oracle 并行原理
先来看看oralce官方文档的解释吧
Parallel execution enables the application of multiple CPU and I/O resources to the execution of a single database operation. It dramatically reduces response time for data-intensive operations on large databases typically associated with a decision support system (DSS) and data warehouses. You can also implement parallel execution on an online transaction processing (OLTP) system for batch processing or schema maintenance operations such as index creation. Parallel execution is sometimes called parallelism. Parallelism is the idea of breaking down a task so that, instead of one process doing all of the work in a query, many processes do part of the work at the same time.An example of this is when four processes combine to calculate the total sales for a year, each process handles one quarter of the year instead of a single process handling all four quarters by itself. The improvement in performance can be quite significant. Parallel execution improves processing for:
Queries requiring large table scans, joins, or partitioned index scans
Creation of large indexes
Creation of large tables (including materialized views)
Bulk insertions, updates, merges, and deletions
解释一下吧,并行执行就是使用多个cpu和I/O资源去完成一个数据库操作,看打标记的那句话,并行是将一个任务打碎,让很多进程去执行原来应该有一个进程完成的动作。使用并行操作可以减少响应时间,但是这个和你的系统资源息息相关,如果系统资源缺乏,是用并行效果会跟差,并且增加资源的消耗。
oracle并行执行的机制
当cbo判断一个会话的使用了并行,oracle会将server process 转换为一个并行协调进程,Oracle启动时候,oracle使用默认参数parallel_min_servers来确定预先创建的slave process数,如果需要的slave process超出了oracle刚开始的创建的process,则并行协调进程将创建额外的slave process。然后并行协调进程将要处理的对象打碎,分给slave process处理,处理完成之后再汇总给server process,由server process将数据进行处理并返回给客户。
我们来看一个图:如图1

Oracle 使用了并行度为2来执行图中的sql,那么oracle使用了两个slave process p1,p2 来扫描customer这张表,扫描完成后,Oracle又启动了两个进程p3,p4,然后p1,p2 进程将扫描的数据分别传到对应的p3,p4进程中,由p3,p4进程执行group by操作。执行完成以后p3,p4进程,将数据送到p1,p2进程(因为扫描完数据后,p1,p2进程已经空闲,所以oracle没有启动新的进程),然后进行order by操作,最后将数据送到协调进程返回给用户。
前面就是一个并行执行的典型例子,但是并行进程之间的交互是怎么进行的了,oracle官方文档中是如下描述的:
To execute a query in parallel, Oracle Database generally creates a set of producer parallel execution servers and a set of consumer parallel execution servers. The producer server retrieves rows from tables and the consumer server performs operations such as join, sort, DML, and DDL on these rows. Each server in the producer set has a connection to each server in the consumer set. The number of virtual connections between parallel execution servers increases as the square of the degree of parallelism.
Each communication channel has at least one, and sometimes up to four memory buffers, which are allocated from the shared pool. Multiple memory buffers facilitateasynchronous communication among the parallel execution servers.
A single-instance environment uses at most three buffers for each communication channel. An Oracle Real Application Clusters environment uses at most four buffers for each channel.Figure 8-3illustrates message buffers and how producer parallel execution servers connect to consumer parallel execution servers.
Figure 8-3 Parallel Execution Server Connections and Buffers

When a connection is between two processes on the same instance, the servers communicate by passing the buffers back and forth in memory (in the shared pool). When the connection is between processes in different instances, the messages are sent using external high-speed network protocols over the interconnect. InFigure 8-3, the DOP equals the number of parallel execution servers, which in this case is n.Figure 8-3does not show the parallel execution coordinator. Each parallel execution server actually has an additional connection to the parallel execution coordinator. It is important to size the shared pool adequately when using parallel execution. If there is not enough free space in the shared pool to allocate the necessary memory buffers for a parallel server, it fails to start.
读懂并行执行计划
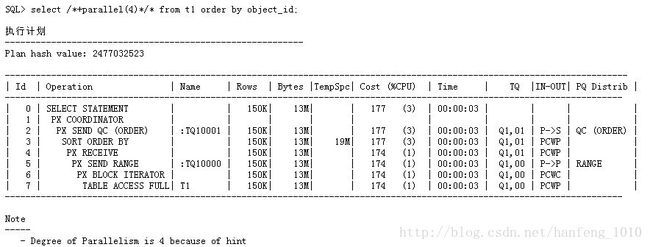
先来看operation这一行,可以看到出现了PX,表示Oracle使用了并行了。根据执行计划的读法以及上面了解的并行的执行过程,可以对执行计划做如下解读:
1. 首先对t1表进行了全表扫描,但是此时不是一个进程进行扫描的,PX BLOCK ITERATOR表示slave process以迭代的方式扫描数据块。
2. 接下来执行PX SEND RANGE ,表示oracle将扫描的结果推送到下一组进程。
3. 接下来oracle下一组进程开始接受数据(PX RECEIVE),并且并行进行排序。
4. 然后oracle将排序好的数据send到server process(PX SEND QC (ORDER)),然后server process 将数据返回给用户。
那么我们在解释以下in-out这一列的意思:
P->S (Parallel to Serial):表示一个并行操作发送数据给一个串行操作,通常是并行incheng将数据发送给并行调度进程。
P->P (Parallel to Parallel):表示一个并行操作向另一个并行操作发送数据,比如两个从属进程之间的数据交流.。
PCWP (Parallel Combined with parent):相同slave process并行执行一个操作及其父操作,无通讯。
PCWC (Parallel Combined with Child) :相同slave process并行执行一个操作及其子操作,无通讯。
这个地方PCWC和PCWP比较难理解,对着执行计划理解一下:
PCWC :TABLEACCESSFULL是PX BLOCK ITERATOR 的子进程,所以这个表示这两个操作是相同process完成的。
PCWPPX RECEIVE 是SORTORDERBY 的父进程 ,所以这个表示这两个操作是相同process完成的。
这个是个人的理解,有什么不对的,请指点。
接下来来看看如何在进程分发数据的方式:
range:生产者将执定范围的记录发给不同的消费者,会应用动态范围分区决定哪条记录给哪个消费者(对于orde by操作根据order by子句中字段range分区)。
loop:记录会被平均分给每个消费者(即生产者每loop一次给一个消费者发一条记录)。
hash:生产者用hash函数发送数据给消费者,动态应用hash分区来决定哪条记录给哪个消费者(对于group by根据group by子句使用的字段进行hash )。
qc随机:每个生产者将所有记录发给query coordinator(随机),这是常用方法。
qc顺序:每个生产者将所有记录发给query coordinator(顺序很重要),并行orderby用这个给query coordinator(server process)发送数据。
oracle 11g中和并行有关的初始化参数
PARALLEL_ADAPTIVE_MULTI_USER:默认值true,根据oracle的负载情况来动态调整sql的并行度。
PARALLEL_DEGREE_LIMIT:默认值 CPU_COUNTXPARALLEL_THREADS_PER_CPUX number of instances available,当oracle使用了自动调整并行度,则它表示oracle能使用的最大并行度。
PARALLEL_DEGREE_POLICY:默认值MANUAL,oracle使用该参数来启动自动调整并行度。
PARALLEL_EXECUTION_MESSAGE_SIZE:默认值16 KB。Specifies the size of the buffers used by the parallel execution servers to communicate among themselves and with the query coordinator. These buffers are allocated out of the shared pool.
PARALLEL_MAX_SERVERS:oracle 11g下默认是80个,这个参数定义了oracle所能使用的最大并行进程,当数据库实例启动的进程不够时,Oracle能够启动的最大进程数不能超过这个数目。
PARALLEL_MIN_SERVERS:默认值为0,这个参数定义了oracle实例启动时,启动的并行进程的数目。
当然还有一些其它的参数,请查看oracle官方文档,下面是我本地数据库一个默认参数的配置:
SQL> show parameter parallel
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
fast_start_parallel_rollback string LOW
parallel_adaptive_multi_user boolean TRUE
parallel_automatic_tuning boolean FALSE
parallel_degree_limit string CPU
parallel_degree_policy string MANUAL
parallel_execution_message_size integer 16384
parallel_force_local boolean FALSE
parallel_instance_group string
parallel_io_cap_enabled boolean FALSE
parallel_max_servers integer 80
parallel_min_percent integer 0
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
parallel_min_servers integer 0
parallel_min_time_threshold string AUTO
parallel_server boolean FALSE
parallel_server_instances integer 1
parallel_servers_target integer 32
parallel_threads_per_cpu integer 2
recovery_parallelism integer 0
这里重点了解一下一个Oracle 11g新增的参数PARALLEL_DEGREE_POLICY,让oracle可以自动根据系统资源来调整Oracle的并行度。
这个参数有三个值: limited,auto,MANUAL
我们先来做以下操作:
SQL> create table t1 as select * from dba_objects;
表已创建。
SQL> create table t2 as select * from dba_objects;
表已创建。
SQL> alter table t1 parallel 4;
表已更改。
SQL> alter table t2 parallel(degree default);
表已更改。
SQL> select table_name,degree from user_tables where table_name in('T1','T2');
TABLE_NAME DEGREE
------------------------------ --------------------
T1 4
T2 DEFAULT
SQL> select count(*) from t1;
COUNT(*)
----------
75446
SQL> select * from v$pq_sesstat where statistic='Allocation Height';
STATISTIC LAST_QUERY SESSION_TOTAL
------------------------------ ---------- -------------
Allocation Height 4 0
SQL> select count(*) from t2;
COUNT(*)
----------
75447
SQL> select * from v$pq_sesstat where statistic='Allocation Height';
STATISTIC LAST_QUERY SESSION_TOTAL
------------------------------ ---------- -------------
Allocation Height 8 0
可以看到,当使用默认值的时候 ,oracle 不会去自动的调整并行度,完全是按照用户的设置的并行度去处理的。
那么当参数值为limited时,Oracle又会如何处理了
SQL> alter session set parallel_degree_policy=limited;
会话已更改。
SQL> select count(*) from t1;
COUNT(*)
----------
75446
SQL> select * from v$pq_sesstat where statistic='Allocation Height';
STATISTIC LAST_QUERY SESSION_TOTAL
------------------------------ ---------- -------------
Allocation Height 4 0
SQL> select count(*) from t2;
COUNT(*)
----------
75447
SQL> select * from v$pq_sesstat where statistic='Allocation Height';
STATISTIC LAST_QUERY SESSION_TOTAL
------------------------------ ---------- -------------
Allocation Height 0 0
可以看到,当为limited的时候oracle会对并行度为default的进行调整,但是对已经设定好的不会调整,那么现在我们就可以猜到,auto肯定是会对两个都调整了。看下面,oracle会对所有的都会调整。
SQL> alter session set parallel_degree_policy=auto;
会话已更改。
SQL> select count(*) from t1;
COUNT(*)
----------
75446
SQL> select * from v$pq_sesstat where statistic='Allocation Height';
STATISTIC LAST_QUERY SESSION_TOTAL
------------------------------ ---------- -------------
Allocation Height 0 0
SQL> select count(*) from t2;
COUNT(*)
----------
75447
SQL> select * from v$pq_sesstat where statistic='Allocation Height';
STATISTIC LAST_QUERY SESSION_TOTAL
------------------------------ ---------- -------------
Allocation Height 0 0
可以使用并行执行的操作
Access methods:Some examples are table scans, index fast full scans, and partitioned index range scans.
Join methods:Some examples are nested loop, sort merge, hash, and star transformation.
DDL statements:
Some examples are CREATE TABLE AS SELECT,CREATE INDEX,REBUILD INDEX,REBUILD INDEX PARTITION, and MOVE/SPLIT/COALESCEP ARTITION.
You can typically use parallel DDL where you use regular DDL. There are, however, some additional details to consider when designing your database.One important restriction is that parallel DDL cannot be used on tables with object or LOB columns.(注意这一点,并行不能被使用在object或者lob字段上)
All of these DDL operations can be performed inNOLOGGINGmode for either parallel or serial execution.
TheCREATETABLEstatement for an index-organized table can be run with parallel execution either with or without anAS SELECT clause.
Different parallelism is used for different operations. Parallel CREATE (partitioned) TABLE ASS ELECT and parallel CREATE (partitioned) INDEX statements run with a degree of parallelism (DOP) equal to the number of partitions.(关于这一点我们会单独去做一下)。
DML statements:
Parallel query:
Miscellaneous SQL operations:
Some examples are GROUP BY,NOT IN,SELECT DISTINCT,UNION,UNION ALL,CUBE, and ROLLUP, plus aggregate and table functions.
SQL*Loader
并行查询:
一个查询能够并行执行,需要满足以下条件:
SQL 语句中有 Hint 提示,比如 parallell 或者 PARALLEL_INDEX 。
SQL 语句中引用的对象被设置了并行属性。
多表关联中 , 至少有一个表执行全表扫描 ( full table scan ) 或者跨越分区的 INDEX RANGE SACN 。
并行ddl:
并行DDL依赖于直接路径操作。也就是说,数据不传递到缓冲区缓存以便以后写出;而是由一个操作(如CREATE TABLE AS SELECT)来创建新的区段,并直接写入这些区段,数据直接从查询写到磁盘(放在这些新分配的区段中)。所以并行在表空间中容易造成空间碎片,在字典管理时代,会造成空间浪费。但是在本地表空间的管理中,两种不同的区分配方式会有不同的结果,相对并行来说,oracle更倾向与使用自动区分配。
以下ddl可以使用并行执行
CREATE INDEX
CREATE TABLE ... AS SELECT
ALTER INDEX ... REBUILD
ALTER TABLE ... [MOVE|SPLIT|COALESCE] PARTITION
ALTER INDEX ... [REBUILD|SPLIT] PARTITION
SQL> create index idx_tt1 on t1(object_id) parallel 4;
索引已创建。
SQL ID: aq91k6zr8au5q
Plan Hash: 1439620960
create index idx_tt1 on t1(object_id) parallel 4
call count cpu elapsed disk query current rows
------- ------ -------- ---------- ---------- ---------- ---------- ----------
Parse 1 0.01 0.34 2 21 0 0
Execute 1 0.01 1.46 23 9 1044 0
Fetch 0 0.00 0.00 0 0 0 0
------- ------ -------- ---------- ---------- ---------- ---------- ----------
total 2 0.03 1.81 25 30 1044 0
Misses in library cache during parse: 1
Optimizer mode: ALL_ROWS
Parsing user id: 84
Rows Row Source Operation
------- ---------------------------------------------------
4 PX COORDINATOR (cr=5 pr=0 pw=0 time=51 us)
0 PX SEND QC (ORDER) :TQ10001 (cr=0 pr=0 pw=0 time=0 us)
0 INDEX BUILD NON UNIQUE IDX_TT1 (cr=0 pr=0 pw=0 time=0 us)(object id 0)
0 SORT CREATE INDEX (cr=0 pr=0 pw=0 time=0 us)
0 PX RECEIVE (cr=0 pr=0 pw=0 time=0 us cost=83 size=1165905 card=89685)
0 PX SEND RANGE :TQ10000 (cr=0 pr=0 pw=0 time=0 us cost=83 size=1165905 card=89685)
0 PX BLOCK ITERATOR (cr=0 pr=0 pw=0 time=0 us cost=83 size=1165905 card=89685)
0 TABLE ACCESS FULL T1 (cr=0 pr=0 pw=0 time=0 us cost=83 size=1165905 card=89685)
ctas使用并行:
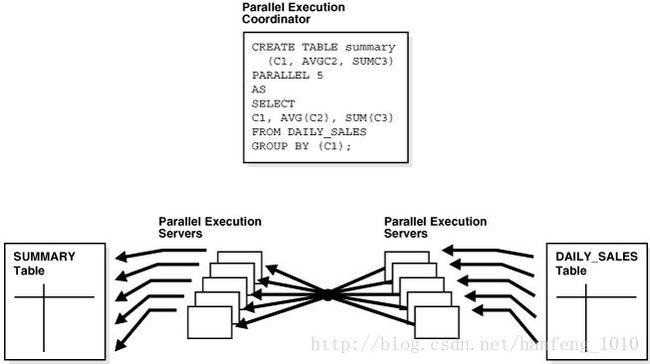
上面这个例子是Oracle官方文档提供的,oracle先去并行扫描源表,然后再去并行的创建目标表。
并行dml
要是并行dml必须显式的指定:
SQL> alter session enable parallel dml;
会话已更改。对于这个oracle官方文档做了如下的解释:
This mode is required because parallel DML and serial DML have different locking, transaction, and disk space requirements and parallel DML is disabled for a session by default.