Python实现可视化界面多线程豆瓣电影信息爬虫,并绘制统计图分析结果
完整代码见链接:https://github.com/kuronekonano/python_scrapy_movie
实现时使用图形界面、多线程、文件操作、数据库编程、网络编程、统计绘图六项技术。
1. 数据采集
(1)用wxPython实现GUI界面,包括登录界面、爬虫界面。爬虫界面上包含:
1)复选框:选择网站页面上要爬取的元素,包括电影名、评论、导演、主演、论坛讨论、电影别名;
2)下拉列表:选择开启几个多线程进行爬虫,选择爬取电影类型,排序方式
3)scrolledtext:爬虫结果汇总,包括运行时间,爬取结果,运行状态,爬取数量 等数据;
(2)以豆瓣电影为主页面爬取数据深入页面三个层次。并采取多线程方式实现爬虫。
第一层次:电影分类列表,包括标签热门、最新、经典、可播放、豆瓣高分、冷门佳片、华语、欧美、韩国、日本、动作、喜剧、爱情、科幻、悬疑、恐怖、动画,并有三个可选择电影排列顺序:评价、最新、时间
第二层次:电影的详细信息,包括上映年份、片名、导演、编剧、主演、类型、制片国家地区、语言、上映日期、片长、别名、IMDB编号、评分、评价人数、页面网址
第三层次:包括该电影的短评、论坛讨论标题、爬取电影主演个人信息,包括姓名、性别、星座、出生日期、出生地、职业、简介信息
(3)将爬取的数据存储至数据库中。并将爬虫日志(本次数据采集起止时间、采用的线程数、爬取多少条数据,总共用时多长时间等)写到文件中。
2. 数据分析
数据统计分析:
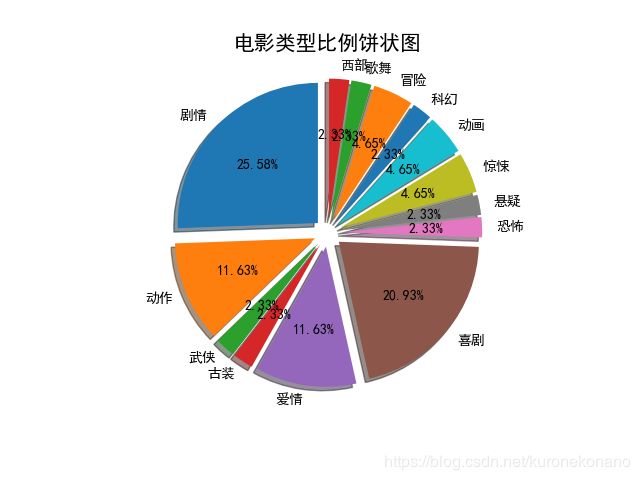
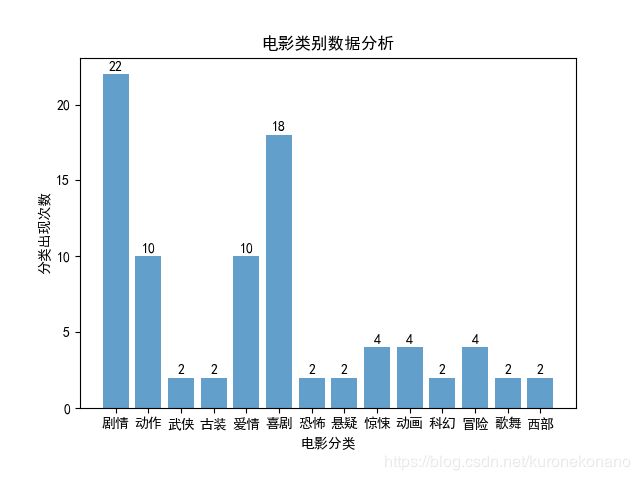
分析爬取的数据中悬疑类、剧情类、恐怖类的电影所占比例是多少,并用直方图、饼图展示结果。
对爬取过程中产生的数据进行分析:
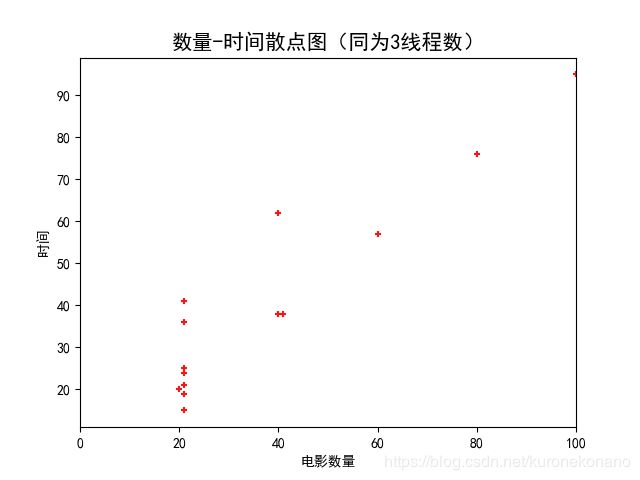
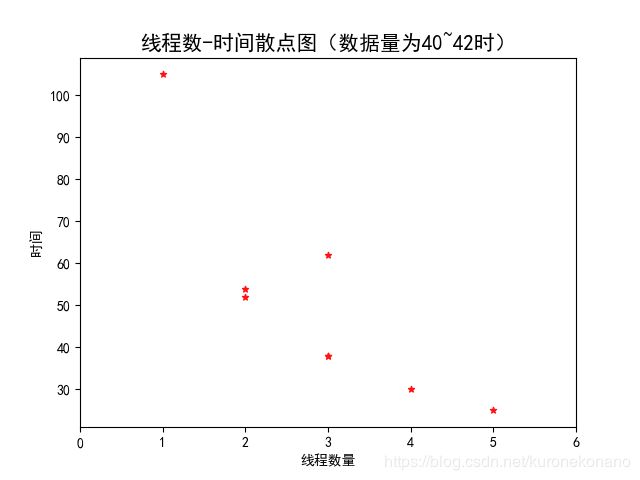
同样为3线程数条件下,爬取数据条数与所用时长间的散点关系图;爬取数据条数同样为40条时,使用线程数与所用时长间的关系图;得出结论,线程数一定时,时间与数量成正比,数量一定时,线程数和时间成反比。
这个程序是我们期末Python大作业的要求。
其实很大程度上的要求是一学期以来做的各种作业,相当于把一学期的作业整合起来做个大的东西。
可是在程序结构上从零开始还是毫无头绪的。
首先分为大致几个结构:
登陆界面的图形化专门在Login_to_Spider.py中实现
接下来因为要用到网络编程技术,因此将爬虫程序和图形化界面程序分开,分别作为服务器端和客户端来处理。
即爬虫程序:服务器端调用,在KuroNeko_Spider_Server.py中实现
爬虫图形化界面:客户端启动,在KuroNeko_Spider_GUI.py中实现
爬虫实现具体方法:Spider_Engine.py
统计图分析结果的图片存储:Save_Show_Pic.py
大致的结构定位,用户登录到客户端中,然后根据客户端界面内的选项设置爬取要求,确定并点击【开始爬虫】按钮后,由客户端整理用户设置的信息,通过socket通信传送至服务器端,服务器端调用爬虫程序,开启多线程爬虫,在爬虫程序中将爬取结果存储到数据库内,并通过socket通信实时反馈给客户端,显示在客户端界面中。最后多个线程完成爬虫任务,给客户端返回结束信息,客户端记录完成时间,并写入日志,一次爬虫操作结束。
在客户端中还直接整合了统计结果绘制统计图的功能。
流程图如下:
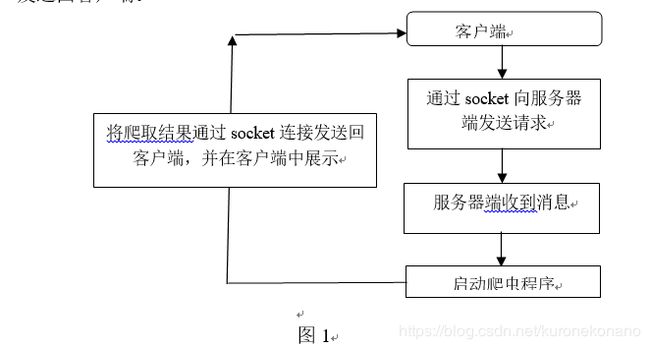
客户端的总体功能结构如下:
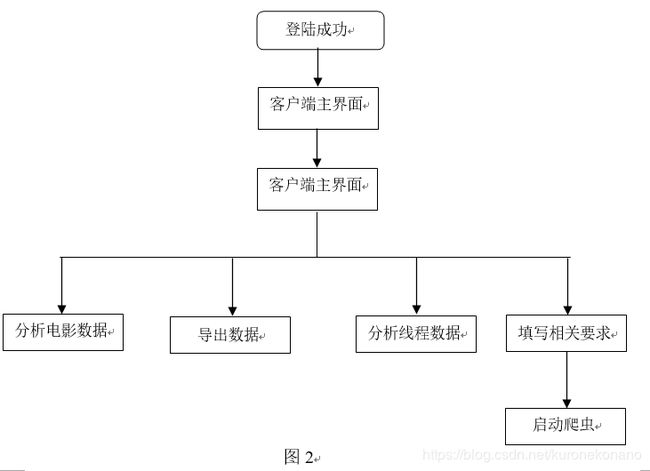
服务器端调用爬虫程序的框架如下:
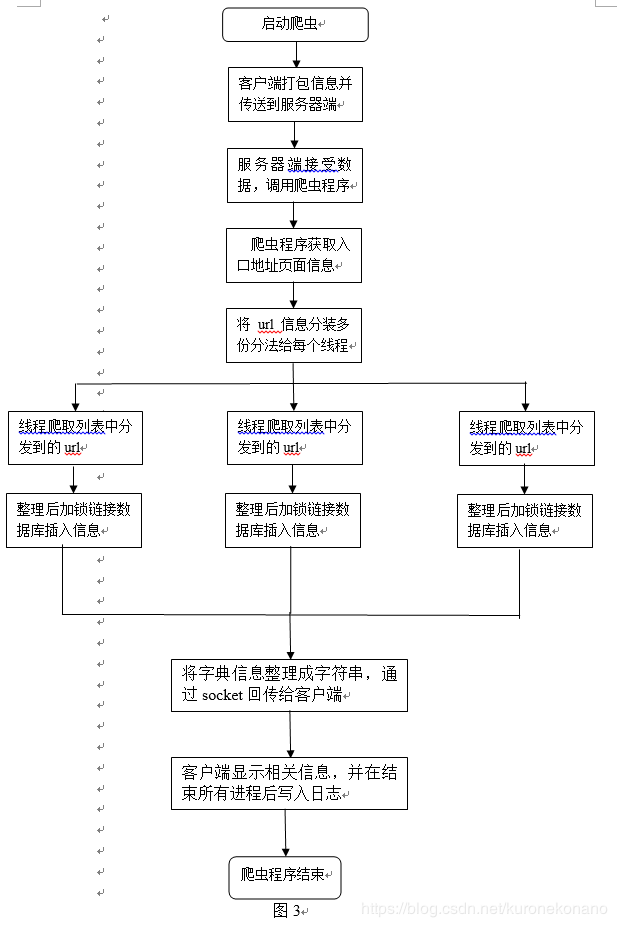
以上即确定了程序将要实现的大体结构功能等内容,依据这个可行结构完成实现整个程序。
那么首先要面对的即是图形化界面的代码怎么写,首先,python中用户实现图形化界面的包有两种,即tkinter和wxpython,tkinter说实话是比较好实现的,调用也十分灵活,但是在规模很大的程序上,wxpython有wxFormBuilder这种方便的可视化软件进行设计,自动生成代码,粘上去就可用,因此最后确定使用wxpython来实现。
至于登陆如何实现,在理解代码的基础上,我们都知道所谓登陆注册功能其实就是对数据库中用户表的插入和查询。再完善一些容错处理即可【如未输入密码,输入格式错误等】。
# -*- coding: utf-8 -*-
###########################################################################
## Python code generated with wxFormBuilder (version Jun 17 2015)
## http://www.wxformbuilder.org/
## by Kuroneko
## PLEASE DO "NOT" EDIT THIS FILE!
###########################################################################
import pymysql
import wx
import wx.xrc
###########################################################################
## Class loginFrame
###########################################################################
import KuroNeko_Spider_GUI
class loginFrame ( wx.Frame ):
def __init__( self, parent ):#框体布局
wx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = u"KuroNeko_Client——欢迎", pos = wx.DefaultPosition, size = wx.Size( 289,153 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )
self.SetSizeHints( wx.DefaultSize, wx.DefaultSize )
self.SetBackgroundColour(wx.Colour(170, 255, 170))
fgSizer6 = wx.FlexGridSizer( 0, 2, 0, 0 )
fgSizer6.SetFlexibleDirection( wx.BOTH )
fgSizer6.SetNonFlexibleGrowMode( wx.FLEX_GROWMODE_SPECIFIED )
self.username_text = wx.StaticText( self, wx.ID_ANY, u"用户名:", wx.DefaultPosition, wx.Size( 100,-1 ), 0 )#用户名标签
self.username_text.Wrap( -1 )
self.username_text.SetFont( wx.Font( 16, 70, 90, 90, False, "黑体" ) )
self.username_text.SetForegroundColour(wx.Colour(255, 128, 0 ))
fgSizer6.Add( self.username_text, 0, wx.ALL|wx.ALIGN_RIGHT, 5 )
self.username = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.Size( 150,-1 ), 0 )#用户名文本框
fgSizer6.Add( self.username, 0, wx.TOP|wx.BOTTOM|wx.LEFT, 5 )
self.password_text = wx.StaticText( self, wx.ID_ANY, u"密码:", wx.DefaultPosition, wx.Size( 100,-1 ), 0 )#密码标签
self.password_text.Wrap( -1 )
self.password_text.SetFont( wx.Font( 16, 70, 90, 90, False, "黑体" ) )
self.password_text.SetForegroundColour(wx.Colour(180, 89, 219 ))
fgSizer6.Add( self.password_text, 0, wx.ALL|wx.ALIGN_RIGHT, 5 )
self.password = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.Size( 150,-1 ), wx.TE_PASSWORD )#密码文本框
fgSizer6.Add( self.password, 0, wx.ALL, 5 )
self.login = wx.Button( self, wx.ID_ANY, u"登录", wx.DefaultPosition, wx.Size( 80,-1 ), wx.NO_BORDER )#登陆按钮
self.login.SetFont( wx.Font( 12, 75, 90, 90, False, "黑体" ) )
self.login.SetBackgroundColour(wx.Colour(170, 255, 170))
self.login.SetForegroundColour(wx.Colour(255, 94, 94))
fgSizer6.Add( self.login, 0, wx.ALL|wx.ALIGN_RIGHT, 5 )
self.register = wx.Button( self, wx.ID_ANY, u"注册", wx.DefaultPosition, wx.Size( 80,-1 ), wx.NO_BORDER )#注册按钮
self.register.SetFont( wx.Font( 12, 75, 90, 90, False, "黑体") )
self.register.SetBackgroundColour(wx.Colour(170, 255, 170))
self.register.SetForegroundColour(wx.Colour(128, 128, 255))
fgSizer6.Add( self.register, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL, 5 )
self.SetSizer( fgSizer6 )
self.Layout()
self.Centre( wx.BOTH )
# Connect Events
self.login.Bind( wx.EVT_BUTTON, self.loginFunc )#登陆按钮监听
self.register.Bind( wx.EVT_BUTTON, self.registerFunc )#注册按钮监听
def __del__( self ):
pass
# Virtual event handlers, overide them in your derived class
def loginFunc( self, event ):#登录
try:#链接数据库
conn = pymysql.connect(host='localhost',user='root',password='970922',db='mytest')
cur = conn.cursor()
except:
wx.MessageBox('数据库连接错误')
return
username = self.username.GetValue()#获取用户输入的用户名
password = self.password.GetValue()#获取输入的密码
if username == "" and password == "":
wx.MessageBox('用户名密码不能为空',caption="错误提示")
return
try:
sql = 'select * from pyuser where user_name="%s"' %(username)#查询数据库用户表
cur.execute(sql)
conn.commit()
except:
wx.MessageBox('系统错误',caption="错误提示")
user = cur.fetchone()
if user == None:#用户名查询为空
wx.MessageBox('用户不存在',caption="错误提示")
self.username.Clear()
self.password.Clear()
return
if username == user[0] and password == user[1]:#查询到用户名并与密码匹配
wx.MessageBox("登陆成功",caption="登陆成功")
spiderClient = KuroNeko_Spider_GUI.SpiderClient(None)
self.Show(False)
spiderClient.Show(True)
else:#查询到用户名却与密码不匹配
wx.MessageBox('用户名或者密码错误',caption="错误提示")
self.username.Clear()
self.password.Clear()
return
def registerFunc( self, event ):#注册
try:#链接数据库
conn = pymysql.connect(host='localhost',user='root',password='970922',db='mytest',port=3306,charset='utf8')
cur = conn.cursor()
except:
wx.MessageBox('数据库连接错误')
return
username = self.username.GetValue()
password = self.password.GetValue()
if username == "" and password == "":#错误处理
wx.MessageBox('用户名密码不能为空',caption="错误提示")
return
sql = 'insert into pyuser values("%s","%s")' %(username,password)
try:
cur.execute(sql)
conn.commit()
wx.MessageBox('注册成功')#插入用户输入的用户名和密码到数据库中
self.username.Clear()
self.password.Clear()
except:
conn.rollback()
wx.MessageBox('用户名已经存在')#用户名作为主键的数据已经存在,报错
self.username.Clear()
self.password.Clear()
if __name__=='__main__':#测试
app = wx.App()
LoginFrame = loginFrame(None)
LoginFrame.Show()
app.MainLoop()
运行后实现效果:
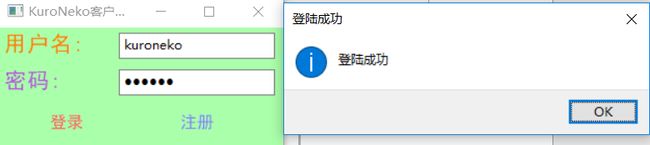
- 整体B/S(客户端/服务器端)结构
使用wxpython实现登陆,包括用户名标签,用户名输入文本框,密码标签,密码输入文本框,登陆按钮、注册按钮。在输入相关信息后,点击登陆即链接数据库查询用户名与密码,并判断是否匹配,匹配则调用客户端窗口,否则提示“账号密码错误”。点击注册即可向数据库中插入用户名与密码,并查询是否存在相同用户名,若已存在提示“该用户名已存在”,并可以重新输入用户名与密码进行注册。
客户端输入账号密码登陆后进入,整体框架上客户端和服务器端没有代码相互调用上的直接关系。而是由客户端整合用户选择的数据要求通过socket发送至服务器端,由服务器端调用并运行爬虫程序,并将结果存储后发送回客户端。
接下来是客户端界面的实现:
# -*- coding: utf-8 -*-
###########################################################################
## Python code generated with wxFormBuilder (version Jun 17 2015)
## http://www.wxformbuilder.org/
## by KuroNeko
## PLEASE DO "NOT" EDIT THIS FILE!
###########################################################################
import pickle
import socket
import threading
import matplotlib
import numpy as np
import matplotlib.pyplot as plt
import datetime
import pymysql
import xlwt as ExcelWrite
from xlwt import Borders, XFStyle, Pattern
import wx
import wx.xrc
import os
lock_flag = threading.Lock()
###########################################################################
## Class SpiderClient
###########################################################################
import Save_Show_Pic
import KuroNeko_Spider_Server
class SpiderClient ( wx.Frame ):
def __init__( self, parent ):
wx.Frame.__init__ ( self, parent, id = wx.ID_ANY, title = u"KuroNeko-Spider_Client", pos = wx.DefaultPosition, size = wx.Size( 605,755 ), style = wx.DEFAULT_FRAME_STYLE|wx.TAB_TRAVERSAL )
#主窗口
self.toltime = 0
self.SetSizeHints( wx.DefaultSize, wx.DefaultSize )
self.SetBackgroundColour(wx.Colour(255, 255, 168))
bSizer5 = wx.BoxSizer( wx.VERTICAL )
fgSizer7 = wx.FlexGridSizer( 0, 2, 0, 0 )
fgSizer7.SetFlexibleDirection( wx.BOTH )
fgSizer7.SetNonFlexibleGrowMode( wx.FLEX_GROWMODE_SPECIFIED )
self.url_label = wx.StaticText( self, wx.ID_ANY, u"By KuroNeko", wx.DefaultPosition, wx.Size( 100,-1 ), 0 )#地址栏标签
self.url_label.Wrap( -1 )
self.url_label.SetFont( wx.Font( 12, 70, 90, 90, False, "Tempus Sans ITC" ) )
fgSizer7.Add( self.url_label, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.movie_url = wx.TextCtrl( self, wx.ID_ANY, u"豆瓣电影————https://movie.douban.com/", wx.DefaultPosition, wx.Size( 400,-1 ), wx.TE_READONLY )#地址栏文本框
self.movie_url.SetBackgroundColour(wx.Colour(255, 255, 168))
self.movie_url.SetFont(wx.Font(12, 70, 90, 90, False, "Tempus Sans ITC"))
fgSizer7.Add( self.movie_url, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
bSizer5.Add( fgSizer7, 0, 0, 5 )
fgSizer2 = wx.FlexGridSizer( 0, 8, 0, 0 )
fgSizer2.SetFlexibleDirection( wx.BOTH )
fgSizer2.SetNonFlexibleGrowMode( wx.FLEX_GROWMODE_SPECIFIED )
self.type_label = wx.StaticText( self, wx.ID_ANY, u"类别:", wx.DefaultPosition, wx.DefaultSize, 0 )#类别标签
self.type_label.Wrap( -1 )
self.type_label.SetFont( wx.Font( 12, 70, 90, 90, False, "黑体" ) )
fgSizer2.Add( self.type_label, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
#电影分类下拉框
movie_typeChoices = [ u"热门", u"最新", u"经典", u"可播放", u"豆瓣高分", u"冷门佳片", u"华语", u"欧美", u"韩国",u"日本", u"动作", u"喜剧", u"爱情", u"科幻", u"悬疑", u"恐怖", u"动画" ]
self.movie_type = wx.Choice( self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, movie_typeChoices, 0 )
self.movie_type.SetSelection( 0 )
self.movie_type.SetFont( wx.Font( 11, 70, 90, 90, False, "幼圆" ) )
self.movie_type.SetBackgroundColour(wx.Colour(165, 253, 142))
self.movie_type.SetForegroundColour(wx.Colour(243, 31, 222))
fgSizer2.Add( self.movie_type, 0, wx.ALL|wx.ALIGN_CENTER_VERTICAL|wx.ALIGN_CENTER_HORIZONTAL, 5 )
self.sort_way = wx.StaticText( self, wx.ID_ANY, u"排序:", wx.DefaultPosition, wx.DefaultSize, 0 )#排序方式标签
self.sort_way.Wrap( -1 )
self.sort_way.SetFont( wx.Font( 12, 70, 90, 90, False, "黑体" ) )
fgSizer2.Add( self.sort_way, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
movie_sortChoices = [ u"热度", u"时间", u"评价" ]#排序方式下拉框
self.movie_sort = wx.Choice( self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, movie_sortChoices, 0 )
self.movie_sort.SetSelection( 0 )
self.movie_sort.SetFont( wx.Font( 11, 70, 90, 90, False, "幼圆" ) )
self.movie_sort.SetBackgroundColour(wx.Colour(255, 255, 168))
self.movie_sort.SetForegroundColour(wx.Colour(243, 31, 222))
fgSizer2.Add( self.movie_sort, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.thread_label = wx.StaticText( self, wx.ID_ANY, u"线程数:", wx.DefaultPosition, wx.DefaultSize, 0 )#线程数标签
self.thread_label.Wrap( -1 )
self.thread_label.SetFont( wx.Font( 12, 70, 90, 90, False, "黑体" ) )
fgSizer2.Add( self.thread_label, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
threadNumChoices = [ u"1", u"2", u"3", u"4", u"5",u"6",u"7" ]#线程数量下拉框
self.threadNum = wx.Choice( self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, threadNumChoices, 0 )
self.threadNum.SetSelection( 2 )#初始化下拉选项
self.threadNum.SetFont(wx.Font(13, 70, 90, 92, False, "幼圆"))
self.threadNum.SetForegroundColour(wx.Colour(243, 31, 222))
self.threadNum.SetBackgroundColour(wx.Colour(192, 243, 241))
fgSizer2.Add( self.threadNum, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.page_label = wx.StaticText( self, wx.ID_ANY, u"页数:", wx.DefaultPosition, wx.DefaultSize, 0 )#页数标签
self.page_label.Wrap( -1 )
self.page_label.SetFont( wx.Font( 12, 70, 90, 90, False, "黑体" ) )
fgSizer2.Add( self.page_label, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.pageNum = wx.TextCtrl( self, wx.ID_ANY, "1", wx.DefaultPosition, wx.Size( 35,-1 ), wx.TE_CENTRE )#输入页数文本框
fgSizer2.Add( self.pageNum, 0, wx.ALL, 5 )
bSizer5.Add( fgSizer2, 0, 0, 5 )
fgSizer3 = wx.FlexGridSizer( 0, 5, 0, 0 )
fgSizer3.SetFlexibleDirection( wx.BOTH )
fgSizer3.SetNonFlexibleGrowMode( wx.FLEX_GROWMODE_SPECIFIED )
self.get_way = wx.StaticText(self, wx.ID_ANY, u"执行方式:", wx.DefaultPosition, wx.DefaultSize, 0)
self.get_way.Wrap(-1)
self.get_way.SetFont(wx.Font(12, 70, 90, 90, False, "黑体"))
fgSizer3.Add(self.get_way, 0, wx.ALL | wx.ALIGN_CENTER_HORIZONTAL | wx.ALIGN_CENTER_VERTICAL, 5)
query_typeChoices = [u"快速爬虫", u"完整爬虫"]
self.query_type = wx.Choice(self, wx.ID_ANY, wx.DefaultPosition, wx.DefaultSize, query_typeChoices, 0)
self.query_type.SetSelection(0)
self.query_type.SetFont(wx.Font(12, 70, 90, 90, False, "幼圆"))
self.query_type.SetForegroundColour(wx.Colour(255, 0, 0))
self.query_type.SetBackgroundColour(wx.Colour(228, 202, 255))
fgSizer3.Add(self.query_type, 0, wx.ALL | wx.ALIGN_CENTER_HORIZONTAL | wx.ALIGN_CENTER_VERTICAL, 5)
self.start = wx.Button( self, wx.ID_ANY, u"开始爬虫✔", wx.DefaultPosition, wx.DefaultSize, wx.NO_BORDER )#启动爬虫按钮start
self.start.SetFont( wx.Font( 12, 70, 90, 90, False, "幼圆" ) )
self.start.SetBackgroundColour(wx.Colour(165, 253, 142))
self.start.SetForegroundColour(wx.Colour(243, 31, 222))
fgSizer3.Add( self.start, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.export = wx.Button( self, wx.ID_ANY, u"导出数据♋", wx.DefaultPosition, wx.DefaultSize, wx.NO_BORDER )#导出数据按钮export
self.export.SetFont( wx.Font( 12, 70, 90, 90, False, "幼圆" ) )
self.export.SetBackgroundColour(wx.Colour(183, 245, 253))
self.export.SetForegroundColour(wx.Colour(243, 31, 222))
fgSizer3.Add( self.export, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.analyze = wx.Button( self, wx.ID_ANY, u"数据分析图♐", wx.DefaultPosition, wx.DefaultSize, wx.NO_BORDER )#分析数据按钮analyze
self.analyze.SetFont( wx.Font( 12, 70, 90, 90, False, "幼圆" ) )
self.analyze.SetForegroundColour(wx.Colour(177, 37, 218))
self.analyze.SetBackgroundColour(wx.Colour(255, 187, 119))
fgSizer3.Add( self.analyze, 0, wx.ALL|wx.ALIGN_CENTER_VERTICAL|wx.ALIGN_CENTER_HORIZONTAL, 5 )
self.analyze2 = wx.Button(self, wx.ID_ANY, u"线程散点图♌", wx.DefaultPosition, wx.DefaultSize, wx.NO_BORDER) # 分析数据按钮analyze
self.analyze2.SetFont(wx.Font(12, 70, 90, 90, False, "幼圆"))
self.analyze2.SetForegroundColour(wx.Colour(255, 0, 0))
self.analyze2.SetBackgroundColour(wx.Colour(228, 202, 255))
fgSizer3.Add(self.analyze2, 0, wx.ALL | wx.ALIGN_CENTER_VERTICAL | wx.ALIGN_CENTER_HORIZONTAL, 5)
self.clear = wx.Button(self, wx.ID_ANY, u"✘清空✘", wx.DefaultPosition, wx.DefaultSize,
wx.NO_BORDER)
self.clear.SetFont(wx.Font(12, 70, 90, 90, False, "幼圆"))
self.clear.SetForegroundColour(wx.Colour(255, 0, 0))
self.clear.SetBackgroundColour(wx.Colour(255, 255, 168))
fgSizer3.Add(self.clear, 0, wx.ALL | wx.ALIGN_CENTER_VERTICAL | wx.ALIGN_CENTER_HORIZONTAL, 5)
bSizer5.Add( fgSizer3, 0, 0, 5 )
fgSizer4 = wx.FlexGridSizer( 0, 1, 0, 0 )
fgSizer4.SetFlexibleDirection( wx.BOTH )
fgSizer4.SetNonFlexibleGrowMode( wx.FLEX_GROWMODE_SPECIFIED )
self.log_text = wx.TextCtrl( self, wx.ID_ANY, wx.EmptyString, wx.DefaultPosition, wx.Size( 575,520 ), wx.TE_MULTILINE )
fgSizer4.Add( self.log_text, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL|wx.ALIGN_CENTER_VERTICAL, 5 )
self.log_text.SetFont(wx.Font(9, 75, 90, 90, False, "微软雅黑"))
self.log_text.SetBackgroundColour(wx.Colour(211, 243, 203))
bSizer5.Add( fgSizer4, 0, 0, 5 )
self.m_staticText_select = wx.StaticText(self, wx.ID_ANY, u"选择内容:",(70,400), wx.DefaultSize, 0) # 内容标签
self.m_staticText_select.Wrap(-1)
self.m_staticText_select.SetFont(wx.Font(12, 70, 90, 90, False, "黑体"))
fgSizer2.Add(self.m_staticText_select, 0, wx.ALL | wx.ALIGN_CENTER_HORIZONTAL | wx.ALIGN_CENTER_VERTICAL, 5)
self.turn_off=wx.CheckBox(self,label="关灯",pos=(530,25))
self.turn_off.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.turn_off.SetForegroundColour(wx.Colour(0,0,0))
self.turn_off.Bind(wx.EVT_CHECKBOX,self.onChecked)#关灯事件监听
self.movie_name_check = wx.CheckBox(self, label='电影名', pos=(100,75))
self.movie_name_check.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.movie_name_check.SetForegroundColour(wx.Colour( 255, 0, 0 ))
self.movie_comment_check = wx.CheckBox(self, label='评论', pos=(180,75))
self.movie_comment_check.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.movie_comment_check.SetForegroundColour(wx.Colour( 255, 128, 0 ))
self.movie_director_check = wx.CheckBox(self, label='导演', pos=(240,75))
self.movie_director_check.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.movie_director_check.SetForegroundColour(wx.Colour( 6, 18, 249 ))
self.movie_actor_check = wx.CheckBox(self, label='主演', pos=(310,75))
self.movie_actor_check.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.movie_actor_check.SetForegroundColour(wx.Colour( 0, 128, 0 ))
self.movie_discussion_check = wx.CheckBox(self, label='论坛讨论', pos=(390,75))
self.movie_discussion_check.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.movie_discussion_check.SetForegroundColour(wx.Colour( 7, 170, 248 ))
self.movie_anothername_check = wx.CheckBox(self, label='电影别名', pos=(480,75))
self.movie_anothername_check.SetFont(wx.Font(10, 70, 90, 90, False, "黑体"))
self.movie_anothername_check.SetForegroundColour(wx.Colour( 128, 0, 255 ))
self.movie_name_check.SetValue(1)
self.movie_comment_check.SetValue(1)
self.movie_director_check.SetValue(1)
self.movie_actor_check.SetValue(1)
self.movie_discussion_check.SetValue(1)
self.movie_anothername_check.SetValue(1)
self.SetSizer( bSizer5 )
self.Layout()
self.Centre( wx.BOTH )
# Connect Events
self.start.Bind( wx.EVT_BUTTON, self.startSpider )#点击触发事件,此处是调用类中开始爬虫函数事件
self.export.Bind( wx.EVT_BUTTON, self.exportData )#导出事件监听
self.analyze.Bind( wx.EVT_BUTTON, self.analyzeData )#电影数据分析监听
self.analyze2.Bind( wx.EVT_BUTTON, self.analyzeData2 )#日志数据分析监听
self.clear.Bind(wx.EVT_BUTTON,self.Clear_log)
#movie_type [ u"热门", u"最新", u"经典", u"可播放", u"豆瓣高分", u"冷门佳片", u"华语", u"欧美", u"韩国",u"日本", u"动作", u"喜剧", u"爱情", u"科幻", u"悬疑", u"恐怖", u"动画" ]
self.movie_type_list = [
'%E7%83%AD%E9%97%A8',
'%E6%9C%80%E6%96%B0',
'%E7%BB%8F%E5%85%B8',
'%E5%8F%AF%E6%92%AD%E6%94%BE',
'%E8%B1%86%E7%93%A3%E9%AB%98%E5%88%86',
'%E5%86%B7%E9%97%A8%E4%BD%B3%E7%89%87',
'%E5%8D%8E%E8%AF%AD',
'%E6%AC%A7%E7%BE%8E',
'%E9%9F%A9%E5%9B%BD',
'%E6%97%A5%E6%9C%AC',
'%E5%8A%A8%E4%BD%9C',
'%E5%96%9C%E5%89%A7',
'%E7%88%B1%E6%83%85',
'%E7%A7%91%E5%B9%BB',
'%E6%82%AC%E7%96%91',
'%E6%81%90%E6%80%96',
'%E5%8A%A8%E7%94%BB'
]
#movie_sort
self.movie_sort_list = ['recommend','time','rank']
self.log_text.SetForegroundColour(wx.Colour(24, 50, 226))
self.log_text.AppendText('>>>>>>>>>>>>>>>>\n')
self.log_text.AppendText('(๑°3°๑)小可爱正在满世界找服务器(。>∀<。)...\n')
self.s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
try:
self.s.connect(('localhost',12306))
self.log_text.AppendText("\n找到辣辣辣辣get!٩( 'ω' )و !!!!!!!\n")
self.log_text.AppendText("<<<<<<<<<<<<<<<<\n")
except:
self.s = None
print("error:没找到服务器,可能你没开")
self.log_text.AppendText("\n(╯‵□′)╯︵┴─┴ ...\n")
self.log_text.AppendText("┴─┴︵╰(‵□′╰) ...\n")
self.log_text.AppendText("竟然没找到!!!∑(°Д°ノ)ノ!!!等会儿再试试(ó﹏ò。)\n")
self.log_text.AppendText("<<<<<<<<<<<<<<<<\n")
return
以上是客户端界面的标签及功能按键的位置布置
以下即客户端各部分功能实现:
以下代码包括:
1.清空数据显示文本框
2.关灯
3.启动爬虫程序
def __del__( self ):
pass
def Clear_log(self,e):#清空内容显示文本框
self.log_text.Clear()
def onChecked(self,e):#关灯
flag=self.turn_off.GetValue()
if flag:
self.SetBackgroundColour(wx.Colour(64, 64, 64))
self.log_text.SetBackgroundColour(wx.Colour(96, 96, 96))
self.movie_url.SetBackgroundColour(wx.Colour(264, 64, 64))
else:
self.SetBackgroundColour(wx.Colour(255, 255, 168))
self.log_text.SetBackgroundColour(wx.Colour(211, 243, 203))
self.movie_url.SetBackgroundColour(wx.Colour(255, 255, 168))
# Virtual event handlers, overide them in your derived class
def startSpider( self, event ):#点击并开始爬虫,此事件仅仅是为开始爬虫做准备,包括爬虫要求的整理,服务器的链接校验,直到最后才调用了真正启动爬虫的线程
page_info = []#用于收集要传送的到爬虫服务器的选择信息
if self.pageNum.GetValue() == "":#若未能获取到爬取页数,显示错误提示
wx.MessageBox('请输入页数',caption="错误提示")
return
if int(self.pageNum.GetValue()) <= 0:#若输入页数格式错误,显示错误提示
wx.MessageBox('页数应该大于0',caption="错误提示")
return
if self.s == None:#若链接超时则重新链接
self.log_text.AppendText('>>>>>>>>>>>>>>>>\n')
self.log_text.AppendText('(๑°3°๑)小可爱又在满世界找服务器(。>∀<。)...\n')
self.s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
try:
self.s.connect(('localhost',12306))
self.log_text.AppendText("\n找到辣辣辣辣get!٩( 'ω' )و !!!!!!!\n")
self.log_text.AppendText("<<<<<<<<<<<<<<<<\n")
except:
self.log_text.SetForegroundColour(wx.Colour(255, 0, 0))
self.s = None
print("error:没找到服务器,可能你没开")
self.log_text.AppendText("\n(╯‵□′)╯︵┴─┴ ...\n")
self.log_text.AppendText("┴─┴︵╰(‵□′╰) ...\n")
self.log_text.AppendText("竟然没找到!!!∑(°Д°ノ)ノ!!!快去检查服务器开没(ó﹏ò。)\n")
self.log_text.AppendText("<<<<<<<<<<<<<<<<\n")
return
movie_type = self.movie_type_list[self.movie_type.GetSelection()]#获取输入的电影标签
movie_sort = self.movie_sort_list[self.movie_sort.GetSelection()]#获取输入的排序方式
threadNum = self.threadNum.GetString(self.threadNum.GetSelection())#获取输入的线程数
pageNum = self.pageNum.GetValue()#获取输入的页数
query_type = self.query_type.GetSelection()#获取爬取方式
print('标签:',movie_type)#标签
print('排序方式:',movie_sort)#排序方式
print('线程数:',threadNum)#线程数
print('页数:',pageNum)#页数
print('爬虫方式:',query_type)#采集方式
# page_info[movie_type,movie_sort,threadNum,pageNum,query_type]
page_info.append(movie_type)#全部打包到要发送的List中
page_info.append(movie_sort)
page_info.append(threadNum)
page_info.append(pageNum)
page_info.append(query_type)
page_info.append(self.movie_name_check.GetValue())#复选框信息
page_info.append(self.movie_director_check.GetValue())
page_info.append(self.movie_actor_check.GetValue())
page_info.append(self.movie_anothername_check.GetValue())
page_info.append(self.movie_comment_check.GetValue())
page_info.append(self.movie_discussion_check.GetValue())
threading.Thread(target=self.showLog,args=(page_info,)).start()#开启新线程调用爬虫程序
此处将用户要求打包通过socket发送到服务器端,之后监听服务器端回传的消息
def showLog(self,page_info):#真正开始爬虫的函数
try:
starttime = datetime.datetime.now()#起始时间
self.s.sendall(pickle.dumps(page_info))#转化为byte传输
flag = 0#返回的线程计数
num=0
self.log_text.SetForegroundColour(wx.Colour(255, 128, 0))
while True:
recv_data=self.s.recv(10240).decode()#接收并转码
print(recv_data)
if recv_data == "end":#结束标志
flag = flag+1#当一个线程返回end时表示线程结束,所有线程结束时退出循环
print(flag,page_info[2])
if flag == int(page_info[2]):
self.log_text.SetForegroundColour(wx.Colour(128, 0, 255))#结束爬取标志颜色
self.log_text.AppendText(recv_data)#在图形界面中显示结束标志
break
continue
self.log_text.AppendText(recv_data)#在图形界面中显示电影信息
num=num+1
endtime = datetime.datetime.now()#结束时间
self.toltime = (endtime - starttime).seconds
self.log_text.AppendText("\n运行耗时:"+str(self.toltime)+"s\n")
Clientlog = open('spider_log.txt', 'ba+')#写入日志
Clientlog.write(str("\t*****爬虫日志*****\t\n").encode('utf-8'))
Clientlog.write(str("[开始时间]"+str(starttime.strftime('%Y/%m/%d %H:%M:%S'))+'\n').encode('utf-8'))
Clientlog.write(str("[结束时间]"+str(endtime.strftime('%Y/%m/%d %H:%M:%S'))+'\n').encode('utf-8'))
Clientlog.write(str("[线程数]"+str(page_info[2])+'\n').encode('utf-8'))
Clientlog.write(str("[爬取数据量]"+str(num)+'\n').encode('utf-8'));
Clientlog.write(str("[总耗时]"+str((endtime - starttime).seconds)+'s\n').encode('utf-8'))
conn = pymysql.connect(host='localhost',user='root',password='970922',db='mytest',port=3306,charset='utf8')
cur = conn.cursor()
sql = 'insert into data_log values(null ,"%s","%s","%s")' % (num,(endtime - starttime).seconds,page_info[2])
cur.execute(sql)
conn.commit()
except:
wx.MessageBox('采集启动失败!!!',caption="错误提示")
self.s.close()#注意这个链接是爬完一次就直接关掉的,而不是被归到except下面,否则会直接导致第二次爬虫无限等待因为上一次爬虫仍然占用原端口
self.s = None
4.导出数据功能,即读取本地数据库信息并写入到Excel表格中
def exportData( self, event ):#导出数据库中电影信息
savePath = self.GetDesktopPath()+"\\豆瓣电影信息.xls"
threading.Thread(target=self.writeXls,args=(savePath,)).start()#线程写入Excel表格
def writeXls(self ,file_name):#写入Excel表格
movie_list = ['上映年份','片名','导演','编剧','主演','类型','制片国家地区','语言','又名','上映日期','片长','IMDB链接/影片地址','评分','评价人数','页面网址','短评','话题']
xls = ExcelWrite.Workbook()
sheet = xls.add_sheet("Sheet1")#写入表1
style = XFStyle()
pattern = Pattern() # 创建一个模式
pattern.pattern = Pattern.SOLID_PATTERN # 设置其模式为实型
pattern.pattern_fore_colour = 0x16 #设置其模式单元格背景色
# 设置单元格背景颜色 0 = Black, 1 = White, 2 = Red, 3 = Green, 4 = Blue, 5 = Yellow, 6 = Magenta, the list goes on...
style.pattern = pattern
for i in range(len(movie_list)):#写入首行信息,为表头,表示列名
sheet.write(0,i,movie_list[i],style)
sheet.col(i).width = 5240
actors_list=['姓名','性别','星座','年龄','出生地','职业','简介']
sheet2=xls.add_sheet("Sheet2")
style2 = XFStyle()
style2.pattern = pattern
for i in range(len(actors_list)): # 写入首行信息,为表头,表示列名
sheet2.write(0, i, actors_list[i], style2)
sheet2.col(i).width = 5140
try:
#连接数据库读取数据
conn = pymysql.connect(host='localhost',user='root',password='970922',db='mytest',port=3306,charset='utf8')
cur = conn.cursor()
sql = 'select * from movies'
cur.execute(sql)
row = 0
for movie_info in cur.fetchall():#遍历数据库中每行信息,一行表示一部电影的所有信息
row = row+1#第0行为表头,不添加数据,因此从第一列开始写入
for i in range(len(movie_info)-1):#对于一行信息进行遍历,分别存入每列
sheet.write(row,i,movie_info[i+1])
sql = "select id,name,sex,star,date_format(from_days(to_days(now())-to_days(birthday)),'%Y')+0,place,job,message from actors"
cur.execute(sql)
row = 0
for actor_info in cur.fetchall(): # 遍历数据库中每行信息,一行表示一部电影的所有信息
row = row + 1 # 第0行为表头,不添加数据,因此从第一列开始写入
for i in range(len(actor_info) - 1): # 对于一行信息进行遍历,分别存入每列
sheet2.write(row, i, actor_info[i + 1])
xls.save(file_name)#写入完成,存储
cur.close()
conn.close()
wx.MessageBox('数据已导出到桌面!!!',caption="导出成功")
except:
wx.MessageBox('数据导出失败!!!',caption="导出失败")
5.数据分析功能,可以分析电影信息以及爬虫日志
def analyzeData( self, event ):#分析数据,参数为调用 <统计电影类型数量> 的函数
self.matplotlib_show(self.count_type())
def analyzeData2(self, event ):#分析数据2,日志信息散点图
self.matplotlib_show2()
def GetDesktopPath(self):#获取桌面路径
return os.path.join(os.path.expanduser("~"), 'Desktop')
def count_type(self):#统计电影类型数量
conn = pymysql.connect(host='localhost',user='root',password='970922',db='mytest',port=3306,charset='utf8')
#从数据库中获取数据
cur = conn.cursor()
sql = 'select movie_type from movies'#只查询电影0类型
cur.execute(sql)
movie_type_list = []#存储已知的电影类型
movie_count_type = dict()#定义字典,表示电影类型对应的数量
for movie_type_row in cur.fetchall():#遍历查询结果
movie_types = movie_type_row[0]#获取该电影属于哪些分类
# print(movie_types)
movie_type_list += movie_types.split("/")#因为一部电影可能属于多种分类,因此用分隔符 ‘/’ 分开,然后将得到的list全部加入类型list中
for movie_type in movie_type_list:#最后将收集到的所有类型进行字典计数
if movie_type not in movie_count_type:#如果是字典中不存在的类型,那么计数为初始计数为1
movie_count_type[movie_type] = 1
else:
movie_count_type[movie_type] += 1#否则计数加1
print(movie_count_type)#输出统计结果
return movie_count_type#返回字典
def matplotlib_show(self,movie_count_type):#饼状图、直方图
#指定默认字体
plt.cla()
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family']='sans-serif'
matplotlib.rcParams['axes.unicode_minus'] = False
count = []#数量
category = []#类型
for movie_type in movie_count_type:#遍历电影类型计数
count.append(movie_count_type[movie_type])
category.append(str(movie_type))
new_count=count
y_pos = np.arange(len(category))
plt.bar(y_pos, count, align='center', alpha=0.7)
plt.xticks(y_pos, category)
for count, y_pos in zip(count, y_pos):
plt.text(y_pos, count+0.5, count, horizontalalignment='center', verticalalignment='center', weight='bold')
plt.title('电影类别数据分析')#图标标题
plt.xlabel(u'电影分类')
plt.subplots_adjust(bottom = 0.15)
plt.ylabel(u'分类出现次数')
try:
savePath = self.GetDesktopPath() + "\\电影类别数据直方图.png" # 将结果图存储到桌面
plt.savefig(savePath)
showDataPic = Save_Show_Pic.ShowDataPic(None,openPath=savePath)
showDataPic.Show(True)
# wx.MessageBox('数据图已导出到桌面!!!', caption="导出成功")
except:
wx.MessageBox('数据图导出失败!!!', caption="导出失败")
plt.cla()
sum_count = sum(new_count)
sizes = []
for it in new_count:
sizes.append(it / sum_count)
plt.pie(sizes, explode=list(0.1 for x in range(len(sizes))), labels=category, autopct="%.2f%%", shadow=True, startangle=90)
plt.title(r'电影类型比例饼状图', fontproperties="SimHei", fontsize=15)
try:
savePath = self.GetDesktopPath() + "\\电影类别数据饼状图.png" # 将结果图存储到桌面
plt.savefig(savePath)
showDataPic2 = Save_Show_Pic.ShowDataPic(None,openPath=savePath)
showDataPic2.Show(True)
wx.MessageBox('数据图已导出到桌面!!!', caption="导出成功")
except:
wx.MessageBox('数据图导出失败!!!', caption="导出失败")
def matplotlib_show2(self):#散点图
conn = pymysql.connect(host='localhost', user='root', password='970922', db='mytest', port=3306, charset='utf8')
# 从数据库中获取数据
cur = conn.cursor()
sql = 'select thread_num,times from data_log where data_num>=40 and data_num<=42' # 查询爬取相同数据下,线程与时间关系
cur.execute(sql)
thread_nums=[]
time_cnt=[]
for it in cur.fetchall():
thread_nums.append(it[0])
time_cnt.append(it[1])
plt.cla()
matplotlib.rcParams['font.sans-serif'] = ['SimHei']
matplotlib.rcParams['font.family'] = 'sans-serif'
plt.title(r'线程数-时间散点图(数据量为40~42时)', fontproperties="SimHei", fontsize=15)
plt.xlabel('线程数量')
plt.ylabel('时间')
plt.xlim(0, 6)
plt.scatter(thread_nums, time_cnt, s=20, c="#ff1212", marker='*')
try:
savePath = self.GetDesktopPath() + "\\线程-时间数据散点图.png" # 将结果图存储到桌面
plt.savefig(savePath)
showDataPic2 = Save_Show_Pic.ShowDataPic(None, openPath=savePath)
showDataPic2.Show(True)
# wx.MessageBox('数据图已导出到桌面!!!', caption="导出成功")
except:
wx.MessageBox('数据图导出失败!!!', caption="导出失败")
sql = 'select data_num,times from data_log where thread_num=3' # 查询爬取相同数据下,线程与时间关系
cur.execute(sql)
data_cnt = []
time_cnt2 = []
for it in cur.fetchall():
data_cnt.append(it[0])
time_cnt2.append(it[1])
# print(it)
plt.cla()
plt.title(r'数量-时间散点图(同为3线程数)', fontproperties="SimHei", fontsize=15)
plt.xlabel('电影数量')
plt.ylabel('时间')
plt.xlim(0, 100)
plt.scatter(data_cnt, time_cnt2, s=20, c="#ff1212", marker='+')
try:
savePath = self.GetDesktopPath() + "\\数量-时间数据散点图.png" # 将结果图存储到桌面
plt.savefig(savePath)
showDataPic2 = Save_Show_Pic.ShowDataPic(None, openPath=savePath)
showDataPic2.Show(True)
wx.MessageBox('数据图已导出到桌面!!!', caption="导出成功")
except:
wx.MessageBox('数据图导出失败!!!', caption="导出失败")
if __name__=='__main__':#测试
app = wx.App()
spiderClient = SpiderClient(None)
spiderClient.Show()
app.MainLoop()
2.客户端结构
选择相应爬虫要求,包括爬取类型,排序方式,线程数,页数等信息。点击“启动”开始爬虫,点击“导出数据”将读取数据库内容生成Excel表格。点击“数据分析图”将读取数据库信息,分析整理后制作电影类型饼状图与直方图,点击“线程散点图”将读取数据库信息,制作线程与数据量与时间关系散点图。
客户端在点击启动后将获取所有用户填写的爬虫要求打包成列表,并通过socket发送到服务器端,之后通过socket监听服务器端传回的结果消息,接受结果消息将显示在scrolledtext中汇总。
以上即客户端方面所有内容,
以下介绍服务器端内容:
服务器是等待客户端发送数据的程序,因此一直通过socket监听端口,一旦受到消息就根据要求调用爬虫程序。
import json
import pickle
import socket
import threading
from Spider_Engine import Spider#此处导入爬虫模块,也就是说这个爬虫服务必须先开启,并且客户端是通过爬虫服务器来启动和获取爬取结果
class SpiderServer(object):
def __init__(self):
pass
def startServer(self):
print("(:з」∠)_服务器:又要起床做事了ヾ(o・ω・)ノ!!!")
s = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
s.bind(('localhost',12306))
s.listen(5)
while True:
conn,addr = s.accept()#conn用于与客户端进行通信
page_info = conn.recv(1024)
if not page_info:
continue
print(pickle.loads(page_info))#输出从客户端发送过来的爬取要求,读取byte
page_info = pickle.loads(page_info)
# page_info[movie_type,movie_sort,threadNum,pageNum,query_type]
threading.Thread(target=Spider().startSpiderInfo,args=(page_info,conn,)).start()#此处启动线程调用了爬虫模块,并用conn作为参数,使得爬虫模块也能直接与客户端进行通信
conn.sendall("服务器:我被找到了(。>∀<。)!!!\n".encode())#以 encoding 指定的编码格式编码字符串
conn.close()
s.close()
#开启服务器
if __name__=='__main__':
s = SpiderServer()
s.startServer()
# function_name: 需要线程去执行的方法名
# threading.Thread()创建线程.start()并启动线程
# args: 线程执行方法接收的参数,该属性是一个元组,如果只有一个参数也需要在末尾加逗号
服务器端只是作为一个爬虫请求的管理功能,并不具备爬虫功能,在需要的时候启动爬虫程序才是服务器的真正功能,并且爬虫程序的结果反馈给客户端也是由服务器端实现,简单的说即只负责通信。
爬虫程序:
初始化部分,包括爬虫程序的头【header】,如果没有头会被网页的反爬机制认出,拒绝访问,并且还要设置相应的时间间隔来防止程序过快的访问页面,被豆瓣反爬机制封掉IP
# encoding=utf-8
# by:KuroNeko
import threading
import urllib.request
import datetime
import pymysql
import json
import time
from lxml import etree
lock = threading.Lock() # 数据库的锁,只允许同时有一个线程操作数据库
lock_num = threading.Lock() # 全局变量,爬取电影的计数锁
NUM = 0
# 爬虫客户端爬取模块
class Spider(object):
# 编辑头。使其不会被网站拦截
def __init__(self):
self.send_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36',
'Referer': 'https://movie.douban.com/explore'
}
self.hotMovieUrl_list = []
self.movieDetailInfo_list = []
global lock
global lock_num
豆瓣电影用户需要分类的列表,主要抓取每个电影详细页面的url地址,以供第二层第三层使用
# 爬取热门电影列表(参数:电影种类,排序方式,页数)【第一层】
def getHotMovieUrlList(self, movie_type, movie_sort, pageNum):
if int(pageNum) > 0: # 当页数大于0时才能爬取
for i in range(int(pageNum)):
print(i) # 输出页数
start = i * 20
url = 'https://movie.douban.com/j/search_subjects?type=movie&tag=' + movie_type + '&sort=' + movie_sort + '&page_limit=20&page_start=' + str(
start)
print(url)
# 使用Request类构建一个完整的请求 增加headers信息
req = urllib.request.Request(url, headers=self.send_headers)
# 打开url获得响应
resp = urllib.request.urlopen(req)
# 接受响应信息
json_data = resp.read().decode('utf-8')
# 将json数据转换成字典
json_obj = json.loads(
json_data) # 转换为字典后,是以列表的方式返回,且这个列表中就一个字典元素:subjects,该字典对应一个列表,这个列表对应一个字典,表示该电影所有信息
for key, value in json_obj.items():
# print(value)
for item in value:
# print(item)#具体电影信息,包括电影名和详细信息的URL地址
hotMovie_dict = {}
hotMovie_dict['url'] = item['url']
self.hotMovieUrl_list.append(hotMovie_dict)
else: # 页数小于等于0直接返回
return False
# 返回id+name的list表
return self.hotMovieUrl_list
第二层网页以及第三层网页的抓取
爬取了电影详细信息【第二层】,主演个人信息【第三层】的数据
# 爬取热门电影详细信息【第二层】
def getMovieDetailInfo(self, movie_url, page_info):
movieDetailInfo_dict = {} # 存储电影详细信息的字典
resp = urllib.request.urlopen(movie_url)
html_data = resp.read().decode('utf-8')
# 构建xpath
html = etree.HTML(html_data)
# movie_year = soup.find('span', class_='year').text.strip('(').strip(')')
movie_year = html.xpath('//*[@id="content"]/h1/span[2]/text()')[0].strip('(').strip(')') # 年份
# print(movie_year)
movieDetailInfo_dict['movie_year'] = movie_year
# movie_name = soup.find('i',class_='').text.split('的')[0]
if (page_info[5]):
movie_name = html.xpath('//*[@id="content"]/h1/span[1]/text()')[0].split(' ')[0] # 电影名
# print(movie_name)
movieDetailInfo_dict['movie_name'] = movie_name
else:
movieDetailInfo_dict['movie_name'] = ""
# movie_director
if (page_info[6]):
movie_director_list = html.xpath('//*[@id="info"]/span[1]/span[2]/a/text()') # 导演
director = ""
for directors in movie_director_list:
director += str(directors) + "/"
movie_director = director.strip('/')
# print(movie_director)
movieDetailInfo_dict['movie_director'] = movie_director
else:
movieDetailInfo_dict['movie_director'] = ""
movie_writer_list = html.xpath('//*[@id="info"]/span[2]/span[2]/a/text()') # 编剧
writer = ""
for writers in movie_writer_list:
writer += str(writers) + "/"
movie_writer = writer.strip('/')
# print(movie_writer)
movieDetailInfo_dict['movie_writer'] = movie_writer
# movie_actor = //*[@id="info"]/span[3]/span[2]
if (page_info[7]):
movie_actor_list = html.xpath('//*[@id="info"]/span[3]/span[2]/a/text()') # 演员
actor = ""
for actors in movie_actor_list:
actor += str(actors) + "/"
movie_actor = actor.strip('/')
# print(movie_actor)
movieDetailInfo_dict['movie_actor'] = movie_actor
else:
movieDetailInfo_dict['movie_actor'] = ""
# movie_type = //*[@id="info"]/span[5]
movie_type_list = html.xpath('//*[@id="info"]/span[@property="v:genre"]/text()') # 类型
type = ""
for types in movie_type_list:
type += str(types) + "/"
movie_type = type.strip('/')
# print(movie_type)
movieDetailInfo_dict['movie_type'] = movie_type
# movie_country = //*[@id="info"]/span[7] //*[@id="info"]/span[8]
movieDetailInfo_dict['movie_anotherName'] = "" # 别名
movieDetailInfo_dict['movie_language'] = "" # 语言
movieDetailInfo_dict['movie_country'] = "" # 国家/地区
movie_attrs = html.xpath('//*[@id="info"]/span[@class="pl"]')
for attr in movie_attrs:
# print(attr.text)
if attr.text == '制片国家/地区:' and page_info[8]:
movie_country = attr.tail.strip()
# print(movie_country)
movieDetailInfo_dict['movie_country'] = movie_country
if attr.text == '语言:':
movie_language = attr.tail.strip()
# print(movie_language)
movieDetailInfo_dict['movie_language'] = movie_language
if attr.text == '又名:':
movie_anotherName = attr.tail.strip()
# print(movie_anotherName)
movieDetailInfo_dict['movie_anotherName'] = movie_anotherName
# movie_date = //*[@id="info"]/span[10]
try:
movie_date = html.xpath('//*[@id="info"]/span[@property="v:initialReleaseDate"]/@content')[0]
# print(movie_date)
movieDetailInfo_dict['movie_date'] = movie_date # 上映日期
except:
movieDetailInfo_dict['movie_date'] = "无上映日期"
try:
# movie_time = v:runtime
movie_time = html.xpath('//*[@id="info"]/span[@property="v:runtime"]/text()')[0]
# print(movie_time)
except:
movie_time = "无片长信息"
movieDetailInfo_dict['movie_time'] = movie_time # 片长
# movie_IMDB = //*[@id="info"]/a
movieDetailInfo_dict['movie_IMDB'] = ""
movie_IMDB = html.xpath('//*[@id="info"]/a[@rel="nofollow" and @target="_blank"]/text()')
if len(movie_IMDB) != 0:
# print(movie_IMDB)
movieDetailInfo_dict['movie_IMDB'] = movie_IMDB[0] # IMDB链接
# movie_grade =
movie_grade = html.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/strong/text()')[0]
# print(movie_grade)
movieDetailInfo_dict['movie_grade'] = movie_grade # 评分
# movie_commentsNum = //*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span
movie_commentsNum = html.xpath('//*[@id="interest_sectl"]/div[1]/div[2]/div/div[2]/a/span/text()')[0]
# print(movie_commentsNum)
movieDetailInfo_dict['movie_commentsNum'] = movie_commentsNum # 评价人数
# movie_pageUrl = movie_url
movie_pageUrl = movie_url
# print(movie_pageUrl)
movieDetailInfo_dict['movie_pageUrl'] = movie_pageUrl # 电影详情页面URL地址
if (page_info[9]):
movieDetailInfo_dict['movie_comment'] = self.get_comments(movie_url + 'comments?status=F') # 短评
else:
movieDetailInfo_dict['movie_comment'] = ""
# print(movieDetailInfo_dict['movie_comment'])
if (page_info[10]):
movieDetailInfo_dict['movie_discussion'] = self.get_discussion(movie_url + 'discussion/') # 论坛
else:
movieDetailInfo_dict['movie_discussion'] = ""
# print(movieDetailInfo_dict['movie_discussion'])
movieDetailInfo_dict['actor_url'] = html.xpath('//*[@id="info"]/span[3]/span[2]/a/@href')
# print(movieDetailInfo_dict['actor_url'])
movieDetailInfo_dict['actor_message'] = []
for it in movieDetailInfo_dict['actor_url']:
if page_info[4]: time.sleep(3)
actor_info = {}
actor_info['name'] = ""
actor_info['sex'] = ""
actor_info['star'] = ""
actor_info['birthday'] = ""
actor_info['place'] = ""
actor_info['job'] = ""
actor_info['message'] = ""
resp2 = urllib.request.urlopen('https://movie.douban.com/' + it)
html_data2 = resp2.read().decode('utf-8')
html2 = etree.HTML(html_data2)
try:
actor_info['name'] = html2.xpath('//*[@id="content"]/h1/text()')[0] # 姓名
actor_info['sex'] = html2.xpath('//*[@id="headline"]/div[2]/ul/li[1]/text()')[1].strip('\n').strip(':').strip() # 性别
actor_info['star'] = html2.xpath('//*[@id="headline"]/div[2]/ul/li[2]/text()')[1].strip('\n').strip(':').strip() # 星座
actor_info['birthday'] = html2.xpath('//*[@id="headline"]/div[2]/ul/li[3]/text()')[1].strip('\n').strip(':').strip() # 生日
actor_info['place'] = html2.xpath('//*[@id="headline"]/div[2]/ul/li[4]/text()')[1].strip('\n').strip(':').strip() # 出生地
actor_info['job'] = html2.xpath('//*[@id="headline"]/div[2]/ul/li[5]/text()')[1].strip('\n').strip(':').strip() # 职业
try:actor_info['message'] = html2.xpath('//*[@id="intro"]/div[2]/span[2]/text()')[0].replace('\u3000',''), replace('\n', '').strip() # 简介
except:actor_info['message'] = html2.xpath('//*[@id="intro"]/div[2]/text()')[0].replace('\u3000','').replace('\n','').strip()
except:
print('https://movie.douban.com/' + it, '无该演员信息')
if actor_info:
movieDetailInfo_dict['actor_message'].append(actor_info)
else:
pass
if page_info[4] == 0: break
print(movieDetailInfo_dict['actor_message'])
return movieDetailInfo_dict
# 爬取结果是字典,表示单部电影的所有详细信息
def get_comments(self, comments_url): # 第一条短评【P为看过,F为想看】
resp = urllib.request.urlopen(comments_url)
html_data = resp.read().decode('utf-8')
# 构建xpath
html = etree.HTML(html_data)
return html.xpath('//*[@id="comments"]/div[1]/div[2]/p/span/text()')[0]
def get_discussion(self, discussion_url): # 论坛第一条题目
resp = urllib.request.urlopen(discussion_url)
html_data = resp.read().decode('utf-8')
# 构建xpath
html = etree.HTML(html_data)
try:
return html.xpath('//*[@id="posts-table"]//tr[2]/td[1]/a/text()')[0].strip('\n').strip()
except:
return "论坛内容为空"
该函数被结果整理函数调用,具体实现了将所有数据存储到本地数据库中,并去重
# 插入数据库
def saveDatabase(self, movie_info, conn):
lock.acquire()
cur = conn.cursor()
# print(movie_info['movie_anotherName'],'='*20)
actor_info = movie_info['actor_message']
for it in actor_info:
sql_select = 'select name from actors where name="%s"' % (it['name'])
cur.execute(sql_select)
conn.commit()
check_name = cur.fetchone()
if check_name == None:
sql_actor = 'insert into actors values(null,"%s","%s","%s","%s","%s","%s","%s")' % (
it['name'], it['sex'], it['star'], it['birthday'], it['place'], it['job'], it['message'])
try:
cur.execute(sql_actor)
conn.commit()
print(it['name'], '保存成功呢')
except:
print('演员信息不完整')
try:
sql_judge = 'select movie_name from movies where movie_name="%s"' % (movie_info['movie_name'])
cur.execute(sql_judge)
conn.commit()
judge_name = cur.fetchone()
if judge_name == None:
sql = 'insert into movies values(null ,"%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")' % (
movie_info['movie_year'], movie_info['movie_name'], movie_info['movie_director'],
movie_info['movie_writer'], movie_info['movie_actor'], movie_info['movie_type'],
movie_info['movie_country'], movie_info['movie_language'], movie_info['movie_anotherName'],
movie_info['movie_date'], movie_info['movie_time'], movie_info['movie_IMDB'],
movie_info['movie_grade'],
movie_info['movie_commentsNum'], movie_info['movie_pageUrl'], movie_info['movie_comment'],
movie_info['movie_discussion'])
cur.execute(sql)
conn.commit()
print("保存成功!!!")
except:
try:
sql_judge = 'select movie_name from movies where movie_name="%s"' % (movie_info['movie_name'])
cur.execute(sql_judge)
conn.commit()
judge_name = cur.fetchone()
if judge_name == None:
sql = 'insert into movies values(null ,"%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s","%s")' % (
movie_info['movie_year'], movie_info['movie_name'], movie_info['movie_director'],
movie_info['movie_writer'], movie_info['movie_actor'], movie_info['movie_type'],
movie_info['movie_country'], movie_info['movie_language'], movie_info['movie_anotherName'],
movie_info['movie_date'], movie_info['movie_time'], movie_info['movie_IMDB'],
movie_info['movie_grade'],
movie_info['movie_commentsNum'], movie_info['movie_pageUrl'], "评论存在emoji或未知编码字符",
movie_info['movie_discussion'])
cur.execute(sql)
conn.commit()
print("保存成功!!!")
except:
print("保存失败!!!")
lock.release()
cur.close()
return movie_info
这是对三层爬取数据结果数据的存储和整理,并通过socket回传给客户端
def getMovieDetailInfo_list(self, movie_urls, connClient, page_info):
conn = pymysql.connect(host='localhost', user='root', password='970922', db='mytest', port=3306, charset='utf8')
for url in movie_urls:
time.sleep(1)
movieDetailInfo = self.getMovieDetailInfo(url['url'], page_info) # 【第二层】爬取详细信息
movie_info = self.saveDatabase(movieDetailInfo, conn) # 存储到数据库中
# movie_info['movie_year'] ,movie_info['movie_name'] ,movie_info['movie_director'] ,movie_info['movie_writer'] ,movie_info['movie_actor'] ,movie_info['movie_type'] ,movie_info['movie_country'] , movie_info['movie_language'] ,movie_info['movie_anotherName'] , movie_info['movie_date'] ,movie_info['movie_time'] ,movie_info['movie_IMDB'] ,movie_info['movie_grade'] ,movie_info['movie_commentsNum'] ,movie_info['movie_pageUrl']
lock_num.acquire()
global NUM
NUM = NUM + 1
num = NUM # 从这里开始构建返回到客户端的信息
movie_msg = '爬取的第' + str(num) + '条电影信息\n'
movie_msg += '|' + '>' * 60 + '|\n'
movie_msg += '【上映年份】' + movie_info['movie_year'] + '\n【片名】' + movie_info['movie_name'] + '\n【导演】' + \
movie_info['movie_director'] + '\n【编剧】' + movie_info['movie_writer'] + '\n【主演】' + movie_info[
'movie_actor'] + '\n【类型】' + movie_info['movie_type'] + '\n【制片国家地区】' + movie_info[
'movie_country'] + '\n【语言】' + movie_info['movie_language'] + '\n【上映日期】' + movie_info[
'movie_date'] + '\n【片长】' + movie_info['movie_time'] + '\n【又名】' + movie_info[
'movie_anotherName'] + '\n【IMDB链接】' + movie_info['movie_IMDB'] + '\n【评分】' + movie_info[
'movie_grade'] + '\n【评价人数】' + movie_info['movie_commentsNum'] + '\n【页面网址】' + movie_info[
'movie_pageUrl'] + '\n【短评】' + movie_info['movie_comment'] + '\n【论坛讨论】' + movie_info[
'movie_discussion'] + '\n'
movie_msg += '|' + '<' * 60 + '|\n'
print(movie_msg)
lock_num.release()
threading.Thread(target=connClient.sendall, args=(movie_msg.encode(),)).start() # 启动线程发送回客户端显示
print(movie_urls.index(url))
print('结束')
connClient.sendall("end".encode()) # 一个线程的结束
conn.close()
这是被服务器端调用的开始函数,肩负了第一层爬虫的调用以及第二层多线程爬取数据的数量分配
# page_info[movie_type,movie_sort,threadNum,pageNum,query_type]
def startSpiderInfo(self, page_info, connClient): # 此处是被服务器端启动的爬虫线程
# print(page_info)
global NUM
NUM=0
urls = self.getHotMovieUrlList(page_info[0], page_info[1], page_info[3]) # 首先爬取电影列表【第一层】
print(urls) # 返回要爬取详细信息的电影URL列表,是以字典形式存储
for i in range(int(page_info[2])): # page_info[2]就是线程数
time.sleep(1)
leng = len(urls)
movie_urls = urls[i * leng // int(page_info[2]):(i + 1) * leng // int(page_info[2])] # 切片操作,为每个线程平均分配要爬的电影url
threading.Thread(target=self.getMovieDetailInfo_list, args=(movie_urls, connClient, page_info,)).start()
# 创建并启动线程,调用获取电影详细信息【第二层】
实现结果:

- 服务器端结构
服务器端作为后台程序状态不显示在客户端中,其结构实现了对客户端访问的监听,并根据指令开始爬虫程序。
在客户端发送启动爬虫的指令并发送要求的数据包后,服务器端监听收到消息,并调用spider爬虫主程序。Spider程序中将获取豆瓣电影主页面作为入口地址,并使用单线程获取主页面上所有待爬电影的url地址,存储在列表中。
接着遍历该列表,将列表中电影总数平均分成线程数的份数,每个线程被分配到:电影总数/线程数 个电影进行详细页面爬取。
在每个线程上,单独对多个电影页面进行爬取,获得的信息存储到字典中,并经过函数整理打包成字符串回传给客户端,并在滑动文本框中显示
在回传给客户端之前,服务器端完成了对数据的爬取,分类整理,调用存储函数链接数据库将数据插入到数据库中。并将存储状态,返回给客户端。
在结束所有数据爬取后,返回end标志给客户端,客户端计算整个爬虫过程所用时间。并反馈到scrolledtext上,最终记录整个爬虫过程的所有数据写入日志文件中。并连接数据库将相关日志信息插入库中。
其中爬取方式有快速爬取及完整爬取,用于对第三层演员个人信息的爬取控制。若选择简单快速爬取,对于一部电影只采集第一位主演的个人信息,考虑到豆瓣网所收集的主演信息并不完整,因此靠后的主演个人信息内容可用性并不高,并且内容缺乏严重,同时,因为对同一部电影深入第三层快速进入多个演职员的个人信息页面,容易触发豆瓣网站的反爬机制,封锁IP,因此若是完整爬取需要对爬取速度进行间歇性暂停控制,这样就造成了完整爬取大量演职员信息时耗费更多时间。考虑到对内容质量以及爬取效率的优化,建议用户使用快速爬取,当然也可以根据个人需要选择完整爬取
最后,在数据插入部分,无论是电影信息还是演职员表信息,都对数据进行了重复检测,以防止大量重复数据被在多次爬取时重复插入。
数据分析图的绘制在客户端中已经写有,以下是对分析的图存储到桌面的过程
# -*- coding: utf-8 -*-
#by KuroNeko
import base64
import os
import wx
from wx.lib.embeddedimage import PyEmbeddedImage
class ShowDataPic ( wx.Frame ):
def __init__( self, parent ,openPath):#路径参数作为文件名可以直接区分不同的图,以达到重用该存储类
wx.Frame.__init__ ( self, parent,title = openPath)
self.SetBackgroundColour( wx.SystemSettings.GetColour( wx.SYS_COLOUR_3DLIGHT ) )
bSizer1 = wx.BoxSizer( wx.VERTICAL )
# openPath = self.GetDesktopPath()+"\\电影类别数据分析图.png"#在客户端函数中已经存储了一张图片,现在将结果写入
file = open(openPath, 'rb')
str = file.read()
b64 = base64.b64encode(str)
file.close()
bitmap = PyEmbeddedImage(b64).GetBitmap()
self.m_bitmap1 = wx.StaticBitmap( self, wx.ID_ANY, bitmap )
bSizer1.Add( self.m_bitmap1, 0, wx.ALL|wx.ALIGN_CENTER_HORIZONTAL, 5 )
self.SetSizer( bSizer1 )
self.Layout()
bSizer1.Fit( self )
self.Centre( wx.BOTH )
def GetDesktopPath(self):#再次定义桌面路径
return os.path.join(os.path.expanduser("~"), 'Desktop')
if __name__=='__main__':
app = wx.App()
gui = ShowDataPic(None)
gui.Show()
app.MainLoop()
分析结果: