jdk1.8 JVM调优,垃圾收集器适用场景、内存压榨
疑问
1、为什么设置了-Xms128m -Xmx128m,启动后就飙到了300m?
2、为什么没有一种收集器可以适配所有场景?
目标
1:JVM内存压榨。
2:空闲内存释放回操作系统。
3:根据实际应用场景,进行jvm性能调优。
一、介绍
- 基础知识点
- 名词解释
- JVM七种垃圾收集器
- 监控JVM活动
- 图形化工具
1.1 基础知识点
在jdk1.8中,取消了永久代,元空间(Metaspace)登上舞台,方法区存在于元空间(Metaspace)。同时,元空间不再与堆连续,而且是存在于本地内存(Native memory)。
如下图:
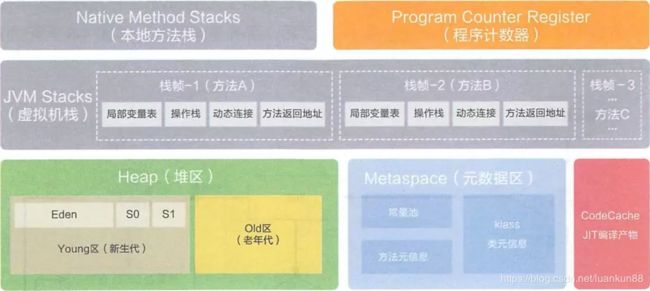
1.2 名词解释
堆:包括老年代 + 新生代(Eden+Form+To或者Eden+S0+S1),Survivor区包括S0,S1。
Minor GC:又称新生代GC,指发生在新生代的垃圾收集动作。
Major GC/Full GC:老年代GC,指发生在老年代的GC。
stop-the-world:简称STW,是JVM在后台自动发起和自动完成的,在用户不可见的情况下,把用户正常的工作线程全部停掉,即GC停顿;
垃圾收集器:是垃圾回收算法(标记-清除算法、复制算法、标记-整理算法(压缩法)、分代收集算法)的具体实现,不同商家、不同版本的JVM所提供的垃圾收集器可能会有很在差别,本文主要介绍HotSpot(JVM的技术实现)虚拟机中的垃圾收集器。
并行垃圾收集:指多条垃圾收集线程并行工作,但此时用户线程仍然处于等待状态;如ParNew、Parallel Scavenge、Parallel Old。
并发垃圾收集:指用户线程与垃圾收集线程同时执行(但不一定是并行的,可能会交替执行);
用户程序在继续运行,而垃圾收集程序线程运行于另一个CPU上;如CMS、G1(并行与并发)。
吞吐量(Throughput):CPU用于运行用户代码的时间与CPU总消耗时间的比值;
吞吐量=运行用户代码时间/(运行用户代码时间+垃圾收集时间)
高吞吐量即减少垃圾收集时间,让用户代码获得更长的运行时间
垃圾收集器期望的目标(关注点):
(1)、停顿时间
停顿时间越短就适合需要与用户交互的程序;
良好的响应速度能提升用户体验;
(2)、吞吐量
高吞吐量则可以高效率地利用CPU时间,尽快完成运算的任务;
主要适合在后台计算而不需要太多交互的任务;
(3)、覆盖区(Footprint)
在达到前面两个目标的情况下,尽量减少堆的内存空间;
可以获得更好的空间局部性;
1.3 JVM七种垃圾收集器
现在常见的垃圾收集器有如下几种:
新生代收集器:
- Serial
- ParNew
- Parallel Scavenge
老年代收集器:
- Serial Old
- CMS
- Parallel Old
堆内存垃圾收集器:G1
每种垃圾收集器之间有连线,表示他们可以搭配使用,如下图:

下面给出配置回收器时,经常使用的参数:
-XX:+UseSerialGC:在新生代和老年代使用串行收集器
-XX:+UseParNewGC:在新生代使用并行收集器
-XX:+UseParallelGC :在新生代使用并行收集器,老年代使用串行收集器(jdk1.8默认收集器)
-XX:+UseParallelOldGC:新生代和老年代都使用并行收集器
-XX:ParallelGCThreads:设置用于垃圾回收的线程数
-XX:+UseConcMarkSweepGC:老年代使用CMS收集器
-XX:ParallelCMSThreads:设定CMS的线程数量
-XX:+UseG1GC:启用G1垃圾收集器(jdk1.9默认收集器)
-XX:MaxGCPauseMillis:控制收集的暂停时间(ms),谨慎使用
1.4 监控JVM活动
1、分析内存占用情况----本地内存跟踪(Native Memory Tracking NMT)
# JVM启动参数配置,打开NMT会带来5%-10%的性能损耗,暂为调试开启
$ -XX:NativeMemoryTracking=summary
$ jcmd VM.native_memory summary
2、查看jvm参数默认值
$ java -XX:+PrintFlagsFinal
$ java -XX:+PrintFlagsInitial
3、查询JVM启动参数信息
$ jinfo -flags
4、查看full gc频率(full gc频率 =持续时间 /FGC)
$ jstat -gc
5、堆占用情况
$ jmap -heap
1.5 图形化工具
Jconsole : JDK自带,功能简单,但是可以在系统有一定负荷的情况下使用。
VisualVM:JDK自带,功能强大,与JProfiler类似。推荐
JProfiler:商业软件,需要付费(有破解版)。功能强大。
【注】: Jconsole、VisualVM远程连接参考
二、演示
2.1 目标1:JVM内存压榨
2.1.1 思路
使用工具跟踪jvm占用的本地内存,查看内存都去哪里了,看看哪些部分可以调整压缩
2.1.2 步骤
【注意】
1. 打开NMT会带来5%-10%的性能损耗,暂为演示开启。
2. jvm参数设置有顺序要求,比如"-Xshare:on" 在linux系统需放在启动命令最后。
- 参数说明
-Xms85m # JAVA 堆内存的初始值、默认为物理内存的1/64
-Xmx128m # JAVA 堆内存的最大值,默认为物理内存的1/4
-XX:NativeMemoryTracking=summary # JVM启动参数配置,打开NMT会带来5%-10%的性能损耗,暂为调试开启
-XX:+UseSerialGC # 启用串行、最轻量级GC,默认-XX:+UseParallelGC
-XX:CICompilerCount=1 # 减少编译器线程数,最低为1,默认是3
-XX:-TieredCompilation # 只启用最新编译层
-XX:MetaspaceSize=100m # 初始元空间大小,默认21MB
-XX:MaxMetaspaceSize=100m # 最大元空间,默认是没有限制的
-XX:CompressedClassSpaceSize=15m # 设置Klass Metaspace的大小 ,默认1G;Klass Metaspace就是用来存klass的,klass是class文件在jvm里的运行时数据结构,则CompressedClassSpace分配在MaxMetaspaceSize里头,即MaxMetaspaceSize=Compressed Class Space Size + Metaspace area
-Xss256k # 每个线程的堆栈大小,默认1M
-XX:MaxDirectMemorySize=30m # Direct ByteBuffer分配的堆外内存此参数到达指定大小后,即触发Full GC,上限由JVM运行时的最大内存来决定,基本上和-xmx大小相等。内存不足时抛出OutOfMemoryError
-Xshare:on # 开启类数据共享(linux系统需放在启动命令最后)
- 常规JVM启动参数
$ nohup java -XX:NativeMemoryTracking=summary -jar -Xms85m -Xmx128m ***.jar >>***.out 2>&1 &
- 调研后JVM启动参数
$ nohup java -XX:+UseSerialGC -XX:NativeMemoryTracking=summary -XX:CICompilerCount=1 -XX:-TieredCompilation -XX:MetaspaceSize=100m -XX:MaxMetaspaceSize=100m -XX:CompressedClassSpaceSize=15m -Xms85m -Xmx128m -Xss256k -XX:MaxDirectMemorySize=30m -jar ***.jar -Xshare:on >>***.out 2>&1 &
- 对比
使用NMT查看(重点关注每个分类下的commit大小,这个是实际使用的内存大小)
$ jcmd VM.native_memory summary
2.2 目标2:空闲内存释放回操作系统
举例: 比如一个项目上传、下载功能需要大量的堆内存,那么参数设置较低,一定会内存溢出,这种有特殊情况的,可以用下述方案,效果显著,占用内存接近启动时内存
-Xms85m -Xmx300m -XX:+UseSerialGC
设置一个定时器,定时调用System.gc(),一段时间后(约半小时),会释放大量空闲内存
注:仅公司内部压缩内存使用,或有特殊需求时使用,不推荐正式上线项目使用。
可设置参数-XX:+DisableExplicitGC,禁止程序中调用System.gc()
【注】: jdk1.8暂不支持自动归还空闲内存。
java12的G1垃圾收集器,使其能够在空闲时自动将 Java 堆内存返还给操作系统。
2.3 目标3:jvm性能调优
2.3.1 思路
(1)、根据实际应用场景,比如:吞吐量优先;减少卡顿、提示用户体验度优先,如何搭配合适的垃圾收集器;
(2)、设置合适的参数;
(3)、在理论基础上,模拟实际应用场景,进行长期的调试、观察,不可随意配置就上线使用,可能会适得其反。
(4)、充分利用服务器资源,比如8G,16G,32G如何搭配参数。
2.3.2 步骤
2.3.2.1 根据应用场景选择合适的垃圾收集器
(1)、单个CPU的环境,在用户的桌面应用场景中,可用内存一般不大(几十M至一两百M)
推荐Serial收集器,参数说明如下:
-XX:+UseSerialGC # 新生代和老年代都使用串行垃圾收集器
启动参数如下:
-Xms128m -Xmx128m -XX:+UseSerialGC -XX:TargetSurvivorRatio=90 -XX:NewRatio=1 -XX:+DisableExplicitGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:C:\Users\cosmo-101\Desktop\gc.log
(2)、高吞吐为目标,对暂停时间没有特别高的要求
推荐Parallel Scavenge收集器,参数说明如下:
【注】:只需设置好内存数据大小(如"-Xmx"设置最大堆)。
-XX:+UseParallelOldGC # 新生代和老年代都使用并行收集器
-XX:MaxGCPauseMillis # 控制最大垃圾收集停顿时间,大于0的毫秒数
-XX:GCTimeRatio # 设置垃圾收集时间占总时间的比率,0启动参数如下:
-Xms2g -Xmx2g -XX:+UseParallelOldGC -XX:MaxGCPauseMillis=200 -XX:GCTimeRatio=99 -XX:+UseAdaptiveSizePolicy -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExplicitGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:C:\Users\cosmo-101\Desktop\gc.log
(3)、希望系统停顿时间最短,注重服务的响应速度
推荐CMS收集器,参数说明如下:
-XX:+UseConcMarkSweepGC # 指定老年代使用CMS收集器,会默认使用ParNew作为新生代收集器
-XX:+CMSScavengeBeforeRemark # 在执行CMS Remark阶段前,执行一次Minor GC,以降低STW的时间。通过 Minor GC可以减少新生代对老年代对象的引用,这样可以减少根对象数量,从而降低CMS Remark的工作量.
-XX:CMSFullGCsBeforeCompaction
设置执行多少次不压缩的Full GC后,来一次压缩整理;
为了减少合并整理过程的停顿时间,默认为0;
也就是说每次都执行Full GC,不会进行压缩整理。
启动参数如下:
-Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:TargetSurvivorRatio=90 -XX:NewRatio=1 -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+CMSScavengeBeforeRemark -XX:CMSFullGCsBeforeCompaction=10 -XX:+DisableExplicitGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:C:\Users\cosmo-101\Desktop\gc.log
(4)、针对具有大内存、多处理器的机器,低GC延迟,堆大小约6GB或更大时
推荐G1收集器,参数说明如下:
【注】:使用G1回收器时,G1打破了以往将收集范围固定在新生代或老年代的模式,不需要为各个空间进行单独设置了,G1算法将堆整体划分为若干个区域(Region)。
-XX:+UseG1GC # 指定使用G1收集器
-XX:MaxGCPauseMillis # 为G1设置暂停时间目标,默认值为200毫秒
-XX:G1HeapRegionSize # 设置每个Region大小,范围1MB到32MB;目标是在最小Java堆时可以拥有约2048个Region
-XX:ParallelGCThreads=n # STW期间,并行线程数。建议设置与处理器相同个数,最多为8。
如果处理器多于8个,则将n的值设置为处理器的大约5/8。
启动参数如下:
-Xms8g -Xmx8g -XX:+UseG1GC -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExplicitGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:C:\Users\cosmo-101\Desktop\gc.log
2.3.2.2 设置合适的参数
- 常规参数
-XX:TargetSurvivorRatio # 默认值50,当survivor区存放的对象超过这个百分百,则对象会向老年代压缩,因此,有助于将对象留在新生代
-XX:NewRatio=1 # 老年代与新生代的比例,默认2:1,有助于将对象预留新生代,新生代Minor GC成本远远小于老年代的Full GC
-Xmn=70m
-XX:MetaspaceSize=256m # 初始元空间大小,默认21MB
-XX:MaxMetaspaceSize=256m # 最大元空间,默认是没有限制的,可以根据GC日志打印,如“Full GC (Metadata GC Threshold)”过于频繁,则调整此参数;未设置,虚拟机会自动从21MB初始大小逐渐增长,每次Full GC后自动调整
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:gc.log # 保存gc日志,作为优化的依据
-XX:+DisableExplicitGC # 禁止System.gc(),免得程序员误调用gc方法影响性能
2.3.2.3 Jmeter压测
1、 聚合报告参数详解
# 1、Label:每个 JMeter 的 element(例如 HTTP Request)都有一个 Name 属性,这里显示的就是 Name 属性的值;
# 2、#Samples:表示这次测试中一共发出了多少个请求,如果模拟10个用户,每个用户迭代10次,那么这里显示100;【我的是用户有100,只迭代一次,因此也是100】
# 3、Average:平均响应时间——默认情况下是单个 Request 的平均响应时间(ms);
# 4、Median:中位数,也就是 50% 用户的响应时间;
# 5、90% Line ~ 99% Line:90% ~99%用户的响应时间;
# 6、Min:最小响应时间;
# 7、Maximum:最大响应时间;
# 8、Error%:本次测试中出现的错误率,即 错误的请求的数量/请求的总数;
# 9、Throughput:吞吐量——默认情况下表示每秒完成的请求数(Request per Second);
# 11、Sent KB/src:每秒从客户端发送的请求的数量。
2、 压测工具使用
【注】:根据jmeter启动说明,执行测试计划不能用GUI,需要用命令行来执行
可以通过GUI调整测试参数,再通过命令行来执行
在jmeter安装目录下的bin文件夹下,执行命令如下:
$ jmeter -n -t testplan.jmx -l result.jtl -e -o webreport
# testplan.jmx 为测试计划文件路径
# result.txt 为测试结果文件路径
# webreport 为web报告保存路径。
3、 模拟实际应用,测试方案
(1). 创建一个测试计划;
(2). 在该计划下添加2个线程组,分别是对业务A、业务B;
(3). 分别设置线程组业务A、业务B的线程数为:50、50(总并发量为100);
(4). 观察吞吐量,响应时间是否满足需求。
4、不同启动参数压测报告对比图:
(1)、如下图:
-Xms128m -Xmx128m -XX:+UseSerialGC -XX:TargetSurvivorRatio=90 -XX:NewRatio=1 -XX:+DisableExplicitGC

(2)、如下图:
-Xms8g -Xmx8g -XX:+UseG1GC -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExplicitGC

压测结果:
根据上述两图,图2 Average(平均响应时间),Throughput(吞吐)明显比图1优秀;
除聚合报告,还可以根据需要观察cpu,memory,Network,I/O等等。
监控cpu等需要安装插件(推荐安装jmeter3.1版本,版本过高会报错)
Jmeter性能指标分析参考链接
Jmeter插件参考链接
七种垃圾回收器原文地址