/input/
运行wordcount程序:./bin/hadoop jar /home/xiaoye2/classes/wc.jar test.WordCountJobSubmitter /input
查看处理后的文件内容: ./bin/hadoop fs -cat hdfs://ubuntu:9000/output/part-r-00000
这样就大功告成了。
3遇到问题:
3.1:Host Details : local host is: "ubuntu/127.0.1.1"; destination host is: "ubuntu
这个问题困扰了我两天时间,搞到半夜2点钟都没解决。看报错原因是说本地主机与目标主机不一致。但是由于自学对这方面知识不懂,所以就就不断的试,终于通过以下方法解决了。首先修改/etc/hosts文件,为其加上虚拟机的ip 和对应的主机名,上面有介绍,可往上翻看。再者修改core-site.xml文件的localhost为虚拟机ip。同理mapred-site.xml也是。再修改hdfs的访问ip为0.0.0.最后重新启动hdfs。
3.2:要会看日志:比如说datanode或namenode没有起来,那么就要看hadoop目录下的logs对应的日志,比如namenode没有起来,实时查看namenode的日志:tail -f -n200 hadoop-xiaoye2-namenode-ubuntu.log 看报什么错再针对解决。
3.3,常用hdfs命令:当然实际使用中 要稍作修改,比如小编的查看hdfs的文件命令就是:
./bin/hadoop fs -ls hdfs://ubuntu:9000/input/1、-help[cmd] 显示命令的帮助信息
./hdfs dfs -help ls- 1
2、-ls(r) 显示当前目录下的所有文件 -R层层循出文件夹
./hdfs dfs -ls /log/map
./hdfs dfs -ls -r /log/ (递归的)- 1
- 2
3、-du(s) 显示目录中所有文件大小,或者当只指定一个文件时,显示此文件的大小
./hdfs dfs -du /user/hadoop/dir1 /user/hadoop/file1 hdfs://host:port/user/hadoop/dir1- 1
4、-count[-q] 显示当前目录下的所有文件大小
5、-mv 移动多个文件目录到目标目录
./hdfs dfs -mv /user/hadoop/file1 /user/hadoop/file2- 1
6、-cp 复制多个文件到目标目录
./hdfs dfs -cp /user/hadoop/file1 /user/hadoop/file2 (将文件从源路径复制到目标路径。
这个命令允许有多个源路径,此时目标路径必须是一个目录。)- 1
- 2
7、-rm(r) 删除文件(夹)
./hdfs dfs -rm -r /log/map1 (递归删除)- 1
8、-put 本地文件复制到hdfs
./hdfs dfs -put test.txt /log/map/- 1
9、-copyFromLocal 本地文件复制到hdfs
./hdfs dfs -copyFromLOcal /usr/data/text.txt /log/map1/ (将本地的text.txt 复制到hdfs的/log/map1/下)- 1
10、-moveFromLocal 本地文件移动到hdfs
./hdfs dfs -moveFromLocal /usr/data/text.txt /log/map1/ (将本地的text.txt移动到hdfs的/log/map1/下)- 1
11、-get[-ignoreCrc] 复制文件到本地,可以忽略crc校验
./hdfs dfs -get /log/map1/* . (复制到本地当前目录下)
/hdfs dfs -get /log/map1/* /usr/data (将hdfs下的/log/map1/下的所有文件全部复制到本地的/usr/data/下 )- 1
- 2
12、-getmerge[addnl] 将源目录中的所有文件排序合并到一个文件中,接受一个源目录和一个目标文件作为输入,并且将源目录中所有的文件连接成本地目标文件。addnl是可选的,用于指定在每个文件结尾添加一个换行符。
./hdfs dfs -getmerge /log/map1/* /usr/data(将hdfs上的/log/map1/下的所有文件合并下载到本地的/usr/data下)- 1
13、-cat 在终端显示文件内容
./hdfs dfs -cat /log/map1/part-00000 | head (读取hdfs上的/log/map1下的part-00000文件 head参数,代表前十行。)
/hdfs dfs -tail /log/map1/part-00000 (查看文件的最后一千行)- 1
- 2
- 3
14、-text 在终端显示文件内容,将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream
15、-copyToLocal[-ignoreCrc] 复制文件到本地
16、-moveToLocal 移动文件到本地
17、-mkdir 创建文件夹 后跟-p 可以创建不存在的父路径
./hdfs dfs -mkdir -p /dir1/dir11/dir111 - 1
18、-touchz 创建一个空文件
19、-grep 从hdfs上过滤包含某个字符的行内容
./hdfs dfs -cat /log/testlog/* | grep 过滤字段