第四章 数据字典详解
gp 是基于 PostgreSQL开发的,大部分数据字典是一样的;gp 也有自动的一些数据字典,一般是以 gp_ 开头
4.1 oid 无处不在
oid 是一种特殊的数据类型,在 PG/GP 中,oid 都是递增的,每一个表空间、表、索引、数据文件名、函数、约束等都对应有一个唯一标识的 oid。oid 是全局递增的,可以把 oid 想象成一个递增的序列(SEQUENCE)
通过下面的语句可以找到数据字典中带隐藏字段 oid 的所有表,这些表的 oid 增加都是共享一个序列的。还有其他表也是共享这些序列,如 pg_class 的 relfilenode

1

2

3
由于数据库中存在大量的 oid ,oid 是一个32位的数字,下面几种可以把 oid 转换的类型:

4
最常用的是 regclass,它关联数据字典的 oid,使用方法:

5

6
这样就可以通过 regclass 寻找一个表的信息,就不用去关联 pg_class 和 pg_namespace(记录 schema 信息)。
其他:
- regproc(regprocedure)与 pg_proc(保存普通函数的命令)
- regoper(regoperator)与 pg_operator(操作符)的 oid 关联
4.2 数据库集群信息
gp的集群配置信息在 Master 上面,这些配置信息对集群管理非常重要,通过这些配置信息可以了解整个集群的状况,可是得知是否有节点失败,通过修改这些配置可以实现集群的扩容等操作
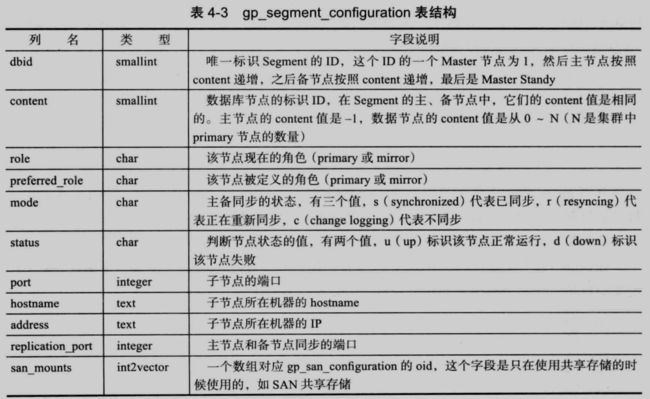
4.2.1 Gp_configuration 和 gp_segment_configuration
在 gp 3.x 版本中,集群的配置信息记录在 gp_configuration 中。表 gp_configuration 中的字段含义如下:

7
在 gp 4.x 版本中,由于引入了文件空间(filespace)的概念,一个节点的数据目录可以是多个,因此将 gp_configuration 拆分成两个表,gp_segment_configuration 和 pg_filespace_entry 。gp 4.x 引入了基于文件的数据同步策略,索引页相应增加了几个数据字典来体现这一特性:
8
这两个表是在 pg_global 表空间下面的,是全局的,同一个集群中所有数据库共用的信息
4.2.2 Gp_id
在 gp 3.x 中,每一个子节点都有 gp_id 表,这个表记录该节点在集群中的配置信息

9
在 gp 4.x 中,这个 gp_id 表已经废弃掉,所有子节点的 gp_id 数据都是一模一样的:

10
因此这些信息都是在启动子节点的时候通过 pg_ctl 的启动参数传进了的,这些信息在 gp 4.x 中都是以数据库参数的形式存在的,所以可以建一个视图,获取跟 gp 3.x 中 gp_id 表一模一样的信息

11
gp_id 表除了其本身所要表达的数据之外,还有一个特殊的功能:这个表在每一个数据节点中都只有一条数据,这对获取子节点的数据十分有用
4.2.3 Gp_configuration_history
当数据节点失败的时候,gp Master 通过心跳检测机制检测出 Segment 失败,就会触发 主、备数据节点切换的动作,每一个动作都会记录在 gp_configuration_history 表中。gp_configuration_history 表结构如下:

12
当数据库发生切换时可以通过 gp_configuration_history 表来了解数据库切换的原因,以及发生切换的时间
4.2.4 pg_filespace_entry
文件空间(filespace)(gp 4.x)一个数据库的数据节点可以有多个数据目录,所以数据目录的字段信息从 gp_configuration 中抽离出来,保存在 pg_filespace_entry 表中:

13
4.2.5 集群配置信息表转化
应用场景:gp 3.x 和 gp 4.x 的集群同时存在,或者 gp 3.x 升级到 gp 4.x 时,外部程序如果需要获取 gp 集群的配置信息,就必须对 gp 3.x 和 gp 4.x 分别进行识别处理,使其对应不同的数据字典。
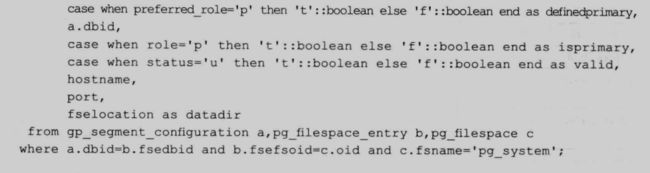
可以统一定义一个视图,将 gp 4.x 的集群配置的数据字典转换成 gp 3.x 的模式:
gp 3.x 的视图定义:
![]()
14
gp 4.x 的视图定义:

15
16
4.3 常用数据字典
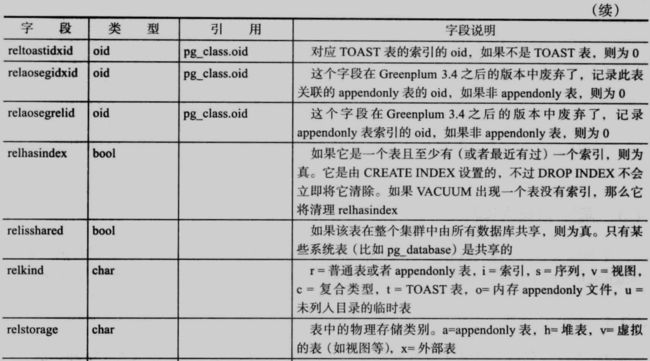
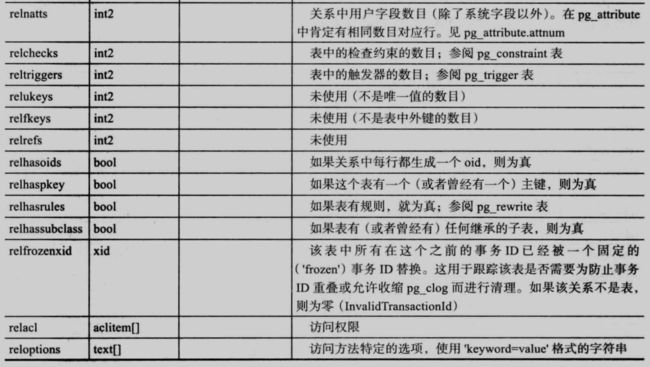
4.3.1 pg_class
pg_class:数据字典中最重要的一个表,保存了所有表、视图、序列、索引的原数据信息,每一个 DDL/DML cozy都必须跟这个表发生联系:

17

18
19
20
建在这个表上的索引:

21
权限控制,通过pg_class.relacl 可查:

22
具体解释:

23
利用数据库中的其他函数更方便的查权限:

24
查询 role_aquery 用户是否具有访问 public.cxfa3 表的 select 权限,结果为 't' 表示有这个权限,结果为 'f' 表示没有这个权限
![]()
25

26
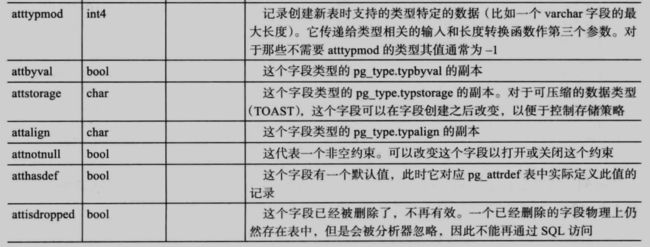
4.3.2 pg_attribute
pg_attribute:记录字段内容:

27
28

29
同一个表在 pg_attribute 中的记录数会比实际表的字段数多,这是因为表中有很多的隐藏字段:

30

31
4.3.3 gp_distribution_policy
表的分布键保存在 gp_distribution_policy 表中:

32
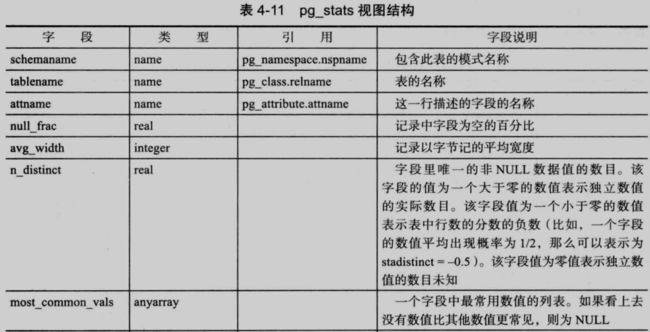
4.3.4 pg_statistic 和 pg_stats
数据库中表的统计信息保存在 pg_statistic 中,表中的记录是由 ANALYZE 创建的,并且随后被查询规划器使用。注意所有统计信息天生都是近似的数值
对应 pg_statistic 有一个视图 pg_stats,可以方便我们查看 pg_statistic 的内容。这个视图的数据比 pg_statistic 好理解:
33

34
4.4 分区表信息
4.4.1 如何实现分区表
分区的意思是把逻辑上的一个大表分割成物理上的几块。gp 中分区表的实现基本上是与 pgsql 中实现的原理一样,都是通过表继承、规则、约束来是实现的。
pgsql 中分区表的建立步骤:
-
创建“主表”,所有分区都从它继承:这个表没有数据,不要澡这个表上定义任何检查约束,除非希望约束同样也适用于所有分区;在主表上定义任何索引或唯一约束都每一意义。
-
创建几个“子表”,每个都从主表上继承。通常,这些表不会增加任何字段。子表即分区。
-
为分区表增加约束,定义每个分区允许的键值
典型的例子是:

35
确保这些约束在不同的分区中不会有重叠的键值,一个常见的错误是设置下面这样的范围:

36
这里的错误是因为没明确指定 200 所属的区间
注意在范围和列表分区的语法方面没有什么区别,这些术语只是用于描述.
-
对于每个分区,在关键字字段上创建一个索引,以及其他想创建的索引。关键字字段索引并非必需的,但是在大多数情况下它是很有帮助的。如果希望关键字值是惟一的,那么应该总是为每个分区创建一个唯一或主键约束
-
定义一个规则或触发器,把对主表的修改重定向带合适的分区表
对于 gp 来说,分区表的实现原理与上面一样,只不过 gp 对分区表进行了一个更好的封装,使用户使用起来更加方便,可以通过 create table 直接建立分区表,可以使用 alter table 等对分区表进行操作
跟 pgsql 一样,分区表的子表也是通过对父表的继承得来的,这些继承关系是放在 pg_inherts 这个数据字典中的。
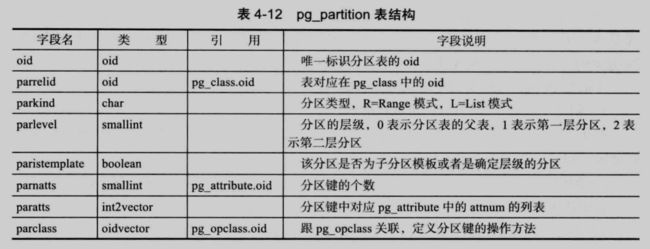
4.4.2 pg_partition
一个表是否是分区表保存在 pg_partition 中,如果一个表是分区表(不包括自分区),则对应有一条记录在这个数据字典中:
37
该表有 3 个索引:

38
如果想查询一个表是否是分区表,只要将 pg_partition 与 pg_class 关联,然后执行 count 即可,如果这个表中有数据,则为分区表,否则不是分区表。

39
4.4.3 pg_partition_rule
分区表的分区规则保存在 pg_partition_rule。在这个表中,可以找到一个分区表对应的子表有哪些即分区规则等信息:

40

41
4.4.4 pg_partitions 视图及其优化
在 gp 中,定义了一个 pg_partitions 的视图,方便对分区表进行查看,这个视图的定义非常复杂,考虑了多重分区的情况,对很多数据字典做了连接和内连接。因此,当数据字典很大时,查询这个预提的效率极差,不能很好地利用索引,查询采用的是全表扫描。下面定义一个函数来代替 pg_partitions 视图,充分利用索引,查询是通过 regclass 减少表的关联,大大提高查询的效率。

123
在查询时通过 ::regclass 来查询表信息:

42
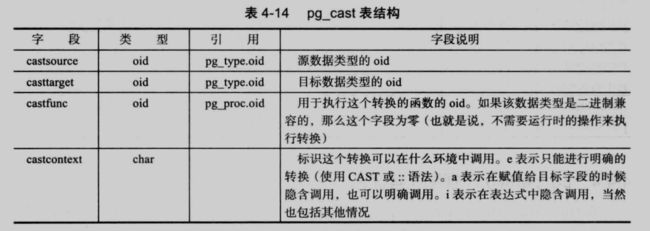
4.5 自定义类型以及类型转换
在 gp 中,经常使用 cast 函数或 ::type 进行类型转换,究竟哪两种类型之间是可以转换的,哪两种类型之间不能转换,转换的规则是什么,这些都在 pg_case 中定义了:
43
要想知道 text 类型到 date 类型的转换是用了哪个函数,可以这么查:

44
可以看出,cast('20110302' as date) 和 '20110302'::date 其实都调用了 date('20110302') 函数进行类型转换。
自定义转换类型,例如gp 默认的类型转换中,是没有 regclass 类型到 text 类型的转换的:

45
先创建一个类型转换函数:

46
然后定义一个 cast 类型转换规则:

47
这样就定义好了一个类型转换,效果如下:

48
4.6 主、备节点同步的相关数据字典
在 gp4.x 版本之后,数据库主、备节点之间的同步通过基于数据文件的物理备份来实现,这与 gp 3.x 的 逻辑备份有很大的区别。
在 gp 4.x 中,分别由表4-15 中的 5 章数据字典来保存基于数据文件的备份信息。这些数据字典都是用于在主节点与备节点间基于文件备份的同步信息。
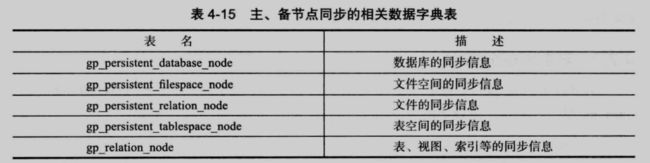
49
在这几张表中,数据量最大、最重要的表应该是 gp_persistent_relation_node 和 gp_relation_node 。这些数据字典在每一个节点中都有,如果主节点和备节点处于完全同步的状态,则主节点和备节点对应的这几张数据字典表的内容应该是一模一样的。
4.7 数据字典应用示例
4.7.1 获取表的字段信息
表名放在 pg_class 中, schema 名放在 pg_namespace 中,字段信息放在 pg_attribute 中。一般关联着 3 张表:
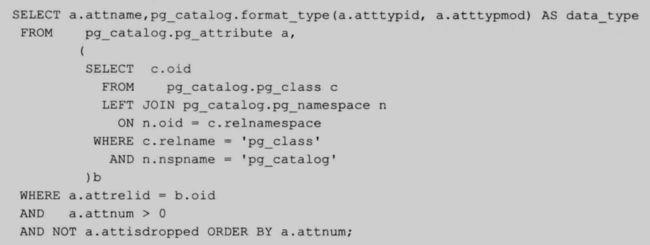
50
使用 regclass 就会简化很多:
SELECT a.attname, pg_catalog.format_type(a.atttypid, a.atttypmod) as data_type
FROM pg_catalog.pg_attribute a
WHERE a.attrelid = 'pg_catalog.pg_class'::regclass
AND a.attnum > 0
AND NOT a.attisdropped
ORDER BY a.attnum;
其实regclass 就是一个类型,oid 或 text 到 regclass有一个类型转换,与夺标关联不一样。
注意:在多数据字典表关联的情况下,如果表不存在,会返回空记录,不会报错,如果采用了 regclass,则会报错,所以在不确定表是否存在的情况下,慎用 regclass。
4.7.2 获取表的分布键
gp_distribution_policy 是记录分布键信息的数据字典,localoid 与 pg_class 的 oid 关联。attrnums 是一个数组,记录字段的 attnum,与 pg_attribyte 从的attnum 关联。

51
这样就可以关联 pg_attribute 来获取分布键:

52
结果如下:

53
4.7.3 获取一个视图的定义
函数 pg_get_viewdef,可以直接获取视图的定义:
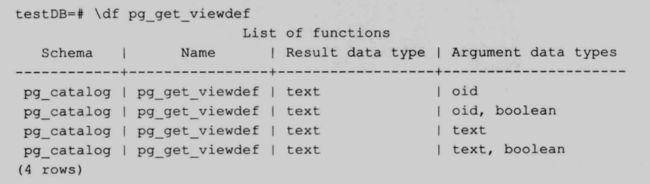
54
使用这个系统函数可以获取上视图的定义,可以传入表的 oid 或表名,第org参数表示十分格式化输出,默认不格式化输出。
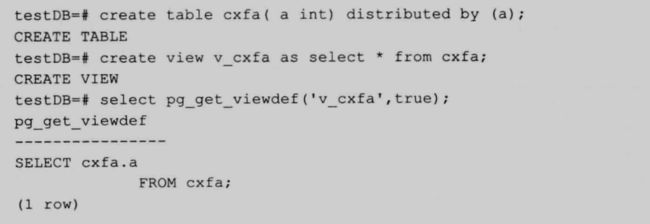
55
这个函数是获取数据字典 pg_rewrite(存储为表和视图定义的重写规则),将规则重新还原出 sql 语句展示给我们。可以通过下面语句去查询数据库保存的重写规则,图4-1是一个简单视图的规则定义:

56
与 pg_get_viewdef 类似的函数还有很多,如图4-2所示。

57
4.7.4 查询 comment(备注信息)
comment 信息是放在表 pg_description 中的:

58
查询表上的 comment 信息:

59
查询表中字段的 comment 信息:

60
4.7.5 获取数据库建表语句
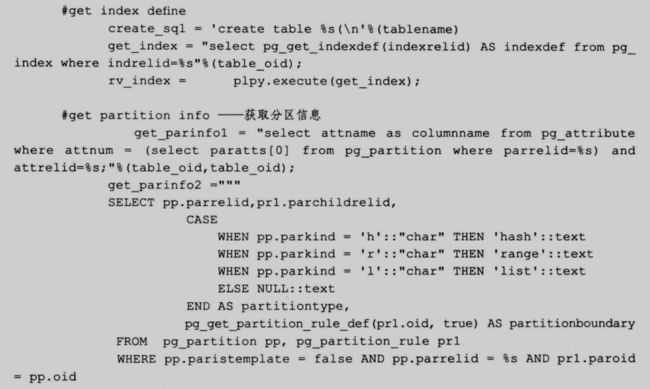
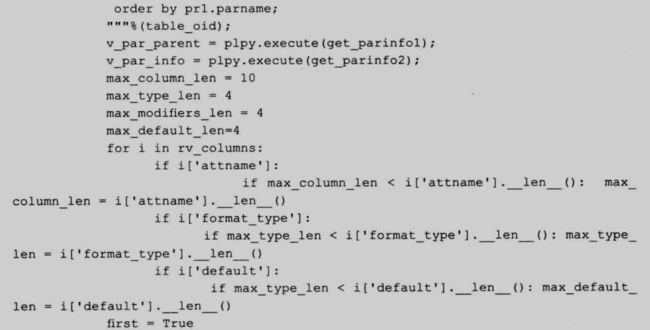
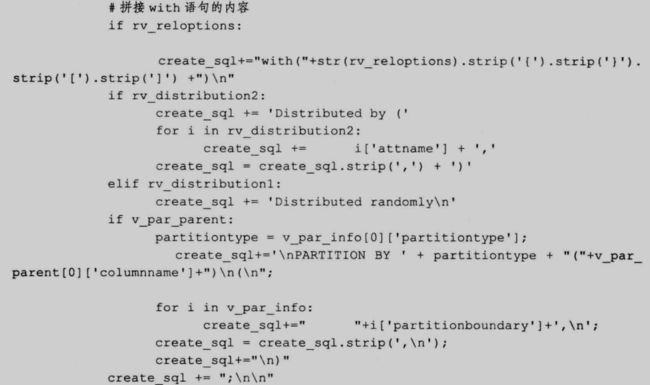
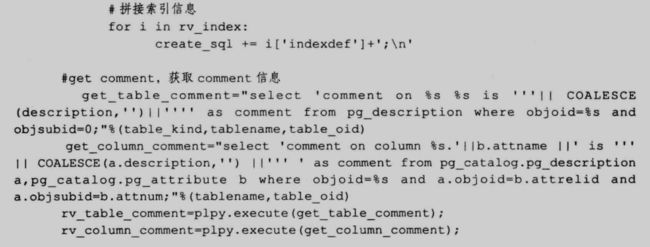
get_create_sql 是用于获取表和视图的 DDL 语句,不支持外部表,建表语句包括以下内容:
- 字段信息
- 索引信息
- 分区信息(主要考虑到性能,目前只支持单一分区键,一层分区)
- comment 信息
- distributed key
- 是否压缩、列存储、appendonly
- 只有一个参数,tablename 为 schemaname.tablename,输出为一个 text 文本。
下面是这个函数的代码:

61

62
如果该表不是一般表或试图,则报错.

63

64
65
66

67

68
69
70
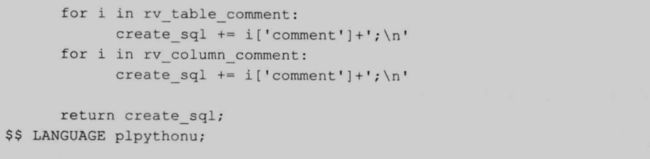
71
图4-3 是一个 get_create_sql 的例子:

72
4.7.6 查询表上的视图
要获取一个表上依赖的视图很麻烦,因为视图定义在 pg_rewite_rule 中,存放成一种规则,而且上面没有索引,所以获取比较麻烦。下面介绍通过 pg_depand 表来获取表上依赖视图的方法(一个视图是定义在表上的,这个视图肯定是依赖于这个表的,所以在 pg_depend 中有响应的信息)
创建一个通过 oid 来获取模式名和表名的函数:
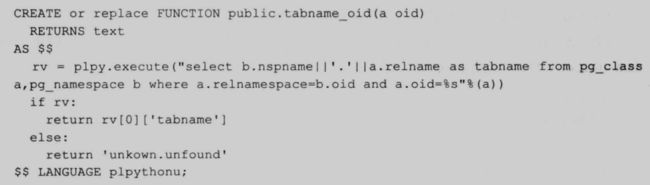
73
然后建立视图:

74

75
下面是如何使用这个视图的例子:

76
4.7.7 查询表的数据文件创建时间
有一个比较取巧的方法来获取一个表的修改时间。在 gp 中,每一个表都对应文件系统上的几个文件,这样我们就可以通过数据文件的创建时间和修改时间估计这个表的创建时间。
通过一些自定义函数,利用数据字典获取数据文件对应的数据目录和文件名,就可以在数据库中获取文件的时间,从而可以定义一个视图来方便查询,相当于自定义一个元数据视图。
(1)如何在数据库中获取一个文件的信息:
gp 自带了一个函数 pg_stat_file。通过它可以获取文件的信息。下面介绍 data_direcotry 目录下 pg_hba.conf 文件的信息。
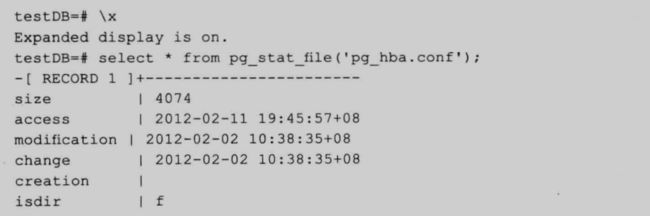
77
但是这个函数只有用在数据库 data_directory 目录(用 show data_directory) 下才可显示。
这在 gp3.x 版本中已经可以完成了,但是 gp4.x 引入了filespace 的概念(具体见第九章),所以在 filespace下面的wfjm不能用 pg_stat_file 来查看。因此下面重新利用 plpythonu 编写一个函数来获取文件信息,同时捕获文件不存在等异常,代码如下:

78

79
(2)利用数据字典拼接出文件目录和文件名:
- 文件名:pg_class 的 relfilenode 字段。
- 表空间:pg_class 的 reltablespace 字段。
- 表空间对应的 filespace:pg_tablespace。
- Filespace 目录:pg_filespace_entry。
- database 的 oid :查询 pg_database 和当前数据库名。
视图的定义如下:

80

81
视图使用效果如图4-4 所示:

82
4.7.8 分区表总大小
下面提供一个函数将检查分区大小的操作封装起来:

83

84

85

86

87
效果如图4-5所示:

88
4.7.9 如何分析数据字典变化
对于 gp 数据字典来说,总的数据字典也只有 60 来张表,如果对于每一个 DDL 命令,我们能够知道有哪些数据字典发生了变化,这样对于我们深入了解数据库底层逻辑有很大的帮助,了解了这些,对数据库优化跟原数据的应用有更深入的帮助。
下面介绍一种方法来观察每一个 sql 对应数据字典的变化,原理是对所有数据字典在 DDL 操作之前跟之后都做一个快照(记录每个表的最大事务 ID 等信息),然后比较两个快照时间的数据发生了哪些变化,从而分析数据字典的变化。
首先需要创建一张表和两个函数:
- catalog_result 表:保存 snapshot 结果的表,每一个表有一个 ID。
- catalog_snap 函数:对当前数据字典的最大 ctid,最小 xmin(事务 id)以及记录数,做一个快照(snapshot),返回快照 ID。
- diff_catalog 函数:比较两个 snapshot 之间的数据差异,找出变化的数据字典。
gp 中记录事务 id 的数据类型 xid 不能进行比较,故使用 UDF 将其转换成integer 类型,方便比较:

89
表结构:
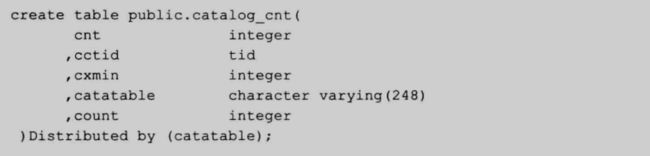
90
创建 snapshot 的函数:
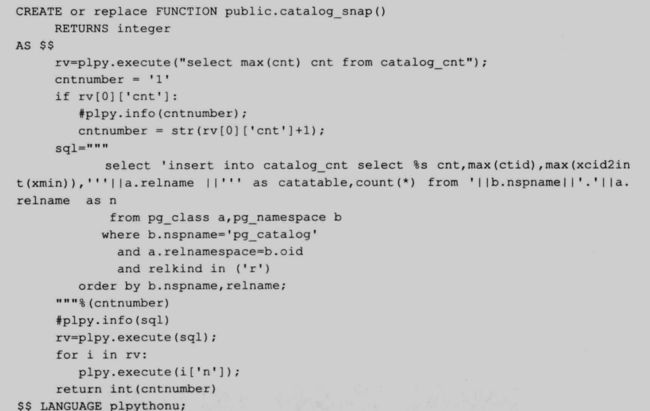
91
比较两个 snapshot 之间差异的函数:

92
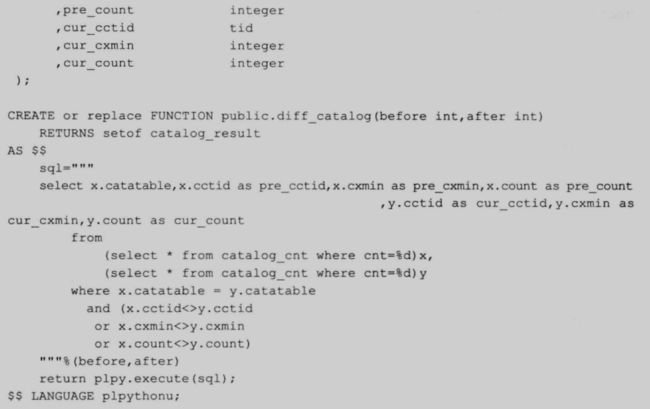
93
使用方式如下:

94
最后使用 diff_catalog 来查看哪些数据字典发生了变化,如图4-6 所示:
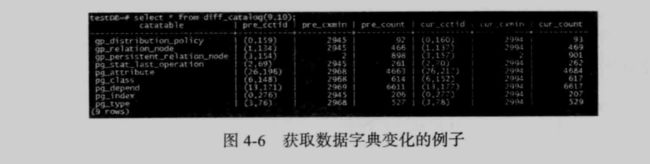
95
以下是使用此方法观察数据字典的注意事项:
- 要在比较干净的测试环境中进行实验,这样分析数据字典时比较快速。
- 这个方法只是主节点上数据字典的变化,要观察 Segment 的变化,可以直接登录到 Segment 节点进行同样的操作。
- 在同一时间,只能有一个 DDL 操作,避免会话进行操作而造成干扰。
- 测试环境应当尽量对数据字典发生 insert 和 update 操作,但是这对常见的 DDL 操作已经足够了,如果要观察到所有的操作,则需要将整个数据字典对进行保存,执行操作后将变化后的数据字典与变化前的变化差异比较得到结果。
4.7.10 获取数据库锁信息
视图 pg_locks 保存了数据库的锁信息,但是这个视图很不方便。要查询一个表被哪个进程锁住了,就需要将 pg_class、pg_locks、pg_stat_activity 关联起来,如下:
SELECT pgl.locktype AS lorlocktyppe, pgl.database AS lordatabase, pgc.relname AS lorrelname, pgl.relation AS lorrelation, pgl.transaction AS lortransaction, pgl.pid AS lorpid, pgl.mode AS lormode, pgl.granted AS lorgranted, pgsa.current_query AS lorcurrentquery
FROM pg_locks pgl
JOIN pg_class pgc ON pgl.relation = pgc.oid
JOIN pg_stat_activity pgsa ON pgl.pid = pgsa.procpid
ORDER BY pgc.relname;
注意:上面这个 sql 就是 gp_toolkit.gp_locks_on_relation 的定义,在 gp3.x 中可以自己创建。
pg_stat_activity 可以获取当前正在运行的 sql。
下面介绍两个函数,杀掉当前的进程,参数都是这个 sql 的进程号(pid)。
- pg_cancel_backend:取消一个正在执行的 sql。
- pg_terminate_backend:终止一个正在执行的 sql。
pg_terminate_backend 比 pg_cancel_backend 的强度大,一般要杀掉 sql 进程,可以先用 pg_cancel_backend 杀掉 sql 进程,如果杀不掉,再用 pg_terminate_backend 将 sql 进程杀掉。
例如,可以利用这个函数,将锁住表 test001 的进程杀掉,如图4-7所示:

96
4.8 gp_toolkit 介绍
gp 4.x 之后的版本提供了 gp_toolkit 的工具箱,方便用户对数据字典进行分析和管理,这个工具箱都是基于数据上字典建立的视图(所有的视图都在 gp_toolkit 的 schema 下面,如果经常使用这个工具箱,建议将这个 schema 加入到 search_path 中):
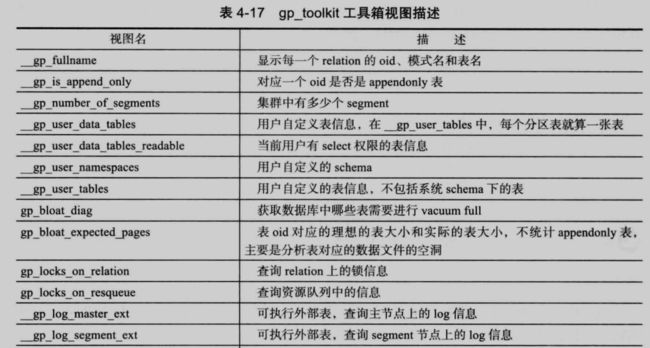
97
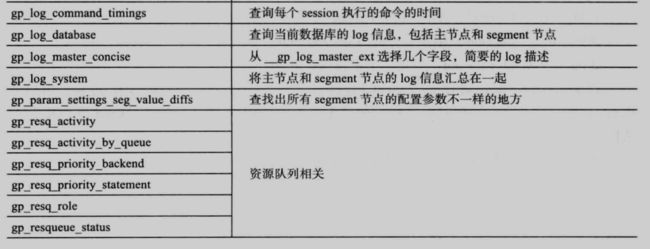
98

99
注意:如果 gp_toolkit 没有安装,可以用下面这个命令进行安装:
psql -f $GPHOME/share/postgresql/gp_toolkit.sql
下面我们选一个视图(gp_bloat_expecter_pages)来详细讲解,以加深对 gp 数据字典的认识。
这个视图是对堆表(heap)理想大小与实际大小的比较。首先看一下这个视图的定义:
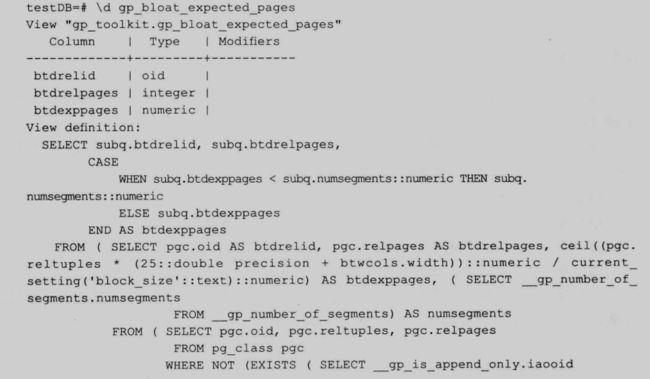
100

101
其中,pg_class 中的 relpages 字段作为实际大小,理想大小通过 pg_statistic 加上 pg_class 两个合起来算,算法如下:

102
从这个视同的定义我们可以看出表大小的估算方法,也可以看到这个视图的局限性:
- 表大小都是估算值,因为统计信息只是估计值,
- 依赖于统计信心收集的时间,要更加准确,需要重新分析、收集最新的信息。
知道了这个方法,我们可以简单验证这个估算方法的准确性,如图4-8所示:

103
这些表的数据都是递增的,即每月发生过 update 和 delete的,所以数据文件中应该是没有空洞的。可以看出,估计值还是有挺大的差异的,所以这个表得出的只能是大概的估计值,对于不同的表,偏差会比较大。
4.9 小结
本章介绍了常用数据字典的表结构,介绍了各个数据字典之间的关系,还通过几个例子加深对数据字典的认识。