高斯判别分析(GDA)Python代码
GDA Python代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/8/812:56
# @Author : DaiPuWei
# E-Mail : [email protected]
# @Site : 湖北省荆州市公安县自强中学
# @File : GDA.py
# @Software: PyCharm
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_breast_cancer
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import accuracy_score
from sklearn.linear_model import LogisticRegression
import matplotlib as mpl
import matplotlib.pyplot as plt
class GDA:
def __init__(self,train_data,train_label):
"""
这是GDA算法构造函数
:param train_data: 训练数据
:param train_label: 训练数据标签
"""
self.Train_Data = train_data
self.Train_Label = train_label
self.postive_num = 0 # 正样本个数
self.negetive_num = 0 # 负样本个数
postive_data = [] # 正样本数组
negetive_data = [] # 负样本数组
for (data,label) in zip(self.Train_Data,self.Train_Label):
if label == 1: # 正样本
self.postive_num += 1
postive_data.append(list(data))
else: # 负样本
self.negetive_num += 1
negetive_data.append(list(data))
# 计算正负样本的二项分布的概率
row,col = np.shape(train_data)
self.postive = self.postive_num*1.0/row # 正样本的二项分布概率
self.negetive = 1-self.postive # 负样本的二项分布概率
# 计算正负样本的高斯分布的均值向量
postive_data = np.array(postive_data)
negetive_data = np.array(negetive_data)
postive_data_sum = np.sum(postive_data, 0)
negetive_data_sum = np.sum(negetive_data, 0)
self.mu_positive = postive_data_sum*1.0/self.postive_num # 正样本的高斯分布的均值向量
self.mu_negetive = negetive_data_sum*1.0/self.negetive_num # 负样本的高斯分布的均值向量
# 计算高斯分布的协方差矩阵
positive_deta = postive_data-self.mu_positive
negetive_deta = negetive_data-self.mu_negetive
self.sigma = []
for deta in positive_deta:
deta = deta.reshape(1,col)
ans = deta.T.dot(deta)
self.sigma.append(ans)
for deta in negetive_deta:
deta = deta.reshape(1,col)
ans = deta.T.dot(deta)
self.sigma.append(ans)
self.sigma = np.array(self.sigma)
#print(np.shape(self.sigma))
self.sigma = np.sum(self.sigma,0)
self.sigma = self.sigma/row
self.mu_positive = self.mu_positive.reshape(1,col)
self.mu_negetive = self.mu_negetive.reshape(1,col)
def Gaussian(self, x, mean, cov):
"""
这是自定义的高斯分布概率密度函数
:param x: 输入数据
:param mean: 均值向量
:param cov: 协方差矩阵
:return: x的概率
"""
dim = np.shape(cov)[0]
# cov的行列式为零时的措施
covdet = np.linalg.det(cov + np.eye(dim) * 0.001)
covinv = np.linalg.inv(cov + np.eye(dim) * 0.001)
xdiff = (x - mean).reshape((1, dim))
# 概率密度
prob = 1.0 / (np.power(np.power(2 * np.pi, dim) * np.abs(covdet), 0.5)) * \
np.exp(-0.5 * xdiff.dot(covinv).dot(xdiff.T))[0][0]
return prob
def predict(self,test_data):
predict_label = []
for data in test_data:
positive_pro = self.Gaussian(data,self.mu_positive,self.sigma)
negetive_pro = self.Gaussian(data,self.mu_negetive,self.sigma)
if positive_pro >= negetive_pro:
predict_label.append(1)
else:
predict_label.append(0)
return predict_label
def run_main():
"""
这是主函数
"""
# 导入乳腺癌数据
breast_cancer = load_breast_cancer()
data = np.array(breast_cancer.data)
label = np.array(breast_cancer.target)
data = MinMaxScaler().fit_transform(data)
# 解决画图是的中文乱码问题
mpl.rcParams['font.sans-serif'] = [u'simHei']
mpl.rcParams['axes.unicode_minus'] = False
# 分割训练集与测试集
train_data,test_data,train_label,test_label = train_test_split(data,label,test_size=1/4)
# 数据可视化
plt.scatter(test_data[:,0],test_data[:,1],c = test_label)
plt.title("乳腺癌数据集显示")
plt.show()
# GDA结果
gda = GDA(train_data,train_label)
test_predict = gda.predict(test_data)
print("GDA的正确率为:",accuracy_score(test_label,test_predict))
# 数据可视化
plt.scatter(test_data[:,0],test_data[:,1],c = test_predict)
plt.title("GDA分类结果显示")
plt.show()
# Logistic回归结果
lr = LogisticRegression()
lr.fit(train_data,train_label)
test_predict = lr.predict(test_data)
print("Logistic回归的正确率为:",accuracy_score(test_label,test_predict))
# 数据可视化
plt.scatter(test_data[:,0],test_data[:,1],c = test_predict)
plt.title("Logistic回归分类结果显示")
plt.show()
if __name__ == '__main__':
run_main()结果分析
以下是上述程序的结果截图: 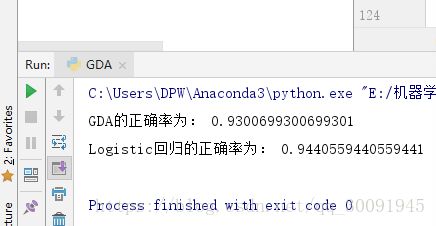
明显看到,GDA的效果略微差于Logistic回归,这也证实了GDA的模型假设更强,当数据不是特别服从高斯分布时,效果略差于LR。LR更具备鲁棒性,实用性更强