最近工作中踩到一个MapOutputTracker相关的坑 (SPARK-21444), troubleShooting的过程中阅读了MapOutputTracker的代码,在此做个整理。本文先概括性地介绍MapOutputTracker的功能和架构,然后根据源码分析其具体实现。
MapOutputTracker简介
MapOutputTracker是spark环境的主要组件之一,其功能是管理各个shuffleMapTask的输出数据。reduce任务就是根据MapOutputTracker提供的信息决定从哪些executor获取需要的map输出数据。MapOutputTracker的架构如下图所示:
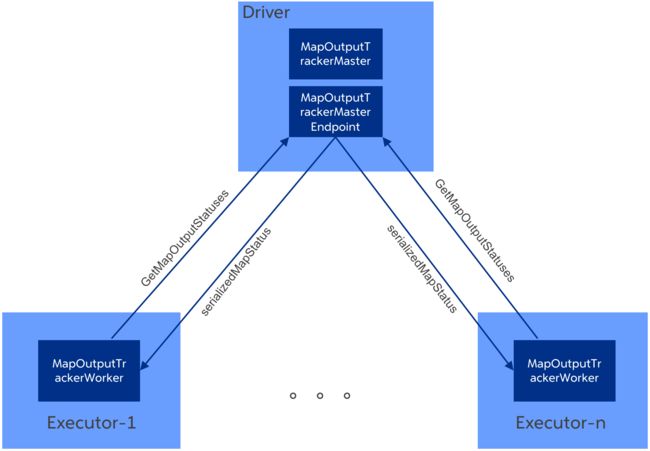
如上图所示,MapOutputTracker在executor和driver端都存在。
1. MapOutputTrackerMaster和MapOutputTrackerMasterEndpoint存在于driver端
2. MapOutputTrackerMasterEndpoint是MapOutputTrackerMaster的RPC endpoint
3. MapOutputTrackerWorker存在于executor端
4. MapOutputTrackerMaster负责管理所有shuffleMapTask的输出数据,每个shuffleMapTask执行完后会把执行结果(MapStatus对象)注册到MapOutputTrackerMaster.
5. MapOutputTrackerMaster会处理executor发送的GetMapOutputStatuses请求,并返回serializedMapStatus给executor端
6. MapOutputTrackerWorker负责为reduce任务提供shuffleMapTask的输出数据信息(MapStatus对象)
7. 如果MapOutputTrackerWorker在本地没有找到请求的shuffle的mapStatuses,则会向MapOutputTrackerMasterEndpoint发送GetMapOutputStatuses请求获取对应的mapStatuses
MapStatus和ShuffleStatus
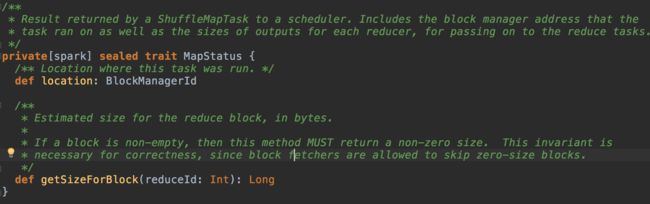
MapStatus用于表示ShuffleMapTask的运行结果, 包括map任务输出数据的location和size信息:
ShuffleStatus用于管理一个shuffle对应的所有ShuffleMapTask的运行结果,ShuffleStatus对象只存在于MapOutputTrackerMaster中。
每个ShuffleStatus对象都包含一个mapStatuses数组,该数组的元素类型为MapStatus,数组下标即shuffleMapTask的map id。
ShuffleStatus提供了一系列用于添加,移除,序列化,缓存和广播mapStatus的方法。比如:
1. invalidateSerializedMapOutputStatusCache方法用于清空mapStatuses的缓存,包括移除对应的广播变量。
2. serializeMapStatuses方法用于序列化并广播mapStatuses数组
MapOutputTrackerMaster
shuffleStatus映射和GetMapOutputMessage请求队列
MapOutputTrackerMaster是driver端用于管理所有shuffle的map任务输出数据的组件。MapOutputTrackerMaster维护了一个ShuffleStatus映射和一个GetMapOutputMessage请求队列:
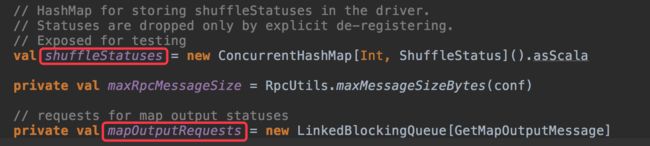
GetMapOutputMessage由GetMapOutputStatuses转化而来,后面介绍MapOutputTrackerMasterEndpoint时会讲到。shuffleStatuses保存着shuffle id和shuffleStatus的mapping关系,而mapOutputRequests则保存着该MapOutputTrackerMaster所有未处理的GetMapOutputMessage请求。注意,这里使用了LinkedBlockingQueue进行存储,很容易想到,这个队列会被多个线程并发访问。
MessageLoop和请求处理线程池
MapOutputTrackerMaster用MessageLoop来处理mapOutputRequests队列中的请求:
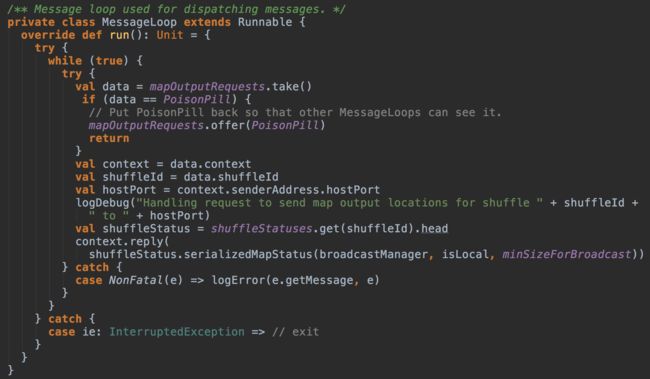
messageLoop会循环地从mapOutputRequests队列中获取GetMapOutputMessage请求进行处理,处理完后会调用RpcCallContext的reply方法将序列化后的shuffleStatus返回给客户端。messageLoop会一直循环处理请求,直到获取到PoisonPill消息,而这个消息是MapOutputTrackerMaster的stop方法发出的。
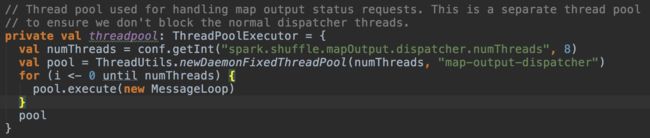
上文提到mapOutputRequests队列会被多个线程并发访问,这是因为MapOutputTrackerMaster创建了一个线程池并发运行多个messageLoop. 线程池的大小由参数spark.shuffle.mapOutput.dispatcher.numThreads控制,默认为8 :
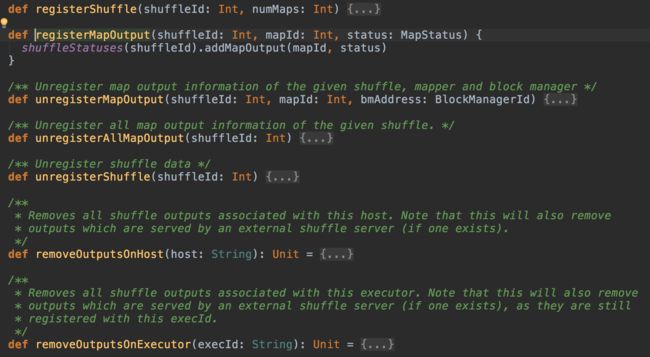
添加/移除shuffle和mapOutput
MapOutputTrackerMaster中包含了一系列用于添加/移除,注册/注销shuffle和map output的方法:
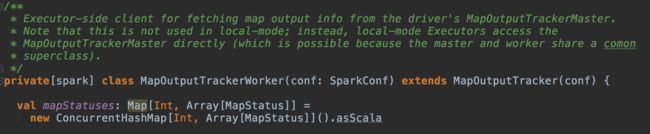
MapOutputTrackerWorker
如上文所述,MapOutputTrackerWorker存在于executor端,其主要功能是从MapOutputTrackerMaster获取map output信息(mapStatuses):
MapOutputTrackerWorker也维护了一个mapStatuses对象。注意,MapOutputTrackerWorker的mapStatuses和MapOutputTrackerMaster中shuffleStatus里面的mapStatuses是不同类型的。
shuffleStatus中mapStatuses的类型是Array[MapStatus],数组下标是shuffle中的map id.
而MapOutputTrackerWorker中mapStatuses的类型是Map[Int, Array[MapStatus]],key为shuffle id,value就是该shuffle对应的mapStatuses.
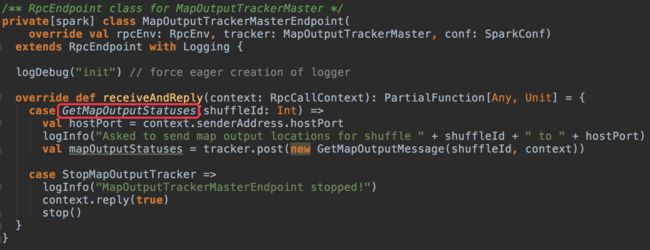
MapOutputTrackerMasterEndpoint
MapOutputTrackerMasterEndpoint是MapOutputTrackerMaster的RPC endpoint,只存在于driver端。所有发送给MapOutputTrackerMaster的GetMapOutputStatuses请求都由MapOutputTrackerMasterEndpoint接收,转化成GetMapOutputMessage并添加到MapOutputTrackerMaster的mapOutputRequests队列中等待messageLoop处理:
总结
本文先简单地介绍了MapOutputTracker的功能和架构,然后分别对MapOutputTrackerMaster,MapOutputTrackerWorker和MapOutputTrackerMasterEndpoint类及其主要相关组件进行了简单介绍和分析。
说明
1. 本文所涉及源码版本为2.4.0
2. 如有错误,敬请指出