Flink API入门
Flink数据处理流程
通过前面的文章我们大概了解了实时流处理框架,这篇文章开始我们将详细来学习下Flink的使用。Flink为开发流式/批处理应用程序提供了不同级别的抽象。
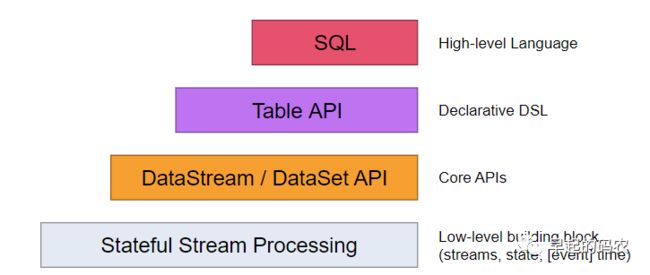
而这几个抽象的模块中DataStream API用于处理实时流处理,DataSet API用于离线批处理。
入门Flink API
后面我们都选择使用Scala来完成Flink程序的编写,当然你也可以选择Java或者Python。Scala DataSet API的所有核心类都在包org.apache.flink.api.scala中,DataStream API都在org.apache.flink.streaming.api.scala中。
要执行一个flink程序首先要获取一个执行环境,获得一个执行环境有三种方式:
getExecutionEnvironment()
createLocalEnvironment()
createRemoteEnvironment(host: String, port: Int, jarFiles: String*)
DataSet我们建议这样获取:
val env = ExecutionEnvironment.getExecutionEnvironment
DataStream 我们建议这样获取:
val env = StreamExecutionEnvironment.getExecutionEnvironment
先来看两段入门代码:
这个是DataSet的wordCount代码
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.api.scala._
object WordCount {
def main(args: Array[String]):Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.fromElements(
"Who's there?",
"I think I hear them. Stand, ho! Who's there?")
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.groupBy(0)
.sum(1)
counts.print()
}
}
这个是DataStream的入门代码:
import org.apache.flink.streaming.api.scala._
import org.apache.flink.streaming.api.windowing.time.Time
object WindowWordCount {
def main(args: Array[String]) {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val text = env.socketTextStream("localhost", 9999)
val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } }
.map { (_, 1) }
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
counts.print()
env.execute("Window Stream WordCount")
}
}
数据处理流程
一个完整的数据处理流程基本上要通过source operator->transformation operators->sink operator 这几个步骤:
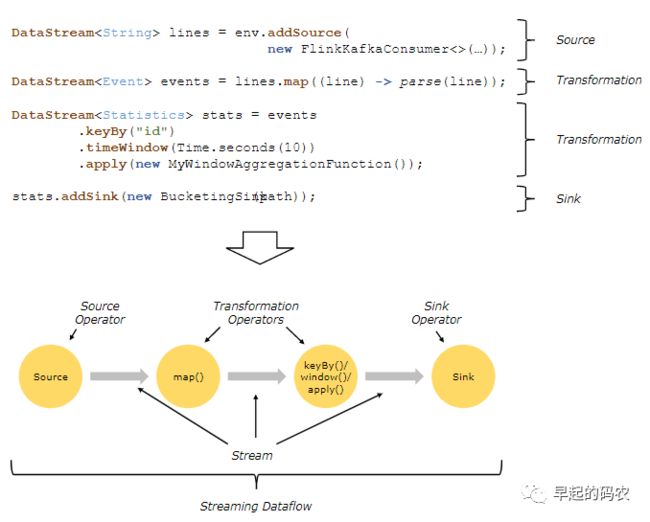
下面我们以DataStream为例展示下数据Source和Sink的处理流程:
Source
01 基于file的数据源
//创建环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//获取数据源,基于file的数据源(source)
val streamFile = env.readTextFile("word.txt")
//打印数据(sink)
streamFile.print()
//执行任务
env.execute("Source Test")另一种支持自定义格式的读取方式:
val streamFileFormat = env.readFile(new TextInputFormat(new Path("word.txt")),"word.txt")
02 基于socket的数据源
val streamStock = env.socketTextStream("127.0.0.1", 8088, '\n')
03
基于集合的数据源
val streamSeq = env.generateSequence(1, 10)
val list = List(1, 3, 4)
val streamList = env.fromCollection(list)
val iterator = Iterator(1, 2, 3, 5,"xx")
val streamIter = env.fromCollection(iterator)
//list中元素类型必须一致
val streamElement = env.fromElements(list)Sink
01 输出到文件夹
streamFileFormat.writeAsText("output")
02 输出到socket
streamFileFormat.writeToSocket("127.0.0.1",9909, new SimpleStringSchema());
03 输出到控制台
streamFileFormat.print()



猜您喜欢
往期精选▼
1. 大数据流批一体处理框架概述
2. 软件开发中不得不知道的幂等性问题
3. Mongodb副本集和分片
4. Elasticsearch基础实践
5. Aerospike Introduction
6. Spark Rdd & DataFrame