ODPS系列(1):初识ODPS
注:MaxCompute,原名ODPS,出于使用习惯考虑,以下用ODPS代指MaxCompute,即阿里巴巴大数据计算服务。
一、为什么选择ODPS?
1.选择Apache Hadoop?
以Hadoop为代表的开源组件,搭建及维护的成本较高,遇见各类配置、网络、参数问题较多,升级时存在不兼容风险,需要单独搭建额外组件(如HBase),Namenode无法得安全性保障,需要较长时间来熟悉和维护。
2.选择Cloudera CDH?
以Cloudera为代表的集成组件,在使用的便捷性上提升了许多,版本及配置简化了很多,但配置参数、任务优化、日常运维仍需比较专业的人员来操作,一些配套平台(如任务调度)仍需自行搭建,属于软件层面上的优化提升,没有深入到硬件层面。
3选择ODPS?
ODPS最大的优势,就是通过阿里巴巴内部复杂多元的业务场景,将大数据计算的整个流程做了完整的梳理,各个环节的组件进行了统一梳理,实现了从日志采集、数据计算、数据展示到数据分析的全过程集成。在知晓了计算流程的前提下,可以针对硬件做专门的定制,因而实现了“减费增效”,即降低采购成本(如服务器数量)、人力成本(如运维)、时间成本(扩展方便)的同时,提升了计算规模(TB至EB级别)。
二、开发人员如何认识ODPS?
1.我要学原理?
如果要学习Hadoop系列的相关原理,单纯的学习ODPS其实意义不大,从技术学习的角度来看,开源一直都是程序员最好的老师,哪怕是《Hadoop权威指南》,笔者也认为不如直接上手搭建一个小型平台,并且阅读英文原版的文档。这里要讲一个道理,学历从来不是个人差距的主要因素,持续性的学习状态才是。从事程序员这种岗位,受限于中国的发展阶段,因而绝大多数的第一手资料都是英文的,学习好英语,其实是第一重要的,对于计算机的兴趣只能排到第二位。前些年我们经常说,互联网不歧视学历,有这样那样的漏洞可以钻一下,但这并不是因为互联网要求的门槛低,而是处在行业爆发期中,人才不足的一种体现。现在我们又提:互联网寒冬,似乎工作更难找了,但其实技术出众的人才依旧是难寻的,不能够持续学习的程序员将在行业漫长的发展过程中,逐步被淘汰。多学英文、多读英文资料,是保持自我技术能力的一种重要途径。
2.我要学技术?
从业务的角度看,技术是一种呈现不断融合的趋势,实践和动手是第一老师。正如看源码多了不一定能设计出好的系统,而使用集成好的平台,虽然开始是一种一知半解的状态,但胜在易于上手,能够快速建立起自信心。举个例子:学习Java没有人一上来就是手撕JVM,而是从“Hello World”写起来。刚开始使用ODPS,使用已集成好的平台,可以快速建立起对于大数据计算的基本认知和初始兴趣,再去拆解每一部分这么做的理由,最后深入到源码,这是比较符合学习过程的。
三、ODPS应该如何学习?
1.搭建一个类似于“Hello World”的例子
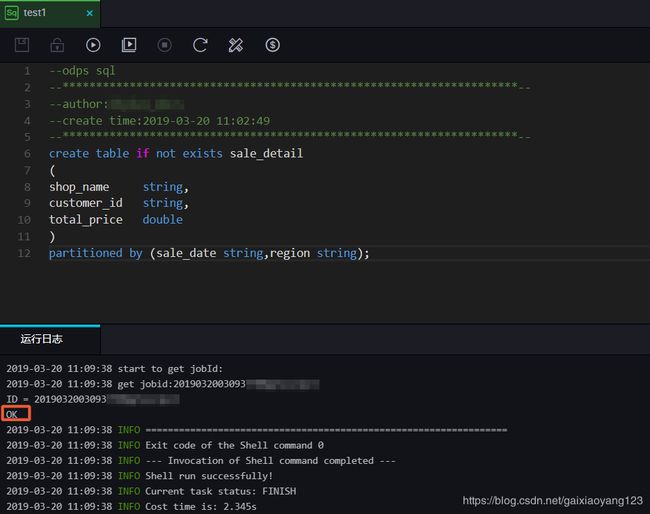
ODPS提供临时性的查询工具:
2.熟悉ODPS SQL
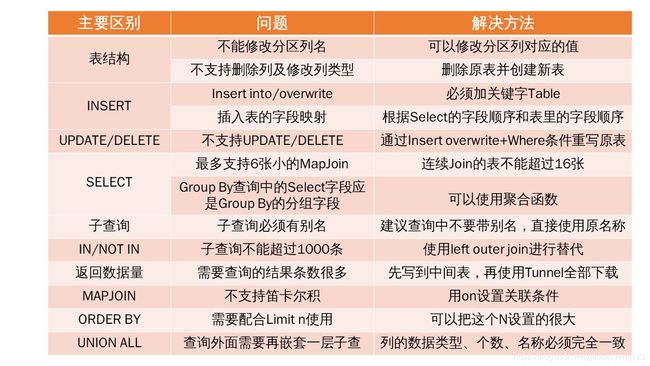
与大多数的类SQL相同,ODPS SQL也是ANSI SQL92的一个子集,并且加入了一定的扩展。要注意的是,ODPS SQL并不支持事务、主键约束、索引等数据库特征,且支持最大SQL长度为2MB。具体差异如下图所示
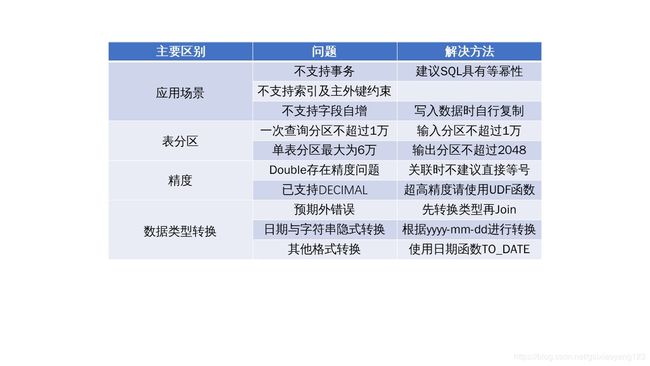
DDL与DML的区别及解法:
3.熟悉配套工具DataWorks
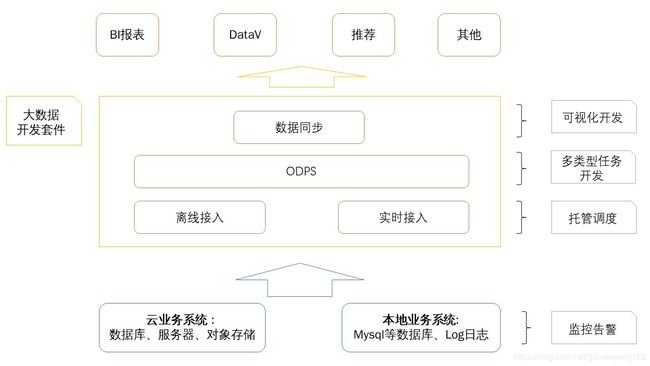
逐步学习使用相关的开发平台。DataWorks的作用是什么?官方的解释是,包含了数据集成、数据开发、数据地图、数据质量和数据服务等全方位的产品服务,并提供一站式开发管理的界面。以下是最原始的直观认知图:
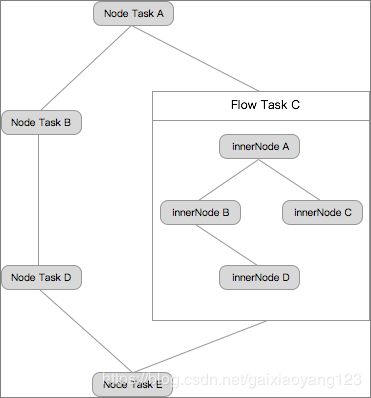
DataWorks中最重要的是需要理解任务的概念,任务是对数据执行的操作的定义,包括数据同步任务及数据计算任务,分为节点任务(node task)、工作流任务(flow task)和内部节点(inner node)三个部分。具体流程如下图所示:
三种任务的概念解释:
(1)节点任务(node task),一个数据执行的操作。可以与其他节点任务、工作流任务配置依赖关系,组成DAG图;
(2)工作流任务(flow task),满足一个业务场景需求的一组内部节点,组成一个工作流任务。工作流任务内部节点,无法被其它工作流任务、节点任务依赖。工作流任务可以与其它工作流任务、节点任务配置依赖关系,组成DAG图。
(3)内部节点(inner node):工作流任务内部的节点,与节点任务的功能基本一致。您可以通过拖拽形成依赖关系,其调度周期会继承工作流任务的调度周期,无法进行单独配置。
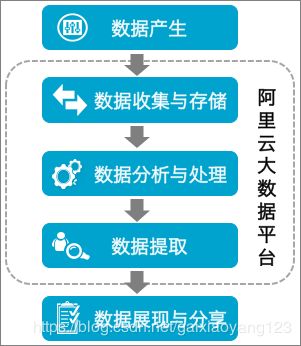
DataWorks中数据开发流程如下图所示:
4.为自己准备一个数据仓库的开发模板
一次开发任务的过程如下:
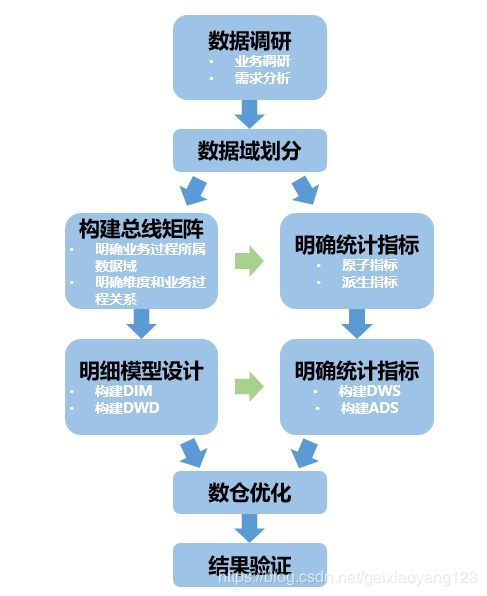
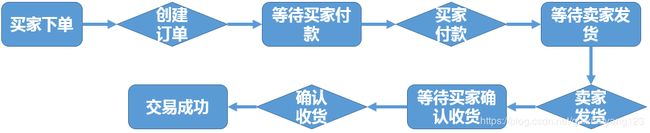
在这里,首先要学习数据调研的过程,并分析业务过程。例如以电商行业为例,一次完整的交易流程,我们可以划分成如下图所示的过程:
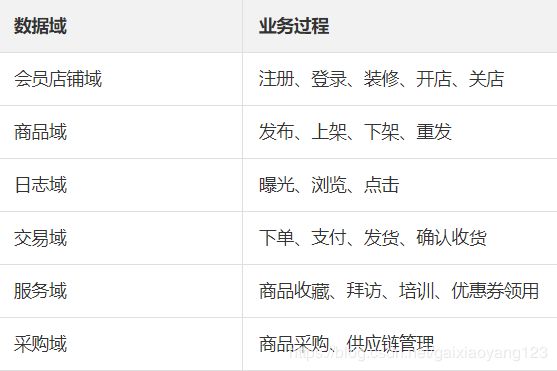
有了交易的过程,我们就可以划分如下的数据域,将过程中的各个环节进行抽象和聚合:
接着,我们假设需要将各个数据域的数据进行分别统计和展示,就需要有一定的设计方法论。这里建议采用阿里的数据层次划分方法论:
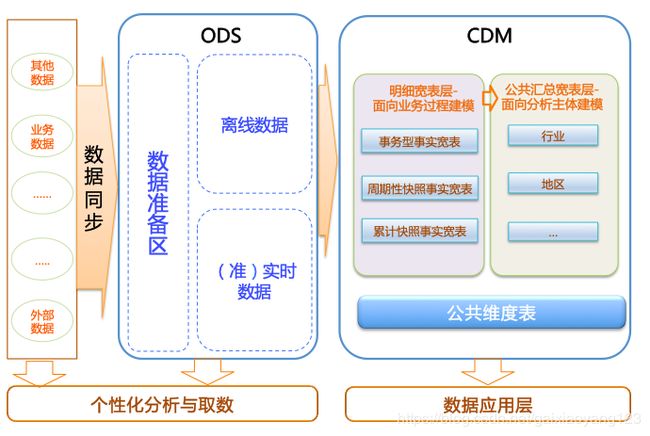
(1)ODS:操作数据层,包括原始数据的增量部分或者全量部分,相当于一个数据准备区,承担着基础数据的记录以及历史变化;
(2)CDM:公共维度模型层,又细分为DWD和DWS。主要作用是完成数据加工与整合、建立一致性的维度、构建可复用的面向分析和统计的明细事实表以及汇总公共粒度的指标。
(3)ADS:应用数据层,主要用于分类和展示已计算好的数据。
具体仓库的分层情况需要结合业务场景、数据场景、系统场景进行综合考虑:
最后,我们需要验证数据是否准确。
5.在实践中熟悉相关命令
任何开发都不是简单的随意撰写,都需要在满足一定规范的基础上进行:
