扒一扒前端构建工具FIS的内幕
每次发版本都有个蛋疼的问题,同一个页面改版,不仅要保证发出去的页面不报错,而且得兼容现网的版本。最为传统的方法就是在资源文件后面加上一个随机参数xxx.js?t=1234,但即使是这样也无法保证拉回的xxx.js是新文件。最为安全的方法是将文件名改为新的。
面对多人开发、模块共用等问题,你会发现手动改文件名是一个非常搓的想法,程序员喜欢偷懒,这是天性。理想的状态可能是这样的:不需要去做多余的体力劳动,只需一个命令即可完成,从开发到提测,到最后的上线。
基于nodejs的构建工具还是比较多,诸如grunt,gulp,yeoman,fis等等。
经过一些日子的捣腾,现在FIS已经在团队跑起来了,完全避免了发版本的问题。但FIS带来的好处远不止这些,下一篇文章会讲到我是如何将FIS运用到项目中的,以及对性能优化带来的好处。各位看官,这次且随我看看FIS到底是个什么玩意儿。
一、什么是FIS
来自FIS官网的说明
FIS是专为解决前端开发中自动化工具、性能优化、模块化框架、开发规范、代码部署、开发流程等问题的工具框架。解决了诸如前端静态资源加载优化、页面运行性能优化、基础编译工具、运行环境模拟、js与css组件化开发等前端领域开发的核心问题。
FIS 可以看成是前端的构建工具,但功能比grunt和gulp要多些,grunt和gulp主要是依赖插件来完成任务,把每个构建需求细分为小的任务。而FIS像一个大而全的框架,把一些功能写入到框架的主体,也有插件机制,定制化任务。
二、FIS能做什么
1、自动更新的文件名

2、“编译”文件(这里说的编译不同于后台编译的意思)
- 资源定位:获取任何开发中所使用资源的线上路径;
- 内容嵌入:把一个文件的内容(文本)或者base64编码(图片)嵌入到另一个文件中;
- 依赖声明:在一个文本文件内标记对其他资源的依赖关系;
3、代码检校(jslint)
4、自动化测试
5、代码压缩(含cssSprite)
6、部署
常用功能如上面几点,FIS的文档非常的全面,可以参考文档了解更多。
三、原理
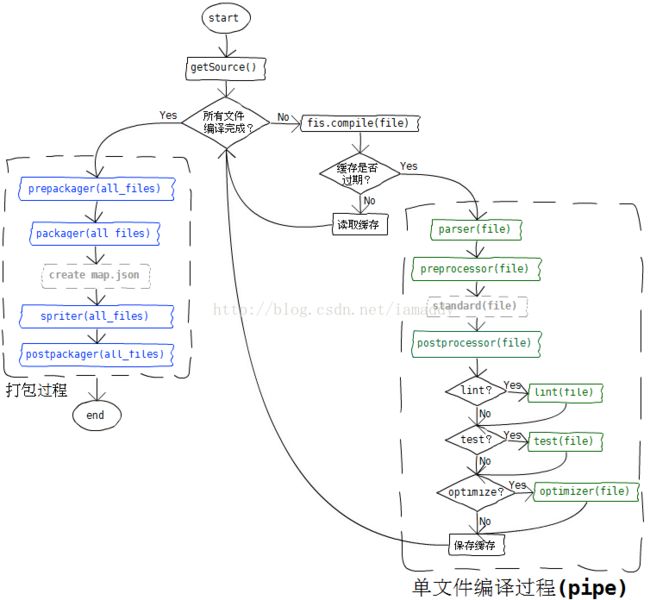
上图来自FIS官网,该图说明了编译与打包的整个流程,非常的清晰。其中最为关键的是资源文件编译的过程,除去标准编译过程其他的基本都是通过插件来实现。接下来看看文件的编译是如何做的。
3.1 文件编译
入口:fis release -d ../ -w -w,输入命令进行编译,release后面是一些参数,控制编译的流程。执行的是release.js 这个模块,读取项目的配置文件,完成一些初始化工作,然后读取文件,开始编译。
最关键的一个模块即:compile.js,对匹配到的文件做一次分析。
// 对外的接口
var exports = module.exports = function(file){
......
};
参数的是单个文件,file是fis定义的一种类型,可以看出是对node中的file对象做了一些扩展,加入了一些自定义的属性和方法。
首先初始化缓存目录,然后开始编译,判断文件路径是否真实存在。
接下来读缓存,如果命中缓存不处理(通过对照文件的MD5值判断缓存),否则:
// 读取对当前文件的配置属性,处理编译前与后
exports.settings.beforeCompile(file);
file.setContent(fis.util.read(file.realpath));
process(file);// 真正的编译过程
exports.settings.afterCompile(file);
cache.save(file.getContent(), revertObj); // 缓存,为下一次构建加速
process这个函数实际就是文件编译的过程,根据不同文件的属性进行不同的处理。
function process(file){
// useParser 和usePreprocessor 可理解为预编译的过程
// 处理less和coffee等类css、js代码
if(file.useParser !== false){
pipe(file, 'parser', file.ext);
}
if(file.rExt){
// 预处理插件
if(file.usePreprocessor !== false){
pipe(file, 'preprocessor', file.rExt);
}
if(file.useStandard !== false){
standard(file); // 所有文件的标准编译处理
}
......
}
}
process用到了pipe这个方法,文件流,Stream,控制读和写的平衡,这样就不会因单个文件编译过久而阻塞其他的文件编译。有点类似于glup中的pipe。
// 文件编译的过程
function standard(file){
var path = file.realpath,
content = file.getContent();
// 文件的内容判断是否为字符串
if(typeof content === 'string'){
fis.log.debug('standard start');
//expand language ability
// 根据文件的类型,进行不同的处理
if(file.isHtmlLike){
// 分析html文件(包括php,tpl等类html文件,这些类型在fis.util文件中有列出)
content = extHtml(content);
} else if(file.isJsLike){
// 分析JS文件
content = extJs(content);
} else if(file.isCssLike){
// 分析css文件
content = extCss(content);
}
content = content.replace(map.reg, function(all, type, value){
var ret = '', info;
try {
switch(type){
// 模块引用处理
case 'require':
// 省略更多逻辑 ....
// 动态资源定位
// __uri(xxx.js) 以这种在js代码中动态加载的文件
case 'uri':
.....
// 模块依赖处理
case 'dep':
....
// 资源嵌入处理
case 'embed':
.....
case 'jsEmbed':
......
default :
fis.log.error('unsupported fis language tag [' + type + ']');
}
} catch (e) {
}
return ret;
});
file.setContent(content);
fis.log.debug('standard end');
}
}
最关键的还是这几个分析文件的函数:extHtml、extjs、extCss。原理很简单,就是通过正则表达式来匹配。
/*
分析写在注释中的依赖[@require id]
__inline(path) 嵌入资源内容,或者base64编码的图片。
__uri(path) 定位动态资源
require(path) 定位模块的依赖,如seajs中的写法。
*/
function extJs(content, callback){
var reg = /"(?:[^\\"\r\n\f]|\\[\s\S])*"|'(?:[^\\'\n\r\f]|\\[\s\S])*'|(\/\/[^\r\n\f]+|\/\*[\s\S]*?(?:\*\/|$))|\b(__inline|__uri|require)\s*\(\s*("(?:[^\\"\r\n\f]|\\[\s\S])*"|'(?:[^\\'\n\r\f]|\\[\s\S])*')\s*\)/g;
callback = callback || function(m, comment, type, value){
if(type){
// 根据资源标记的类型做不同的处理
// map 这里是预先定义好的几种类型,通过编译成不同的标记,供后面处理
switch (type){
case '__inline':
m = map.jsEmbed.ld + value + map.jsEmbed.rd;
break;
case '__uri':
m = map.uri.ld + value + map.uri.rd;
break;
case 'require':
m = 'require(' + map.require.ld + value + map.require.rd + ')';
break;
}
} else if(comment){
// 分析注释
m = analyseComment(comment);
}
return m;
};
// replace 正则替换 返回回调函数处理后的内容
return content.replace(reg, callback);
}
第一眼看到这个正则可能会有点晕,那就可视化一下:
/"(?:[^\\"\r\n\f]|\\[\s\S])*"|'(?:[^\\'\n\r\f]|\\[\s\S])*'|(\/\/[^\r\n\f]+|\/\*[\s\S]*?(?:\*\/|$))|\b(__inline|__uri|require)\s*\(\s*("(?:[^\\"\r\n\f]|\\[\s\S])*"|'(?:[^\\'\n\r\f]|\\[\s\S])*')\s*\)/g

这样看起来是不是清楚点了,一共分了四组,根据|分一下。结合图就容易理解了,一共捕获了三个匹配:注释(comment)、类型(type)、以及路径(path),其他的不做处理。然后通过replace回调返回编译好的标记位。
// 几个例子
__uri('a.js') -> <<<uri:'a.js'>>>
require('a.js') -> require('<<a.js'>>>')
__inline('a.js') -> <<<jsEmbed:'a.js'>>>
接下来简单看下分析html的那个函数,正则如下:
/(<script(?:(?=\s)[\s\S]*?["'\s\w\/\-]>|>))([\s\S]*?)(?=<\/script\s*>|$)|(<style(?:(?=\s)[\s\S]*?["'\s\w\/\-]>|>))([\s\S]*?)(?=<\/style\s*>|$)|<(img|embed|audio|video|link|object|source)\s+[\s\S]*?["'\s\w\/\-](?:>|$)|||$)/ig

简单来看该正则能够匹配到