第七章 NoSQL数据库技术(二)
文档型数据库
文档是处理信息的基本单位。文档可以很长、很复杂、可以无结构
一个文档对包含的数据类型和内容进行“自我描述”。XML文档、HTML文档和JSON 文档
嵌入式文档 --文档存储模型支持嵌套结构
每个文档的ID就是它唯一的键,ID在一个数据库“集合”中是唯一的, 检索排序的ID性能好。
MongoDB 数据库
MongoDB 是基于分布式文件存储的开源数据库系统。 将数据存储为一个文档,数据结构由键值对组成,字段值可以包含其他文档,数组及文档数组。 每一行的存储格式为 field:value。 每个文档可以匹配所表示实体的数据域。 数据关系有两种:引用和嵌入文档。 写操作在文档级别是原子性的,没有单个写操作对超过一个文档或者超过一个集合是原子性的。
MongoDB数据模型
基本的概念是文档、集合、数据库。 文档是MongoDB中数据的基本单元 集合可以被看作没有模式的表, 每个实例都可容纳多个独立数据库,每个数据库都有自己的集合和权限。
层次关系: 文档—集合---数据库。

文档
多个键及其关联的值有序地放置在一起就是文档。 文档是一组键值(key-value)对(即BSON)。 文档不需要设置相同的字段,相同的字段不需要相同的数据类型。 一个文档包含一组字段,每一个字段都是一个key/value对, 其中key必须为字符串类型, value包含string,int,float,timestamp,binary 等类型, 或一个文档, 或数组类型。
单键值文档{“userName”:“BBS11”}, 多键值文档{ "_id" : ObjectId("580dfe72729"), "name" : "test", "add": "china" },文档中的键/值对是有序的。 文档中的值可以是在双引号里面的字符串,还可以是其他几种数据类型(甚至可以是整个嵌入的文档)。 MongoDB文档不能有重复的键。文档的键是字符串。文档中的值不仅可以是字符串,也可以是其他数据类型(或者嵌入其他文档)
集合
把一组相关的文档放到一起组成了集合 集合是模式自由的,一个集合里面的文档可以是各式各样的。
例如:下面的两个文档可以出现在同一集合中
{“name”:”arthur”}
{“name”:”arthur”,”sex”:”male”}
MongoDB提供了一些特殊功能的集合,例如:capped collection、system.indexes、system.namespaces等。
元数据是定义数据的数据, 数据库的信息是存储在集合中。
数据库
多个文档组成集合,数据库由多个集合组成 MongoDB实例可承载多个数据库,互相之间彼此独立 开发中通常将一个应用(或同一种业务类型)的所有数据存放到同一个数据库中;磁盘上,MongoDB将不同数据库存放在不同文件中。 一个MongoDB 实例可以包含一组数据库,一个数据库可以包含一组集合(Collection集合),一个集合可以包含一组文档。一个mongodb中可以建立多个数据库。 系统数据库包括:admin、local、config等。
面向集合且模式自由的文档型数据库。面向集合--数据被分组为集合(文档);数据模式自由;存储的数据是键值对的集合,键是字符串,值是任意类型,包括数组和文档。
文档是MongoDB中数据的基本单元,集合可以被看作没有模式的表,MongoDB每个实例都可容纳多个独立数据库,每个数据库都有自己的集合和权限(数据库)。 文档(Document)---文档组集合:Collection -- 多个集合:数据库(database)。一个实例支持多个数据库(database)
数据库对应文件信息
默认数据目录是/daba/db,存储所有的数据文件,每个数据库都包含一个.ns文件和一些数据文件,例如test数据库,数据库的文件就会由test.ns、test.0、test.1、test.2等组成。 预分配空间的机制,用0进行填充。 每新分配一次,它的大小都会是上一个数据文件大小的2倍,每个数据文件最大2G。 数据库的每张表都对应一个命名空间,每个索引也有对应的命名空间,这些命名空间的元数据集中在*.ns文件中。
数据库存储
数据库中所有的collections以及索引信息分散存储在多个数据文件中,数据分块的单位为extent(范围,区域),即一个data file中有多个extents组成,extent中可以保存collection数据或者indexes数据,一个extent只能保存同一个collection数据,不同的collections数据分布在不同的extents中,indexes数据也保存在各自的extents中; 在每个database的namespace文件中,每个collection只保存了第一个extent的位置信息,每个extent都维护着一个链表关系。
MongoDB体系结构
分布式集群:数据备份--安全性,高读写服务的能力和数据存储能力。 通过副本集(replica)对数据进行备份,通过分片(sharding)对大的数据进行分割,分布式存储在不同节点上。
mongodb目前为止支持三种集群模式:主从集群,副本集集群,分片集群。
集群架构的单机实例(mongod instance):只有一个单机实例,客户端与其直接连接使用。 副本集(Replica sets):副本集通常由至少3个节点组成。一个主节点,处理客户端请求,其余是从节点,复制主节点上的数据。 mongodb各个节点常见的搭配方式为:一主多从(正常情况下至少3个节点组成副本集) 主节点记录在其上的所有操作,从节点定期轮询主节点获取这些操作,数据与一致。 选举机制:当一个节点挂掉之后需要满足“大多数”成员投票。

分片(Sharding)
分片是将一个集合的数据分别存储在不同的shard节点上减轻单机压力。根据Shard Keys来划分数据, 数据库提供了两种方法:垂直扩展和分片。垂直扩展:增加CPU、RAM,存储资源等。分片(水平扩展):划分数据集,数据分布到多台服务器中,每个碎片(chard)是独立的数据库 分片集群有三个组件:Shards碎片,存储数据,每个碎片都是一个复制集。query routers:查询路由或mongos实例。configservers:配置服务器,存储集群中的元数据。
集群中的服务器
路由服务器(mongos):路由服务器负责把对应的数据请求请求转发到对应的shard服务器上 mongos,数据库集群请求的入口。 配置服务器(mongos):存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。 配置服务器相当于集群大脑,存储所有数据库元信息(路由、分片)的配置。
集群的组成: 单机mongod 组成副本集 -> 分片, 客户端通过mongos 读取 config servers的信息与分片通信,通过mongos服务器的ip和连接方式,mongos 会自动选择。
Shards:每一个shard包括一个或多个服务和存储数据的mongod进程这些服务/mongod进程在shard中组成一个复制集。
MongoDB的关键特性主要是3个,第一个就是灵活动态的文档模型,第二个是高可用副本集,第三个是MongoDB的水平扩展,也就是sharding。 MongoDB集群包括一定数量的mongod(分片存储数据)、mongos(路由处理)、config server(配置节点)、clients(客户端)、arbiter(仲裁节点:为了选举某个分片存储数据节点那台为主节点)。
MongoDB 复制原理
MongoDB 复制是将数据同步在多个服务器的过程。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。复制还允许从硬件故障和服务中断中恢复数据。 复制: 保障数据的安全性, 数据高可用性 (24*7), 灾难恢复, 无需停机维护(如备份,重建索引,压缩), 分布式读取数据 MongoDB复制原理: 至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。mongodb各个节点常见的搭配方式为:一主一从、一主多从。 客户端从主节点读取数据,在客户端写入数据到主节点时, 主节点与从节点进行数据交互保障数据的一致性。 副本集特征:N 个节点的集群, 任何节点可作为主节点, 所有写入操作都在主节点上, 自动故障转移, 自动恢复。
图形数据库
互联网+、社交网络,智能推荐等的大规模兴起和繁荣。寻找直接朋友或是寻找朋友的朋友这样的遍历查询----图数据库。 图数据库源起欧拉和图理论,面向/基于图的数据库。 以“图”数据结构存储和查询数据,数据模型以节点和关系(边)体现,也处理键值对。 图特征:包含节点和边;节点上有属性(键值对);边有名字和方向,开始\结束节点;边可有属性。图是顶点和边的集合,或图是一些节点和关联联系(relationship)的集合。
G=(V, E) , V=vertex(节点) , E=edge(边) 。节点和关系属性;节点多个标签(类别);一个属性图是由顶点(Vertex),边(Edge),标签(Lable),关系类型和属性组成的有向图。 顶点-节点(Node),边--关系(Relationship)点和关系--实体,节点是独立存在的,节点有设置标签,相同标签节点属于一个分组或集合; 关系通过关系类型来分组,类型相同的关系属于同一个集合。关系是有向的 图数据库可处理大量的、复杂的、互联的、多变的网状数据,适用于社交网络、实时推荐、银行交易环路、金融征信系统等广泛的领域。
Neo4j数据库
Neo4j是开源的用Java实现图数据库,有两种运行方式,一种是服务的方式,对外提供REST接口;另外一种是嵌入式模式,数据以文件的形式存放在本地,直接对本地文件进行操作。 Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。 程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是可以享受到具备完全的事务特性、企业级的数据库的所有好处。
Neo4j数据模型
每个实体都有ID(Identity)唯一标识,每个节点由标签(Lable)分组,每个关系都有一个唯一的类型,属性图模型的基本概念有: 实体(Entity)是指节点(Node)和关系(Relationship); 每个实体都有零个、一个或多个属性,一个实体的属性键是唯一的;每个节点都有零个、一个或多个标签,属于一个或多个分组; 每个关系都只有一个类型,用于连接两个节点; 路径(Path)是指由起始节点和终止节点之间的实体(节点和关系)构成的有序组合; 标记(Token)是非空的字符串,用于标识标签(Lable),关系类型(Relationship Type),或属性键(Property Key); 标签:用于标记节点的分组,多个节点可以有相同的标签,一个节点可以有多个Lable,Lable用于对节点进行分组;关系类型:用于标记关系的类型,多个关系可以有相同的关系类型。属性键:用于唯一标识一个属性;属性(Property)是一个键值对(Key/Value Pair),每个节点或关系可以有一个或多个属性; 属性值可以是标量类型,或这标量类型的列表(数组)。
在下面的图形中,存在三个节点和两个关系共5个实体;Person和Movie是Lable,ACTED_ID和DIRECTED是关系类型,name,title,roles等是节点和关系的属性。 实体包括节点和关系,节点有标签和属性,关系是有向的,链接两个节点,具有属性和关系类型。

1 实体 在示例图形中,包含三个节点,分别是: Name =‘Tom Hanks’ Name=‘Robert Zemeckis’ title=‘Forrest Group’
Born=1956 born=1951 released=1994
2 关系: 包含两个关系是两个关系类型ACTED_IN和DIRECTED,两个关系是连接name属性为Tom Hank节点和Movie节点的关系,和连接name属性为Robert Zemeckis的节点和Movie节点的关系。
3 标签(Lable) 在图形结构中,标签用于对节点进行分组,相当于节点的类型,拥有相同标签的节点属于同一个分组。一个节点可以拥有零个、一个或多个标签,因此,一个节点可以属于多个分组。对分组进行查询,能够缩小查询的节点范围,提高查询的性能。 在示例图形中,有两个标签Person和Movie,两个节点是Person,一个节点是Movie,标签有点像节点的类型,每个节点可以有多个标签。
4 属性(Property)是一个键值对(Key/Value),用于为节点或关系提供信息。每个节点都由name属性,用于命名节点。 在示例图形中,Person节点有两个属性name和born,Movie节点有两个属性:title和released。关系类型ACTED_IN有一个属性:roles(扮演的角色),该属性值是一个数组,而关系类型为DIRECTED的关系没有属性。
5 遍历(Traversal)一个图形,是指沿着关系及其方向,访问图形的节点。关系是有向的,从起始节点沿着关系,一步一步导航到结束节点的过程叫做遍历,遍历经过的节点和关系的有序组合称路径。 在示例图形中,查找Tom Hanks参演的电影,遍历的过程是:从Tom Hanks节点开始,沿着ACTED_IN关系,寻找标签为Movie的目标节点。
Neo4J数据库的存储结构
(1) Nodes(节点,类似地铁图里的一个地铁站): 图的基本单位节点和关系,都可包含属性,关系和节点还可以有零到多个标签。
(2) Relationships(关系,类似两个相邻地铁站之间路线): 组织和连接节点,一个开始节点和一个结束节点。关系有方向进和出。
(3) Properties(属性,类似地铁站的名字,位置,大小,进出口数量等):节点和关系可以拥有0到多个属性,属性类型java的数据类型一致,分为数值、字符串、布尔、以及其他的一些类型,字段名必须是字符串。
(4) Labels(标签,类似地铁站的属于哪个区): 标签通过形容一种角色或者给节点加上一种类型,一个节点可有多个类型,标签在给属性建立索引或者约束时候也会用到。
(5) Traversal(遍历,类似看地图找路径): 查询是遍历图谱然后找到路径,一个开始节点,遍历相关路径上的节点和关系,得到最终的结果。
(6) Paths(路径,类似从一个地铁站到另一个地铁站的所有的到达路径): 路径是一个或多个节点通过关系连接起来的产物。
(7) Schema(模式,类似存储数据的结构): neo4j是一个无模式或less模式的图谱数据库,使用它不需要定义任何schema。
(8)Indexes(索引): 遍历图通过需要大量的随机读写,在字段属性上构建索引,构建索引是一个异步请求,在后台创建直至成功后,才能生效。
(9)Constraints(约束): 约束定义在某个字段上,限制字段值唯一,创建约束会自动创建索引。
Node和Relationship 的 Property 是用一个 Key-Value 的双向列表来保存的; Node 的 Relatsionship 是用一个双向列表来保存的,通过关系,可以的找到关系的前导和后继节点( from-to Node). Node 节点保存第1个属性和第1个关系ID。图的存储结构包括5类文件:
(1) 存储 node 的文件, 存储节点数据、节点label及其序列Id包括存储节点数组、数组的下标即是该节点的ID 、最大的ID 及已经free的ID。
(2)存储 relationship 的文件: 存储关系数据、关系组数据、关系类型、关系类型数组数据、关系类型的名称及其序列Id包括存储关系 record 数组数据、关系 group数组数据、储关系类型数组数据、关系类型 token 数组数据 和ID。
(3)存储 label 的文件: label token数据、名字数据及其序列Id 包括存储lable token 数组数据、 label token 的 names 数据 和ID。 (4)存储 property 的文件:属性数据、类型、索引等及其序列Id 包括 property 数据、property (key-value 结构)的是数组的数据、 property (key-value 结构)的值是字符串的数据、property (key-value 结构)的key 的索引数、property (key-value 结构)的key 的字符串值和ID。
(5)其他的文件: 版本信息、日志等
Neo4j 主要有节点、属性、关系等文件是以数组作为核心存储结构; 同时对节点、属性、关系等类型的每个数据项都会分配一个唯一的ID,在存储时以该ID 为数组的下标。 在访问时通过其ID作为下标,实现快速定位。 所以在图遍历等操作时,可以实现 free-index。
集群方式
Neo4j主要有两种cluster方式:Ha(High avaiable)和Causal cluster方式。集群的主要特点:高吞吐量,持续可靠性,灾难恢复。 Causal cluster: 1)核心服务器(core server),处理读写的操作,大多数的核心服务器主要处理写操作和 2)一个或多个读复制服务器(read replicas),只读的实例,数据从核心服务器异步更新,这些适用于广泛的数据地理分布,并允许跨大量服务器扩展查询工作负载。 HA cluster: 至少有三台服服务器组成,1主2从,主服务器完成写入之后同步数据到从服务器,主服务器既可以写也能读,从服务器只能读。HA群集可用于全天候正常运行并提高读取性能。
在这里以3个节点的Neo4j组成集群为例子, 讨论其体系结构和数据的操作原理。 图展示了由三个Neo4J结点所组成的Master-Slave集群。每个集群都包含一个Master和多个Slave。Master负责数据的写入,接下来Slave则会将Master中的数据更改同步到自身。
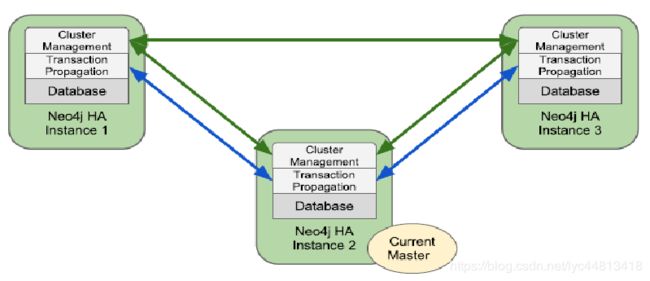
集群数据的写入通过Master完成,图数据修改的复杂性(修改图结点本身、维护各个关系等),图所进行的操作是读比写多很多。 Neo4J内部还有一个写队列,暂时缓存向Neo4J实例的写入操作,从而使得Neo4J能够处理突然到来的大量写入操作。 在最坏的情况就是Neo4J集群需要面对持续的大量的写入操作。需要考虑Neo4J集群的纵向扩展了。
集群的读入
数据的读取可以通过集群中的任意一个Neo4J实例来完成。 Neo4J内部使用一个缓存记录最近所访问的数据。这些缓存数据会保存在内存中以便快速地响应数据读取请求。 Neo4J所提供的解决方案被称为Cache-based Sharding。使用同一个Neo4J实例来响应一个用户所发送的所有需求。
集群容错机制
集群中一个实例失效了,其它实例会在短时间内探测到,恢复到正常状态将数据同步到最新。Master失效通过内置的Leader选举功能选举出新的Master。 在Cluster Management组成的帮助下,可以创建一个Global Cluster。其拥有一个Master Cluster以及多个Slave Cluster。数据的写入通常都是在Master Cluster中进行,而Slave Cluster将只负责提供数据读取服务。