基于oracle 11g 的SQL优化
1.查看当前数据库版本:
select* from v$version;(以下示例基于oracle 11.2.0.1.0)
2.ROWID
oracle数据库的表中的每一行数据都有一个唯一的标识符,该标识符表明了该行在oracle数据库中的物理具体位置.
3.execute procedure 命令是在PL/SQL命令窗口执行的。
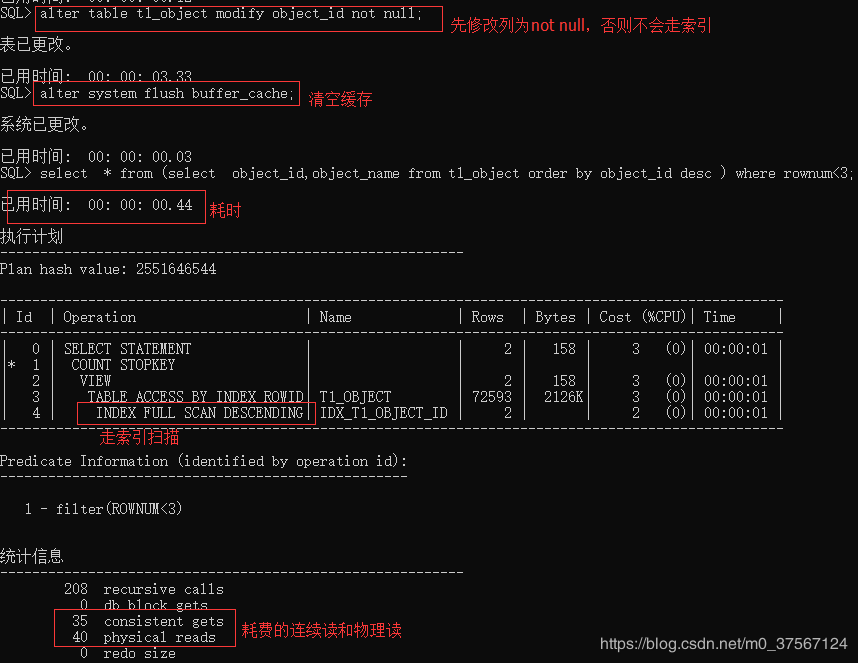
4.SQL/PLUS下查看执行计划详细信息
说明:
recursive calls 用户执行一条SQL语句的时候,Oracle必须调用其他的语句,这些额外调用的语句,就称为"recursive calls"
consistent gets:一致性读,为了保持读一致性而获取的块, 通常情况下针对select语句产生的
db block gets:其实这个名字可能有点歧义,这个表示 no consistent gets,即非一致性读, 通常情况下针对 dml语句产生的
PhysicalReads(物理读)物理读的内容不在内存中,要去硬盘中读入内存,包含了逻辑读。
PhysicalReads=dbblockgets+consistentgets;
LogicalReads(逻辑读)逻辑读内容在内存中,不需要读硬盘。
logical reads= (db block gets + consistent gets) - physical reads。(这里的- physical reads 表示排除物理读)
所以不管是db block gets还是consistent gets,都可能出现了physical reads和logical reads两种情况(由buffer中的是否已经存在需要的数据)
,也即是说,db block gets与consistent gets两者已经构成了一次数据库操作中读取的所有block的总次数了。
因此,logical reads自然也就可以通过如下公式算的:logical reads= (db block gets + consistent gets) - physical reads。
由于在Oracle中,取数据最后都是从Buffer中取,所以每出现一个physical reads必然会出现一次 logical reads,但是这里有一个需要注意的地 方,就是当出现一个physical reads后接着会有一个logical reads这里,实际上这里只算了1 block(physical reads)!
5 sqlplus如何设置SQLPlus结果显示的宽度
SQLPlus查询的结果可以根据自己的屏幕情况进行调节,设置如下:
1.设置页面显示总行数
show pagesize; //首先查看目前的pagesize,默认是14
set pagesize 800; //将pagesize设置好800,则可以一次显示够多行记录了
2.设置行的宽度
show linesize; //查看目前的linesize,默认是80
set linesize 800; //设置成800或者更宽都可
6 查看执行计划的几种方式(常用)
1 explain plan(plsql中按 F5快捷键)
1.1 往 explain plan命令中添加目标SQL
explain plan for select t.id,t2.user_name,t2.note from t_user t, t_user2 t2 where t.id=t2.id;
1.2 PLAN_TABLE$ 用来保存目标SQL的执行计划对应的具体步骤
select * from sys.PLAN_TABLE$;
1.3 查看PLAN_TABLE表中目标SQL执行计划
select * from table(dbms_xplan.display)
说明1 explain plan 查看目标SQL 执行计划时,目标SQL不会真正的执行。
说明2 explain plan得到执行计划不一定准确, 当explain plan 执行的目标SQL绑定变量时,得到执行计划不准确
说明3 explain plan 执行目标为DML语句时会真正去执行,例如 delete from t1。
2 dbms_xplan(适用于SQLPLUS,执行完SQL后,执行)
select * from table(dbms_xplan.display);
select * from table(dbms_xplan.display_cursor(null,null,'advanced'));
select * from table(dbms_xplan.display_cursor('sql_id/hash_value',child_cursor_number,'advanced'));
select * from table(dbms_xplan.display_awr('sql_id'));
-- 说明1 除第一个外,其它3个会真正执行目标SQL。
-- 说明1 除第一个外,其它三个能得到真实的执行计划
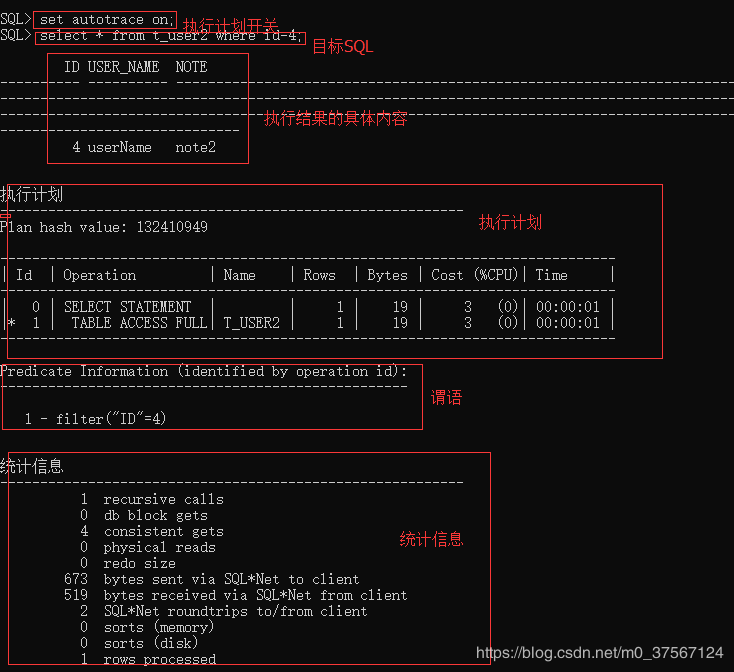
3 autotrace开关(sqlplus)
语法 set autotrace {off| on |traceonly } [explain] [statistics] 默认为off
set timing on (显示执行时间)
set autotrace on (显示执行结果具体内容,执行计划,统计信息)
set autotrace traceonly (显示执行结果数量,执行计划,统计信息)
set autotrace traceonly explain(显示执行计划)
set autotrace traceonly statistics (显示统计信息)
说明1 set autotrace {on,traceonly},执行目标SQL时,目标SQL会真实被执行。
说明2 上面所有autotrace 的执行计划都来源于explain plan ,得到执行计划不一定准确。
7.Buffer Cache与Shared Pool原理
7.1 Buffer Cache

7.2 Buffer Cache

7.3 清空共享池和缓存(sqlplus下)
alter system flush shared_pool;
alter system flush buffer_cache;
8.v s q l 和 v sql和v sql和vsqlarea视图
v$sqlarea和v$sql两个视图的不同之处在于,v$sql中为每一条SQL保留一个条目,
而v$sqlarea中根据sql_text进行group by,通过version_count计算子指针的个数。 v$sqlarea和v$sql的数据存在于shared_pool。
8.1 v$sql 列信息

8.2 v$sqlarea 列信息

9.位图索引
9.1位图索结构(左边表数据,右边位图索引结构)
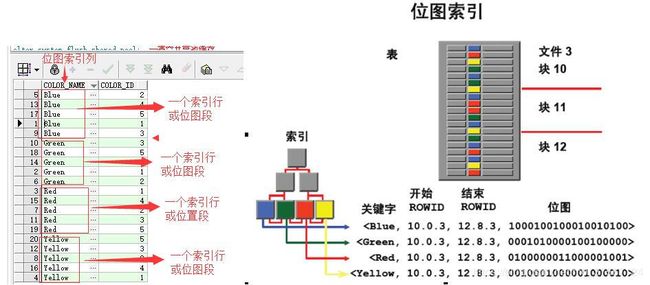
9.2说明:



10 执行计划顺序
10.1 执行计划顺序

示例:

执行步骤:4, 6 ,5, 3, 9, 10, 8 ,13, 12 ,11, 7, 2 ,1, 0
思路:由上往下找到的第一个并列是id为3和7,靠上的(id=3)先执行,再看id=3里面的节点信息, id=4和id=5并列,则上面的(id=4)先执行,然后再看下面,id=5里面有叶子节点则先执行id=6再执行id=5, 接着看id=7里面有id=8和id=11,按照靠上的先执行,则看id=8里面的节点,里面有id=9和id=10并列,则先执行id=9,再执行id=10,再接着看id=11里面的节点,得知执行顺序为13,12,11 最后执行第一个并列节 点的父节点id=2,然后是2,1。
参考博客:http://blog.itpub.net/30126024/viewspace-2141974/
10.2 通过执行脚本显示执行计划顺序
10.2.1 通过管理员账号登陆后执行脚本 F:\WWK\xuexi\oracle\脚本\XPLAN_修正后.sql
脚本包括2个类型和一个包,其中包分为包声明和包体,2都要分开执行,不然后会报错。
10.2.2 然后执行 grant execute on sys.xplan to scott2(用户名);
10.2.3 用scoot2登陆 操作如下:

11 表连接方式以及执行计划
11.1 排序合并连接 Sort Merge
11.1.1 原理

11.1.2 优缺点及适应场景

11.1.3 执行计划

说明:最先扫描t2全表,然后对t2.col2进行排序,然后扫描t1全表,然后对t2.col2进行排序,最后进行合并。
12 嵌套循环连接 Nested Loops
12.1.1 原理

12.1.2 优缺点及适应场景

12.1.3 执行计划
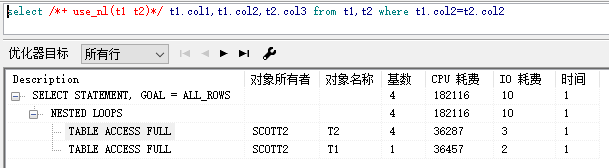
说明 从执行步骤上看先执行 t2 全表扫描(t2 是驱动表),从t2表中取出一条记录到t1表中遍历寻找匹配记录,成功后,再从t2表中取出一 条记录再到t1表中遍历匹配记录,直至全部匹配完。
ordered user_no 则将t1设为驱动表

14 反连接 Anit Join
14.1.1 描述
![]()
14.1.2 not in 和<>ALL执行计划
select * from t1 where col2 not in (select col2 from t2);
select * from t1 where col2 <> all (select col2 from t2);

14.1.3 not exists 执行计划

14.1.4 当连接列上有NULL值时

15 半连接 Semi Join
15.1.1 描述
![]()
15.1.2 int, exists 执行计划
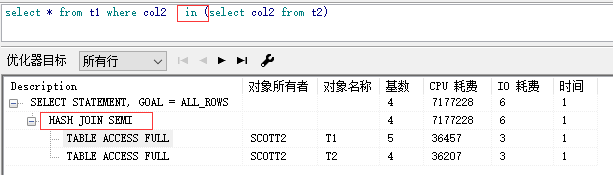
16 AND-EQUEL(INDEX-MARGE)
16.1.1 描述

16.1.2 and-equel 执行计划(如果谓词有一个是唯一索引则不会走and-equal 则会走索引唯一扫描)


![]()
17 oracle里如何做SQL优化
17.1 优化的本质

17.2 通过索引优化
17.2.1 用合适的索引来避免不必要的全表扫描。
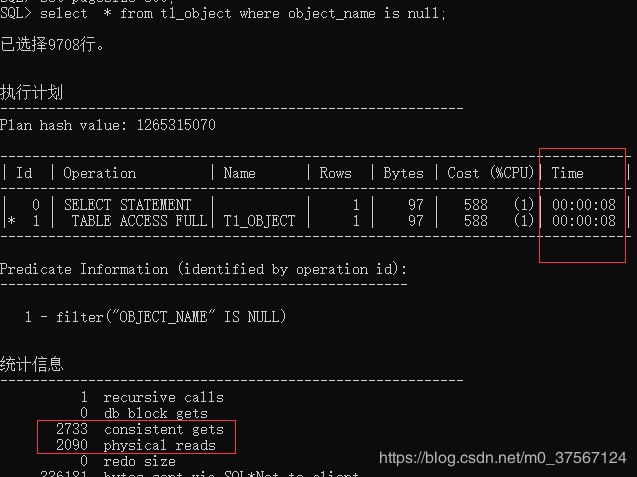
![]()
17.2.1.1 单键值索引对NULL值是不走索引
17.2.1.2 复合值索引对NULL值是不走索引(创建复合索引,第二个参数为常量0 create index idx_t1_object_name on t1_object(object_name,0);)
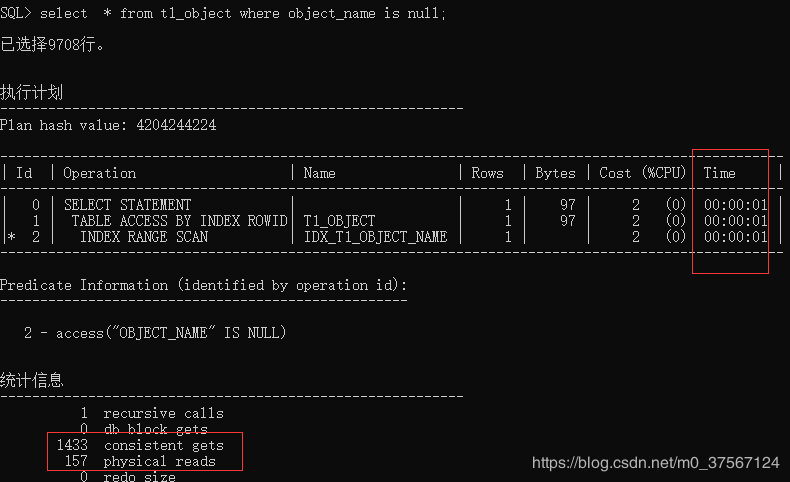
17.3.1 用合适的索引来避免不必要的排序。
17.3.1.1 没有索引的排序

17.3.1.1 有索引的排序 idx_t1_boejct_id