【MXNet】(十六):Kaggle房价预测
用到的数据集可以到kaggle的官网上下载,也可以在我的网盘下载:kaggle house数据集,提取码:t5hn
这里要用到pandas,请提前安装好。
首先导入包,
%matplotlib inline
from mxnet import autograd, gluon, init, nd
from mxnet.gluon import data as gdata, loss as gloss, nn
import numpy as np
import pandas as pd读取数据,
train_data = pd.read_csv('data/kaggle_house_pred_train.csv')
test_data = pd.read_csv('data/kaggle_house_pred_test.csv')训练数据集包括1460个样本、80个特征和1个标签。测试数据集包括1459个样本和80个特征。
第一个特征是Id,它能帮助模型记住每个训练样本,但难以推广到测试样本,所以不使用它来训练。下面将所有的训练数据和测试数据的79个特征按样本连结。
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))已经读取的数据还需要做一些预处理。
先对对连续数值的特征做标准化。
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index
all_features[numeric_features] = all_features[numeric_features].apply(lambda x: (x - x.mean()) / (x.std()))
all_features = all_features.fillna(all_features.mean())接下来将离散数值转成指示特征。
all_features = pd.get_dummies(all_features, dummy_na=True)然后将数据转化成NDArray。
n_train = train_data.shape[0]
train_features = nd.array(all_features[:n_train].values)
test_features = nd.array(all_features[n_train:].values)
train_labels = nd.array(train_data.SalePrice.values).reshape((-1, 1))下面定义模型和损失函数,
loss = gloss.L2Loss()
def get_net():
net = nn.Sequential()
net.add(nn.Dense(10, activation='relu'),nn.Dense(1))
net.initialize(init.Normal(sigma=0.01))
return net评价模型使用对数均方根误差,
def log_rmse(net, features, labels):
clipped_preds = nd.clip(net(features), 1, float('inf'))
rmse = nd.sqrt(2 * loss(clipped_preds.log(), labels.log()).mean())
return rmse.asscalar()定义训练函数,这里的优化函数使用adam。
def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate, weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = gdata.DataLoader(gdata.ArrayDataset(train_features, train_labels), batch_size, shuffle=True)
trainer = gluon.Trainer(net.collect_params(), 'adam', {'learning_rate': learning_rate, 'wd': weight_decay})
for epoch in range(num_epochs):
for X, y in train_iter:
with autograd.record():
l = loss(net(X), y)
l.backward()
trainer.step(batch_size)
train_ls.append(log_rmse(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmse(net, test_features, test_labels))
return train_ls, test_ls因为样本比较少,这里使用k折交叉验证的方式。
先定义一个获取k折交叉验证时第i折交叉验证时所需要的训练和验证数据。
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = nd.concat(X_train, X_part, dim=0)
y_train = nd.concat(y_train, y_part, dim=0)
return X_train, y_train, X_valid, y_valid在K折交叉验证中训练K次并返回训练和验证的平均误差。
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse', range(1, num_epochs + 1), valid_ls, ['train', 'valid'])
print('fold %d, train rmse: %f, valid rmse: %f' % (i, train_ls[-1], valid_ls[-1]))
return train_l_sum / k, valid_l_sum / k其中semilogy是一个作图函数,
def semilogy(x_vals, y_vals, x_label, y_label, x2_vals=None, y2_vals=None,
legend=None, figsize=(3.5, 2.5)):
set_figsize(figsize)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.semilogy(x_vals, y_vals)
if x2_vals and y2_vals:
plt.semilogy(x2_vals, y2_vals, linestyle=':')
plt.legend(legend)set_figsize()函数的定义请参考链接:【MXNet】(九):NDArray实现一个简单的线性回归模型。
下面设置超参数进行模型调优。
k, num_epochs, lr, weight_decay, batch_size = 5, 50, 0.3, 0, 64
train_l, valid_l = k_fold(k, train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print('%d-fold validation: avg train rmse: %f, avg valid rmse: %f' % (k ,train_l, valid_l)) 
定义一个预测函数,
def train_and_pred(train_features, test_feature, train_labels, test_data, num_epochs, lr, weight_decay, batch_size):
net = get_net()
train_ls, _ = train(net, train_features, train_labels, None, None, num_epochs, lr, weight_decay, batch_size)
d2l.semilogy(range(1, num_epochs + 1), train_ls, 'epochs', 'rmse')
print('train rmse %f' % train_ls[-1])
preds = net(test_feature).asnumpy()
test_data['SalePrice'] = pd.Series(preds.reshape(1, -1)[0])
submission = pd.concat([test_data['Id'], test_data['SalePrice']], axis=1)
submission.to_csv('result.csv', index=False)使用调好的参数来训练和预测,
train_and_pred(train_features, test_features, train_labels, test_data, num_epochs, lr, weight_decay, batch_size)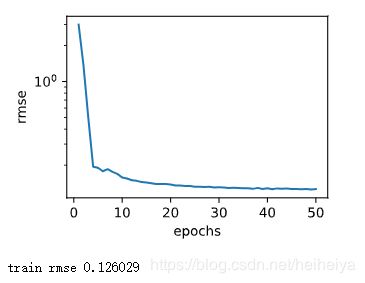
打开result.csv,
