python数据类型,列表的增删改查,深浅拷贝
数据类型主要包含:整型、字符串、元祖、列表、字典、集合、布尔、字节
1、字符串的格式化表示
name = input("name:")
age = input("age:")
job = input("job:")
salary = input("salary:")
if salary.isdigit():
salary = int(salary)
else:
print("must be digit!")
exit("程序退出!")
print(name, age, job, salary)
msg = '''
=====info of %s=====
name:%s
age:%s
job:%s
salary:%d
=====end=====
'''%(name, name, age, job, salary)字符串的拼接使用使用"字符串1"+"字符串2"会增加内存开销,常常使用上述方法来表示
2、字符串%s=string
判断字符串是否像数字使用方法isdigit()
3、数字%d=digit
4、浮点型 表示小数%f=float
5、列表的切片方法
print(list[1:-1:2])
print(list[3::-1])
print(list[1::-2])list[1:3:-2]这种不行其他都可以print(list[3:-1:1])#到最后一位位置不包含最后一位print(list[1:4])#到第四位为止不包含第四位6、列表的增删改查
#添加就是apend insert
list.append("32")
list.insert(0,12)#修改
list1[0]="99"
print(list1)#删除就是remove pop del
list1.remove(6)#删除对应的值
print(list1)
a=list1.pop(2)#删除对应索引处的值并且返回
print(a)
print(list1)
del(list1[0])#按照对应值删除
print(list1)
del list1#删除列表,从内存中删除
print(list1)
7、
#列表的count extend,index,reverse,sort
a = [1, 4, 3, 6, 9, 3]
print(a.count(3))#3这个值出现的次数
b = ["1","2"]
a.extend(b) #a扩增了b的内容
print(a)
print(b)
print(a.index("1"))#"1"这个元素出现的位置,存在重复的位置则给出第一个出现的位置
a.reverse()#没有返回值就直接反向
print(a)
#a.sort()#排序里边必须是数值
c = [10, 2, 2.1, 1,]
c.sort(reverse=True)
print(c)8、列表的拷贝copy,深浅拷贝(解释图)
可以理解为copy的时候不可变的数据类型是独立的一份,可变的数据类型是共享的
a = [[1, 2], 3, 4]
b = a
c = a.copy()
# 修改了c中的列表则a,b,c均发生改变
# 修改c中的整型,只有c发生改变,a,b不改变
c[0][0] = 6
print(id(a[0]))
print(id(b[0]))
print(id(c[0]))
c[1] = 7
print(id(a[1]))
print(id(b[1]))
print(id(c[1]))
# 修改b中的列表则a,b,c均发生改变
# 修改b中的整型则a改变,c不改变
b[0][0] = 6
print(id(a[0]))
print(id(b[0]))
print(id(c[0]))
b[1] = 7
print(id(a[1]), a[1])
print(id(b[1]), b[1])
print(id(c[1]), c[1])
# 修改了a中的列表,a,b,c均发生改变
# 修改了a中的整型,a,b发生改变,c不发生改变
a[0][0] = 6
print(id(a[0]))
print(id(b[0]))
print(id(c[0]))
print(id(a[1]), a[1])
print(id(b[1]), b[1])
print(id(c[1]), c[1])
# 修改了e中的值对f不发生改变
e = 1
f = e
e = 3
print(id(e))
print(id(f)) 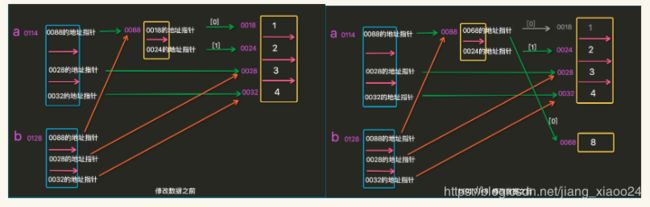
b=a与b=a.copy()方式不同
可以理解为ab指向列表的地址,c是直接指向列表中的每个元素