SQL知识归纳
SQL语言的介绍
描述:SQL,结构化查询语言. sql能做什么呢??
SQL 面向数据库执行查询
SQL 可从数据库取回数据
SQL 可在数据库中插入新的记录
SQL 可更新数据库中的数据
SQL 可从数据库删除记录
SQL 可创建新数据库
SQL 可在数据库中创建新表
SQL 可在数据库中创建存储过程
SQL 可在数据库中创建视图
SQL 可以设置表、存储过程和视图的权限
1.SQL语法
描述:数据库中包含一张/多张表. 每张数据库表是由字段和记录组成, 字段,即列. 记录,即行.
1)SQL中是不区分大小写的. 比如:SELECT,select是等价的..
2)SQL中的一些关键字
INSERT INTO -- 增
DELETE -- 删
UPDATE -- 改
SELECT -- 查
CREATE DATABASE -- 创建数据库
CREATE TABLE -- 创建数据库表
ALTER DATABASE -- 修改数据库
ALTER TABLE -- 修改数据库表
DROP TABLE -- 删除数据库表
CREATE INDEX -- 创建索引
DROP INDEX -- 删除索引
3.select语句
1)SELECT column_name,column_name FROM table_name; 查询指定数据库表中的指定字段对应的数据
2)SELECT * FROM table_name; 查询指定数据库表的所有字段对应的数据.
3)SELECT DISTINCT column_name,column_nameFROM table_name; 查询指定数据库表中的指定字段对应的数据. DISTINCT,要求索取数据具有唯一性.
4)SELECT column_name,column_name FROM table_name WHERE column_name operator value; 取出table_name中符合where子句要求的字段. where子句中的value可以使文本,也可以是数值. 教程上说:value是数字时不加引号,是文本时加引号, 这里我们并用太在意.
4.where子句
这里我们主要是说一下where子句中的操作符.
1).Select*from emp where empno=7900; 查询emp中empno等于7900的记录.
2).Select*from emp where ename='SMITH'; 我写这个语句是为了和1)中的where子句作比较, 大家仔细看一下有什么不同. 没错,就是value的差别.
3).Select*from emp where sal >2000and sal <3000;查询emp中(sal值在2000~3000之间)的记录
4).Select*from emp where sal >2000or comm >500; 和3)类似, 主要观察where的不同.
5).select*from emp wherenot sal >1500; 查询emp中(sal值不大于1500)的记录
6).Select*from emp where comm isnull; 查询emp中(comm为空值)的记录.
7).Select*from emp where sal between 1500and3000; 查询emp中(sal值在1500~3000之间)的记录
8).Select*from emp where sal in(5000,3000,1500); 查询emp中(sal值包含于枚举列表)的记录.
9).Select*from emp where ename like 'M%'; 查询emp中(ename的值以M开头)的记录.
这里,我们对where子句中的模糊查询(like)做一个分析:
%表示多个字符. _表示一个字符.
M%, %M%, %M_等等, 大家结合%,_的含义和正则表达式,想必都知道它们的含义了吧~~
5.AND OR
1)SELECT * FROMWebsitesWHEREcountry='CN'ANDalexa > 50; 查询Websites中(country等于cn,且alexa大于50)的记录.
2)SELECT * FROMWebsitesWHEREcountry='USA'ORcountry='CN';查询Websites中(country等于USA或CN)的记录.
3)SELECT * FROMWebsitesWHEREalexa > 15AND(country='CN'ORcountry='USA'); 大家自己去想象这个sql语句的含义吧~~
6.ORDER BY
语法:SELECT column_name,column_nameFROM table_nameORDER BY column_name ASC,column_name DESC; 它的意思是:从table_name中提取两个字段(对应的数据),提取后的数据经过排序(一次升序,一次降序),最终确定(在控制台)的输出顺序.
1).SELECT * FROMWebsitesORDERBYalexa;提取Websites中的所有记录,这些记录在控制台依据alexa升序输出.
2).SELECT * FROMWebsitesORDERBYalexaDESC; 提取Websites中的所有记录,这些记录在控制台依据alexa降序输出.
3).SELECT * FROMWebsitesORDERBYcountry,alexa;这句sql默认将提取出来的记录按照country升序输出.
7.INSERT IOTO
语法:
INSERT INTO table_name VALUES (value1,value2,value3,...);
INSERT INTO table_name (column1,column2,column3,...) VALUES (value1,value2,value3,...);
1)INSERTINTOWebsites(id,name,url,alexa,country)VALUES('6','百度','https://www.baidu.com/','4','CN'); 在websites中添加一个新行.
8.UPDATE
语法:UPDATE table_name SET column1=value1,column2=value2,... WHERE some_column=some_value;
1).UPDATEWebsitesSETalexa='5000',country='USA'WHEREname='菜鸟教程';
分析一下这个sql语句:
"UPDATE Websites", 从字面意思看,修改数据库表Websites. 那么问题来了,怎么修改这张表呢??请看下面:
SETalexa='5000',country='USA'WHEREname='菜鸟教程' 当这张表中有'name=菜鸟教程'这种情况就做上述修改~~
假设:我们把1)改成这样:UPDATEWebsitesSETalexa='5000',country='USA'; 它的意思是说:把Websites中alexa对应的数据都改成5000,country对应的数据都改成USA.
9.DELETE
语法:DELETE FROM table_nameWHERE some_column=some_value;
1).DELETEFROMWebsitesWHEREname='百度'ANDcountry='CN'; 当Websites中存在(符合WHERE子句)的记录, 将该记录删除.
2)DELETE * FROM Websites; / DELETE FROM Websites; 清空Websites.
10.LIMIT
语法:SELECT column_name(s) FROM table_name LIMIT number;
1).SELECT * FROM Persons LIMIT 5; 提取Persons中的前5条记录.
11.LIKE
语法:SELECT column_name(s) FROM table_name WHERE column_name LIKE pattern;
1)SELECT * FROM Websites WHERE name LIKE 'G%'; 提取Websites中(name字段对应的数据以G开头)的记录
2)SELECT * FROM Websites WHERE name LIKE '%k'; 提取Websites中(name字段对应的数据以k结尾)的记录
3)SELECT * FROM Websites WHERE name LIKE '%oo%'; 提取Websites中(name字段对应的数据包含有oo)的记录
4)SELECT * FROM Websites WHERE name NOT LIKE '%oo%'; 那么这个是什么意思呢?? 这里就不做解释了~~
12.REGEXP, NOT REGEXP RLIKE, NOT RLIKE
上面所提到的4个关键字经常和正则表达式联合使用, 也是一种模糊查询.
1)SELECT * FROM Websites WHERE name REGEXP '^[GFs]'; 从Websites中提取记录,提取数据的要求是:记录的name字段对应的数据均以G/F/s开头.
2)SELECT * FROM Websites WHERE name REGEXP '^[^A-H]';从Websites中提取记录,提取数据的要求是:记录的name字段对应的数据的开头不以A-H之间的数据开头
13.IN
有了IN操作符, 我们可以在where子句中设置多个值. 类似于枚举.
语法:SELECT column_name(s) FROM table_name WHERE column_name IN (value1,value2,...);
1)SELECT * FROM Websites WHERE name IN ('Google','菜鸟教程'); 提取Websites中的记录,提取记录的要求是:记录中name字段对应的数据包含于in后面的列表中.
14.BETWEEN--AND
语法:SELECT column_name(s) FROM table_name WHERE column_name BETWEEN value1 AND value2;
1)SELECT * FROM Websites WHERE alexa BETWEEN 1 AND 20; 从Websites中提取记录,提取的记录要求:记录中的alexa字段对应的数据值在1~20之间.
2)SELECT * FROM Websites WHERE alexa NOT BETWEEN 1 AND 20;
3)SELECT * FROM Websites WHERE (alexa BETWEEN 1 AND 20) AND NOT country IN ('USA', 'IND');
4)SELECT * FROM Websites WHERE name BETWEEN 'A' AND 'H';在Websites中提取记录,记录要求:其中的name字段对应的数据的首字母在A~H之间
5)SELECT * FROM Websites WHERE name NOT BETWEEN 'A' AND 'H';
从4) 和 5)可以看出,BETWEEN-AND可以用于文本查询~~
除此之外, 数据库的不同会导致BETWEEN--END的操作结果不同.主要体现在BEYTWEEN--AND所指的范围边界上.
15.别名
语法:
列的别名:SELECT column_name AS alias_name FROM table_name;
表的别名:SELECT column_name(s) FROM table_name AS alias_name;
1)SELECT name AS n, country AS c FROM Websites;
2)SELECT name, CONCAT(url, ',', alexa, ',', country) AS site_info FROM Websites; 合并url,alexa,country,给出别名site_info
3)SELECT w.name, w.url, a.count, a.date FROM Websites AS w, acces_log AS a WHERE a.site_id=w.id and w.name="菜鸟教程";
上面这个sql语句难度系数比较大, 我们来做一个解析:
"Websites AS w, acces_log AS a" 给Websites,acces_log这两个数据库表起别名.
SELECT w.name, w.url, a.count, a.date FROM Websites AS w, acces_log AS aWHERE a.site_id=w.id and w.name="菜鸟教程"; 抛开别名. 这里还有一个值得我们注意我们地方:两张数据库表的连接. 说白了,两张表连接成一张表.
16.JOIN的使用
我用了半个小时才把JOIN搞明白. 在这里仔细分析以下这个家伙~~ 下面两张表是我们之后要用到的...
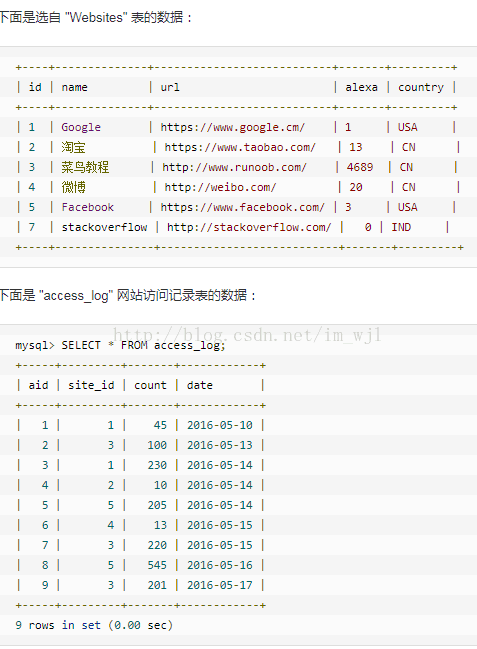
1)SELECT Websites.name, access_log.count, access_log.date
FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count;
2)SELECT Websites.name, access_log.count, access_log.date
FROM Websites
LEFT JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count DESC;
3)SELECT Websites.name, access_log.count, access_log.date
FROM Websites
RIGHT JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count DESC;
4)SELECT Websites.name, access_log.count, access_log.date
FROM Websites
FULL JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count DESC;
从上面给出的sql语句中可以得到这么几个字眼:INNER JOIN,LEFT JOIN,RIGHT JOIN,FULL JOIN. 正是这些关键字的存在,实现了多张数据表的连接. 连接之后在从中找出符合条件的字段.
除此之外,我们还要知道INNER JOIN等价于INNER OUTER JOIN, 其它关键字类似~~
17.UNION
描述:UNION操作符用于合并两个/多个select语句的结果集. UNION内部的select语句中字段数量,字段类型,字段顺序要一致.
默认情况下,UNION操作符合并select结果集的时候保证数据的唯一. 想要获取select结果集中的重复数据,就要用到UNION ALL
现在,我们就用下面两张数据库表搞些事情~~~
mysql> SELECT * FROM Websites; +----+--------------+---------------------------+-------+---------+ | id | name | url | alexa | country | +----+--------------+---------------------------+-------+---------+ | 1 | Google | https://www.google.cm/ | 1 | USA | | 2 | 淘宝 | https://www.taobao.com/ | 13 | CN | | 3 | 菜鸟教程 | http://www.runoob.com/ | 4689 | CN | | 4 | 微博 | http://weibo.com/ | 20 | CN | | 5 | Facebook | https://www.facebook.com/ | 3 | USA | | 7 | stackoverflow | http://stackoverflow.com/ | 0 | IND | +----+---------------+---------------------------+-------+---------+
mysql> SELECT * FROM apps; +----+------------+-------------------------+---------+ | id | app_name | url | country | +----+------------+-------------------------+---------+ | 1 | QQ APP | http://im.qq.com/ | CN | | 2 | 微博 APP | http://weibo.com/ | CN | | 3 | 淘宝 APP | https://www.taobao.com/ | CN | +----+------------+-------------------------+---------+ 3 rows in set (0.00 sec)1) SELECT country FROM Websites
UNION
SELECT country FROM apps
ORDER BY country;
前面已经说过UNION内部SELECT语句中字段(数量,类型,顺序)的描述要基本一致. UNION操作符合并了Websites,apps这两张表中country字段对应的数据(注意:数据合并过程中去掉了重复部分).
2)SELECT country FROM Websites
UNION ALL
SELECT country FROM apps
ORDER BY country;
UNION ALL操作符的存在使得合并SELECT结果集的过程中保留重复部分.
3)SELECT country, name FROM Websites
WHERE country='CN'
UNION ALL
SELECT country, app_name FROM apps
WHERE country='CN'
ORDER BY country;
注意:上面的语句中都有"ORDER BY country",这个子句是在合并结果集之后依据Websites中的country字段升序排列的~~
18.SELECT INTO
首先,我们先给出两个sql语句. 下面所给出的sql语句都是从Websites中复制数据,然后插入到WebsitesBackup2016中.
1)SELECT *
INTO WebsitesBackup2016
FROM Websites;
2)SELECT name, url
INTO WebsitesBackup2016
FROM Websites;
遗憾的是,MySQL中并不支持SELECT INTO形式的sql语句, 那么我们怎么做才能达到这里所说的复制-->插入效果呢?? 看下面这个sql语句:
create table WebsitesBackup2016 select * from Websites;
我们会发现, 这个sql语句简介地实现了"复制-->插入"效果.
19.INSERT INTO...SELECT...
这里,我们直接给出sql语句.结合sql语句说一下:
1)INSERT INTO Websites (name, country)
SELECT app_name, country FROM apps;
2)INSERT INTO Websites (name, country)
SELECT app_name, country FROM apps
WHERE id=1;
通俗地讲就是:从apps中提取数据, 然后插入到已经存在数据库表中.
20.SQL约束
在说SQL约束之前,来看一个创建数据库表的SQL语句.
CREATE TABLE Persons
(
PersonID int NOT NULL,
LastName varchar(255),
FirstName varchar(255),
Address varchar(255),
City varchar(255)
);
我们来看一下这个SQL语句{}中有些什么??比如:PersonID int NOT NULL. PersonID,字段 int,字段的数据类型 NOT NULL,SQL约束.
没错,我们这里主要说的就是SQL约束~~
既然提到SQl约束,常用的SQL约束到底都有哪些呢?? 这里做一个总结~~~QAQ~~~
1)NOT NULL,要求数据库表中的指定字段不为空.比如:
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
2)UNIQUE,要求数据库表中的指定字段具有唯一性.如下:
2.1)创建数据库表时指定unique约束
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
UNIQUE (P_Id)
)
如果我们想给Persons中的多个字段指定UNIQUE约束, 就把UNIQUE(P_Id)改成CONSTRAINT uc_PersonID UNIQUE(P_Id,LastName)
如果我们想在已经存在的数据库表中添加UNIQUE约束,该怎么做呢??
ALTER TABLE Persons ADD UNIQUE(P_Id);
ALTER TABLE Persons ADD CONSTRAINT uc_PersonID UNIQUE(P_Id,LastName);
2.2)撤销UNIQUE约束
ALTER TABLE Persons DROP INDEX uc_PersonID;
3).PRIMARY KEY
描述:主键必须包含唯一的值. 主键不能包含NULL值. 每个表都应该有一个主键
3.1)创建数据库表时指定PRIMARY KEY约束
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
PRIMARY KEY (P_Id)
)
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CONSTRAINT pk_PersonID PRIMARY KEY (P_Id,LastName)
)
除此之外,也可以为已经存在的数据库表指定PRIMARY KEY
ALTER TABLE Persons ADD PRIMARY KEY(P_Id);
ALTER TABLE Persions ADD CONSTRAINT pk_Persons PRIMARY KEY(P_Id,LastName);
3.2)撤销主键
ALTER TABLE Persons DROP PRIMARY KEY;
4)FOREIGN KEY
外键, 多张表连接的桥梁...
4.1)创建数据库表时指定另一张表的外键
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id),
FOREIGN KEY (P_Id) REFERENCES Persons(P_Id)
)
如果在创建数据库表时指定多个列为另一张表的外键
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
PRIMARY KEY (O_Id),
CONSTRAINT fk_PerOrders FOREIGN KEY (P_Id)
REFERENCES Persons(P_Id)
)
如果在已经存在的数据库表中指定FOREIGN约束,该怎么做呢??
ALTER TABLE Orders ADD FOREIGN KEY (P_Id) REFERENCES Persons(P_Id);
ALTER TABLE Orders ADD CONSTRAINT fk_PerOrders FOREIGN KEY (P_Id) REFERENCES Persons(P_Id);
4.2)撤销FOREIGN KEY约束.
ALTER TABLE OrdersDROP FOREIGN KEY fk_PerOrders
5)CHECK,限制列中值的范围
5.1)在创建表的时候指定CHECK约束
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CHECK (P_Id>0)
)
如果想对数据库表中的多个列进行范围限制,怎么办呢??
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255),
CONSTRAINT chk_Person CHECK (P_Id>0 AND City='Sandnes')
)
当表存在的情况下,指定CHECK约束.
ALTER TABLE Persons ADD CONSTRAINT chk_Person CHECK(P_Id>0 AND City='Sandnes');
ALTER TABLE Persons ADD CHECK (P_Id>0);
撤销CHECK约束
ALTER TABLE Persons DROP CHECK chk_Person;
6.DEFAULT
6.1)在建表时给指定字段添加默认值
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255) DEFAULT 'Sandnes'
)
CREATE TABLE Orders
(
O_Id int NOT NULL,
OrderNo int NOT NULL,
P_Id int,
OrderDate date DEFAULT GETDATE()
)
如果要在已经存在的表中加默认值
ALTER TABLE Persons ALTER City SET DEFAULT 'SANDNES';
6.2)撤销DEFAULT约束
ALTER TABLE Persons ALTER City DROP DEFAULT
21.CREATE INDEX
描述:想必大家都知道课本前面的目录吧,这里所说的索引就是目录的意思. 索引的存在便于我们快速搞笑的查询数据. 数据库更新,索引也会跟着更新.
CREATE INDEX PIndex ON Persons (LastName);
CREATE INDEX PIndex ON Persons (LastName, FirstName);
22.ALTER
这个操作符主要用来修改表结构的...
ALTER TABLE Persons ADD DateOfBirth date;
ALTER TABLE Persons DROP COLUMN DateOfBirth;
23.AUTO-INCREMENT 初始化并递增
24.VIEW
视图,实际上也是一张数据库表
创建视图:create view viewTest as select name,url from websites where id between 3 and 5;
更新视图:create or replace view viewTest as select name,url,alexa from websites where id between 3 and 5;
销毁视图:drop view viewTest;
25.GROUP BY
单表分组:SELECT site_id, SUM(access_log.count) AS nums FROM access_log GROUP BY site_id;
多表分组:
SELECT Websites.name,COUNT(access_log.aid) AS nums FROM access_log
LEFT JOIN Websites
ON access_log.site_id=Websites.id
GROUP BY Websites.name;
26.HAVING
通常对分组后的数据作进一步的筛选~~
SELECT Websites.name, SUM(access_log.count) AS nums FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id
WHERE Websites.alexa < 200
GROUP BY Websites.name
HAVING SUM(access_log.count) > 200;