SpringBoot2.x学习-数据源(HikariCP和Druid)和JdbcTemplate
一、配置默认的数据源
Spring Boot2.0默认使用hikari作为数据源,使用的时候不需要额外添加maven依赖,配置一下就可以使用。
1.application.properties配置文件内容如下:
server.port=8888
server.servlet.context-path=/
server.tomcat.uri-encoding=utf-8
project.name=boot
logging.file=D:/logs/${project.name}.log
logging.level.com.soft=debug
#数据库相关配置
spring.datasource.url=jdbc:oracle:thin:@127.0.0.1:1521:ORCL
spring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver
spring.datasource.username=scott
spring.datasource.password=tiger
#连接池配置
spring.datasource.hikari.maximum-pool-size=11
spring.datasource.hikari.minimumIdle=5
spring.datasource.hikari.idleTimeout=600000
spring.datasource.hikari.connectionTimeout=30000
spring.datasource.hikari.maxLifetime=1800000
这样在启动应用的时候 可以看到控制台输出HikariCP对象的日志
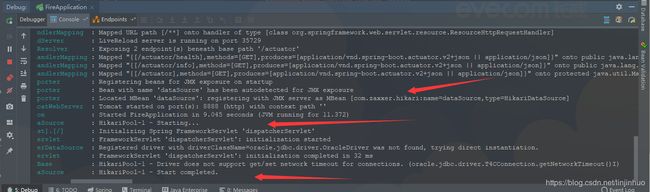
二、配置Druid数据源
Spring Boot 最核心的就是这个 @EnableAutoConfiguration ,启动自动配置,这个注解会让Spring Boot根据当前项目所依赖的jar包自动配置项目的相关配置项。首先加入Druid依赖然后在配置文件里面配置 druid 相关的参数,Spring Boot 就能够自动配置Druid数据源,如果我把 maven依赖去掉或者把参数去掉,那 Spring Boot 就不会自动配置。
1.排除默认的HikariCP数据源
org.springframework.boot
spring-boot-starter-jdbc
HikariCP
com.zaxxer
2.添加Druid数据源
com.alibaba
druid-spring-boot-starter
${druid.version}
3.配置Druid数据源 ,application.properties配置如下:
Druid官网
server.port=8888
server.servlet.context-path=/
server.tomcat.uri-encoding=utf-8
#project.name=boot
#logging.file=D:/logs/springboot.log
#共有8个级别,按照从低到高为:All < Trace < Debug < Info < Warn < Error < Fatal < OFF.
#程序会打印高于或等于所设置级别的日志,设置的日志等级越高,打印出来的日志就越少。
#logging.level.com.soft=debug
#数据库相关配置
spring.datasource.url=jdbc:oracle:thin:@127.0.0.1:1521:ORCL
spring.datasource.driver-class-name=oracle.jdbc.driver.OracleDriver
spring.datasource.username=scott
spring.datasource.password=tiger
#HikariCP数据源 连接池配置
#spring.datasource.hikari.maximum-pool-size=11
#spring.datasource.hikari.minimumIdle=5
#spring.datasource.hikari.idleTimeout=600000
#spring.datasource.hikari.connectionTimeout=30000
#spring.datasource.hikari.maxLifetime=1800000
#Druid数据源相关配置
# 配置初始化大小、最小、最大
spring.datasource.druid.initial-size=5
#最小空闲连接数
spring.datasource.druid.min-idle=3
#最大空闲连接数
spring.datasource.druid.max-active=20
#配置获取连接等待超时的时间
spring.datasource.druid.max-wait=60000
#配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.druid.time-between-eviction-runs-millis=60000
#配置一个连接在池中最小生存的时间 单位是毫秒
spring.datasource.druid.min-evictable-idle-time-millis=300000
#用来检测连接是否有效的sql,要求是一个查询语句
spring.datasource.druid.validation-query=SELECT 'x' FROM DUAL
#申请连接的时候检测
spring.datasource.druid.test-while-idle=true
#申请连接时执行validationQuery检测连接是否有效,配置为true会降低性能
spring.datasource.druid.test-on-borrow=false
# 归还连接时执行validationQuery检测连接是否有效,配置为true会降低性能
spring.datasource.druid.test-on-return=false
#打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.druid.pool-prepared-statements=true
spring.datasource.druid.max-pool-prepared-statement-per-connection-size=50
#Filter配置
spring.datasource.druid.filters=wall,stat,log4j2
#Druid内置提供一个StatFilter,用于统计监控信息。
#是否启用StatViewServlet(监控页面)默认值为false(考虑到安全问题默认并未启动,
#如需启用建议设置密码或白名单以保障安全)
spring.datasource.druid.stat-view-servlet.enabled=true
#设置监控页面账号
spring.datasource.druid.stat-view-servlet.login-username=smith
#配置监控页面访问密码
spring.datasource.druid.stat-view-servlet.login-password=123456
#在StatViewSerlvet输出的html页面中,有一个功能是Reset All,执行这个操作之后,
#会导致所有计数器清零,重新计数。你可以通过配置参数关闭它
spring.datasource.druid.stat-view-servlet.reset-enable=false
#配置访问控制 deny优先于allow,如果在deny列表中,就算在allow列表中,也会被拒绝。
#如果allow没有配置或者为空,则允许所有访问
spring.datasource.druid.stat-view-servlet.allow=192.168.31.15
#设置禁止访问监控页面的IP地址 不支持IPV6
spring.datasource.druid.stat-view-servlet.deny=127.0.0.1,127.0.0.2
#慢SQL记录
spring.datasource.druid.filter.stat.enabled=true
spring.datasource.druid.filter.stat.db-type=oracle
spring.datasource.druid.filter.stat.log-slow-sql=true
spring.datasource.druid.filter.stat.merge-sql=true
#慢sql时间设置,即执行时间大于200毫秒的都是慢sql
spring.datasource.druid.filter.stat.slow-sql-millis=200
spring.datasource.druid.filter.slf4j.enabled=true
spring.datasource.druid.filter.slf4j.result-set-log-enabled=false
spring.datasource.druid.filter.log4j2.enabled=false
#所有连接相关的日志
spring.datasource.druid.filter.log4j2.connection-log-enabled=false
#所有Statement相关的日志
spring.datasource.druid.filter.log4j2.statement-log-enabled=false
#是否显示结果集
spring.datasource.druid.filter.log4j2.result-set-log-enabled=true
# 是否显示SQL语句
spring.datasource.druid.filter.log4j2.statement-executable-sql-log-enable=true
#Sql防注入
spring.datasource.druid.filter.wall.enabled=true
spring.datasource.druid.filter.wall.db-type=oracle
spring.datasource.druid.filter.wall.config.delete-allow=false
spring.datasource.druid.filter.wall.config.drop-table-allow=false
4.采用log4j2日志框架,在resources目录下 添加log4j2.xml文件 内容如下:
D:/
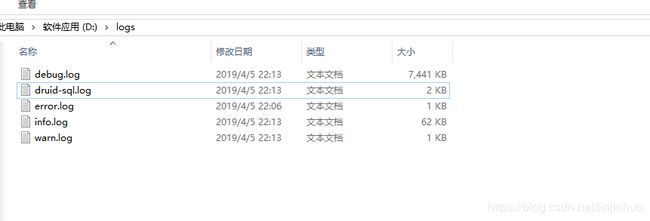
5.启动应用 生成的几个日志文件如下:
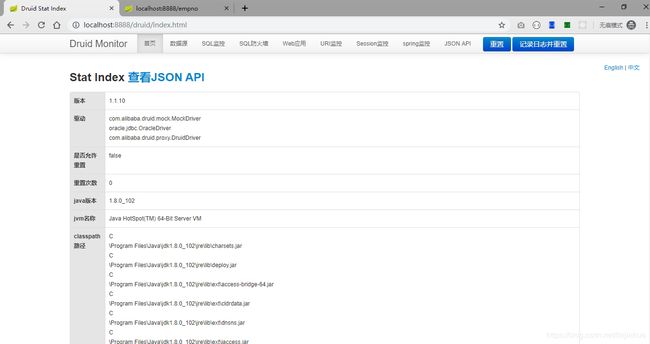
6.访问Druid监控页面 如下:输入smith/123456就能访问到

三、使用Spring 的JDBC操作类
.通过Spring JdbcTemplate对象操作scott数据库用户下的Emp表
需要添加jdbc启动器 依赖
1.dao接口及实现代码如下:
public interface EmpDao {
/**
* 根据名称 获取雇员信息
* @param ename
* @return
*/
Map getEmpByName(String ename);
/**
* 根据编号获取员工信息
* @param empno
* @return
*/
Emp getEmpByNo(String empno);
}
@Repository("empDao")
public class EmpDaoImpl implements EmpDao {
/**
* 注入jdbc操作依赖
*/
@Resource
private JdbcTemplate jdbcTemplate;
/**
* 根据名称 获取雇员信息
*
* @param ename
* @return
*/
@Override
public Map getEmpByName(String ename) {
StringBuilder sql = new StringBuilder(32);
sql.append("SELECT E.* FROM EMP E WHERE E.ENAME=?");
return jdbcTemplate.queryForMap(sql.toString(),new Object[]{ename});
}
@Override
public Emp getEmpByNo(String empno) {
StringBuilder sql = new StringBuilder(32);
sql.append("SELECT E.* FROM EMP E WHERE E.EMPNO=?");
return jdbcTemplate.queryForObject(sql.toString(),new EmpRowMapper(),empno);
}
}
2.service接口及实现如下:
public interface EmpService {
/**
* 根据名称 获取雇员信息
* @param ename
* @return
*/
Map getEmpByName(String ename) ;
/**
* 根据编号获取员工信息
* @param empno
* @return
*/
Emp getEmpByNo(String empno);
}
@Service("empService")
public class EmpServiceImpl implements EmpService {
/**
* 注入dao依赖
*/
@Resource
private EmpDao empDao;
/**
* 根据名称 获取雇员信息
*
* @param ename
* @return
*/
@Override
public Map getEmpByName(String ename) {
return empDao.getEmpByName(ename);
}
@Override
public Emp getEmpByNo(String empno) {
return empDao.getEmpByNo(empno);
}
}
3.Spring RowMapper实现如下
public class EmpRowMapper implements RowMapper {
@Override
public Emp mapRow(ResultSet rs, int i) throws SQLException {
Emp emp = new Emp();
emp.setEmpno(rs.getInt("EMPNO"));
emp.setEname(rs.getString("ENAME"));
emp.setJob(rs.getString("JOB"));
emp.setMgr(rs.getInt("MGR"));
emp.setHiredate(rs.getTimestamp("HIREDATE"));
emp.setSal(rs.getDouble("SAL"));
emp.setComm(rs.getDouble("COMM"));
emp.setDeptno(rs.getInt("DEPTNO"));
return emp;
}
}
4.emp实体对象如下(IDEA 需要添加lombok插件、lombok的maven依赖 和IDEA相关配置)
@Setter
@Getter
@ToString
public class Emp {
/**
* 员工编号
*/
private int empno;
/**
* 员工姓名
*/
private String ename;
/**
* 工作岗位
*/
private String job;
/**
* 领导者编号
*/
private int mgr ;
/**
* 入职时间
* 自定义输出格式
*/
@JsonFormat(locale="zh", timezone="GMT+8", pattern="yyyy-MM-dd HH:mm:ss")
private Timestamp hiredate;
/**
* 薪水
*/
private double sal;
/**
* 奖金
*/
private double comm;
/**
* 所在部门编号
*/
private int deptno;
}
5.Controller实现如下:
@RestController
public class EmpController {
/**
* 日志操作对象
*/
Logger logger = LoggerFactory.getLogger(EmpController.class);
/**
* 员工业务操作对象
*/
@Resource
private EmpService empService;
@RequestMapping("/empname")
public Map getEmp(){
return empService.getEmpByName("SMITH");
}
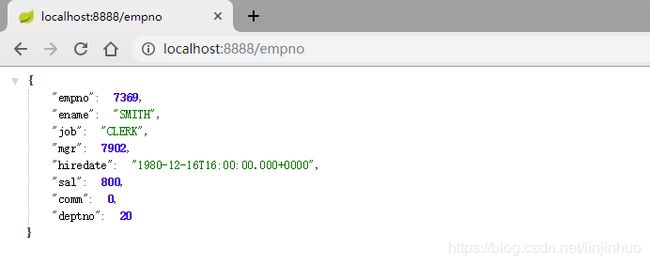
@RequestMapping("/empno")
public Emp getEmpByNo(){
return empService.getEmpByNo("7369");
}
}
6.启动访问结果如下:
参考文章:链接: HikariCP.
链接: Druid中使用log4j2进行日志输出.