介绍
Tesseract是一个基于Apache2.0协议开源的跨平台ocr引擎,支持多种语言的识别,在Windows和Linux上都有良好的支持.
创建工程
创建一个C#的控制台工程
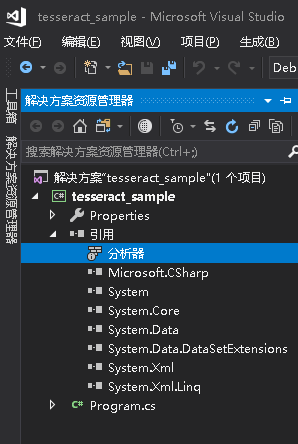
添加System.Drawing引用
因为在操作过程中我们会需要读取图片,所以这里需要这个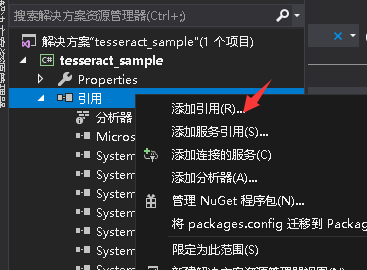
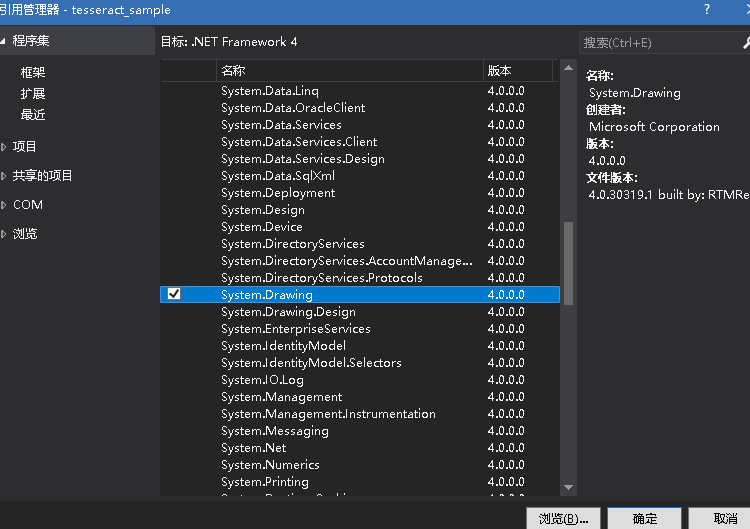
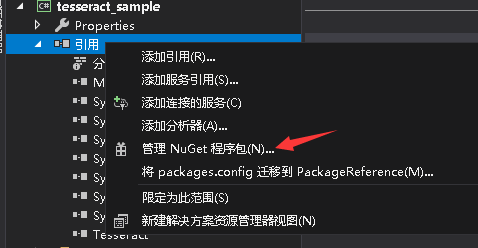
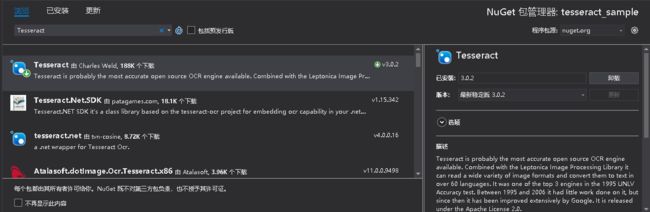
nuget里添加Tesseract引用
准备资源
这里共4个文件,2个目录
首先下载这个eng.traineddata
度盘下载 密码: 5xfs
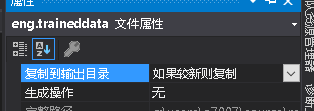
在工程目录里,建立一个tessdata文件夹(切记:文件夹一定要叫这名字!)放进去,文件属性设置"如果较新则复制"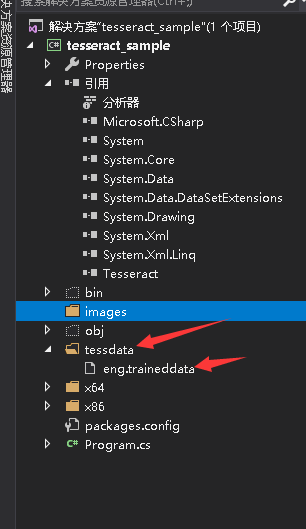
另外建立个images,放以下3张测试图片(你可以直接在这右键下载):
1.png
![]()
2.png
![]()
3.png
![]()
如果你在VS里看不到这3张图,那么你可能需要把它们添加到项目里: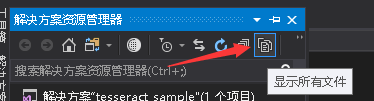
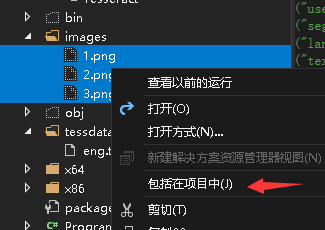
记得把3张图片设为"如果较新则复制"
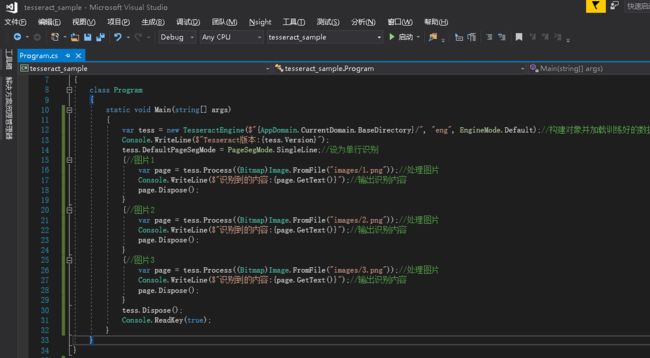
编辑代码
using引用:
using System;
using System.Drawing;
using Tesseract;Main:
static void Main(string[] args)
{
var tess = new TesseractEngine($"{AppDomain.CurrentDomain.BaseDirectory}/", "eng", EngineMode.Default);//构建对象并加载训练好的数据
Console.WriteLine($"Tesseract版本:{tess.Version}");
tess.DefaultPageSegMode = PageSegMode.SingleLine;//设为单行识别
{//图片1
var page = tess.Process((Bitmap)Image.FromFile("images/1.png"));//处理图片
Console.WriteLine($"识别到的内容:{page.GetText()}");//输出识别内容
page.Dispose();
}
{//图片2
var page = tess.Process((Bitmap)Image.FromFile("images/2.png"));//处理图片
Console.WriteLine($"识别到的内容:{page.GetText()}");//输出识别内容
page.Dispose();
}
{//图片3
var page = tess.Process((Bitmap)Image.FromFile("images/3.png"));//处理图片
Console.WriteLine($"识别到的内容:{page.GetText()}");//输出识别内容
page.Dispose();
}
tess.Dispose();
Console.ReadKey(true);
}
运行试试
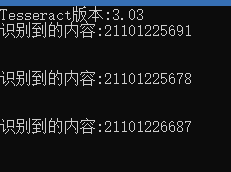
结束
可以看到大部分字符都是能够识别的,不过有个别数字识别错误了,我们需要训练自己的数据来提高正确率.
关于如何训练,可参考我的另一篇文章:
https://www.cnblogs.com/DragonStart/p/9418053.html
另外我把文中的例子发布到了gitee,可以从这里获取到整个工程:
https://gitee.com/o70078/tesseract_sample.git