java处理大文件 Mappedbytebuffer与BufferedReader简单比较分析
场景:之前看生产日志,拿到一个多少G文件,用linux命令分割成1G,再vi。有点慢,这次是十几台机器,每台几G文件都要查,再用vi命令有点难搞了。
不能连外网,不然用一些工具应该也好搞。最后还是搞个类来处理算了。思路是先分割成500M左右的小文件,再用UE之类的编辑器找问题。
现在比较流行零拷贝,我就先试了试Mappedbytebuffer,实际效果很慢,后来还是用BufferedReader处理了。日志处理完后,又在自己电脑上回头分析了一下,结论也发一下。
先说Mappedbytebuffer:
源码,直接复制应该就能用了:
public class MappedRead {
public static void main(String[] args) {
long st = System.currentTimeMillis();
String fname = "10g";
long fileLength = 0;// 文件总长
final long limitLength = 1024 * 1024 * 500; // 分割文件大小
String filePath_w = null;
String filePath_r = "F:\\fileTest\\" + fname + ".log";
RandomAccessFile raf_r = null;
RandomAccessFile raf_w = null;
FileChannel fc_r = null;
FileChannel fc_w = null;
try {
MappedByteBuffer mbb_r = null;
MappedByteBuffer mbb_w = null;
raf_r = new RandomAccessFile(filePath_r, "r");
fc_r = raf_r.getChannel();
fileLength = fc_r.size();
long sizeCount = 0L;
long sizeLength = 0L;
for (int i = 0; i < fileLength / limitLength + 1; i++) {
filePath_w = "F:\\fileTest\\out\\" + fname + "_" + i + ".log";
raf_w = new RandomAccessFile(filePath_w, "rw");
fc_w = raf_w.getChannel();
sizeCount = limitLength * i;
sizeLength = sizeCount + limitLength < fileLength ? limitLength : fileLength - sizeCount;
mbb_r = fc_r.map(FileChannel.MapMode.READ_ONLY, sizeCount, sizeLength);
mbb_w = fc_w.map(FileChannel.MapMode.READ_WRITE, 0, sizeLength);
for (long j = 0; j < sizeLength; j++) {
mbb_w.put(mbb_r.get());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fc_r.close();
fc_w.close();
raf_r.close();
raf_w.close();
} catch (Exception e) {
e.printStackTrace();
}
}
long ed = System.currentTimeMillis();
System.err.println(filePath_r + "大小" + fileLength / (1024 * 1024) + "M处理用时:" + (ed - st) / 1000 + "s");
}
}效率:

自己机器上搞了个10G的文件测试的,120s左右
直接用io处理,只怕比这个还快。Mappedbytebuffer原理上是直接操作地址,会极大提高效率,但结果上却一点都不快。稍加分析,问题出在这:
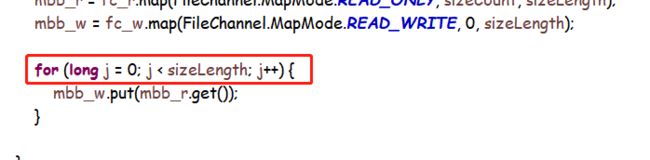
public abstract ByteBuffer put(byte byte0);
这个方法,每次存一个byte,那这个文件多大,就要循环多少次。任你零拷贝速度再快,10G文件也要循环100亿多次。
好了,问题找到了,再想解决方案。如果能避免循环,效率就上去了。看一下Mappedbytebuffer源码,找一下put的批量处理方法。
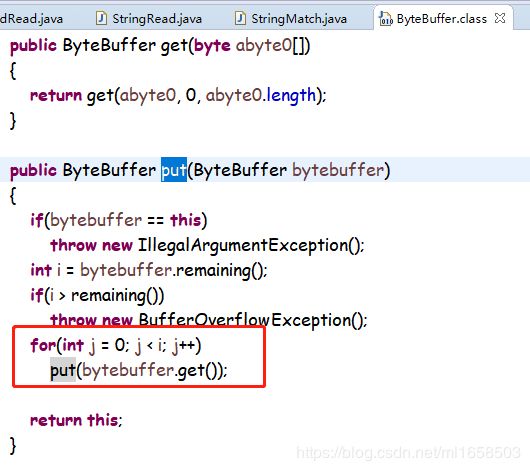
ok,批量方法是找到了,里面直接写了一个循环...666啊
也就是说ByteBuffer及其子类,处理效率基本就这样了。设计上讲mbb_r和mbb_w既然都是Mappedbytebuffer,应该直接有批量set过去的方法,这个for循环实在太low了。100亿次的循环...
再来BufferedReader:
源码:
public class StringRead {
public static void main(String[] args) {
long st = System.currentTimeMillis();
String fname = "10g";
long fileLength = 0;// 文件总长
final long limitLength = 1024 * 1024 * 500; // 分割文件大小
long outLength = 0;// 输出文件长度
BufferedInputStream bis = null;
BufferedReader in = null;
FileWriter fw = null;
String filePath_r = "F:\\fileTest\\" + fname + ".log";
try {
File file_r = new File(filePath_r);
fileLength = file_r.length();
bis = new BufferedInputStream(new FileInputStream(file_r));
in = new BufferedReader(new InputStreamReader(bis));
int count = 0;
for (int i = 0; i < fileLength / limitLength + 1; i++) {
fw = new FileWriter("F:\\fileTest\\out\\" + fname + "_" + count + ".log");
String line = null;
long j = 0;
while (j < limitLength && outLength < fileLength) {
line = in.readLine();
if (null != line) {
fw.append(line + "\r");
j = j + line.length();// 统计单个输出文件大小,当其超过imitLength时中止循环
outLength = outLength + line.length();// 统计总输出文件大小,当其超过fileLength时中止循环
} else {
break;
}
}
fw.flush();
count++;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
fw.close();
in.close();
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
long ed = System.currentTimeMillis();
System.err.println(filePath_r + "大小" + fileLength / (1024 * 1024) + "M处理用时:" + (ed - st) / 1000 + "s");
}
}效率:
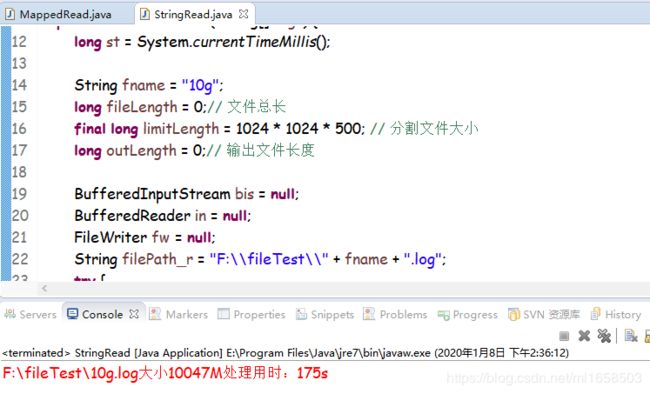
io本来就不快,BufferedReader的readLine()把流转成字符串输出,进一步降低了速度。但是BufferedReader的循环次数要远少于100亿,readLine()是按行读取的,即有多少行就循环多少次。所以效率上讲,BufferedReader不比Mappedbytebuffer慢多少,在我查日志的破电脑上,甚至是BufferedReader更快。约7G文件240秒。
readLine()把流转成字符串输出虽然降低了速度,但我们可以做一些额外的事,比如字符串匹配。后来我在BufferedReader的类里加了个查询,直接文件切割+字段查找一起做了,改进后的代码:
public class StringMatch {
public static void main(String[] args) {
long st = System.currentTimeMillis();
String fname = "78m";
long fileLength = 0;// 文件总长
final long limitLength = 1024 * 1024 * 20; // 分割文件大小
long outLength = 0;// 输出文件长度
/*** 查找功能 ***/
String match = "【66666666666666666】";
FileWriter f_match = null;
BufferedInputStream bis = null;
BufferedReader in = null;
FileWriter fw = null;
String filePath_r = "F:\\fileTest\\" + fname + ".log";
String filePath_w = null;
try {
File file_r = new File(filePath_r);
fileLength = file_r.length();
bis = new BufferedInputStream(new FileInputStream(file_r));
in = new BufferedReader(new InputStreamReader(bis));
f_match = new FileWriter("F:\\fileTest\\match\\match.log", true);// 追加写入
int count = 0;
for (int i = 0; i < fileLength / limitLength + 1; i++) {
filePath_w = "F:\\fileTest\\out\\" + fname + "_" + count + ".log";
fw = new FileWriter(filePath_w);
String line = null;
long j = 0;
while (j < limitLength && outLength < fileLength) {
line = in.readLine();
if (null != line) {
fw.append(line + "\r");
j = j + line.length();// 统计单个输出文件大小,当其超过imitLength时中止循环
outLength = outLength + line.length();// 统计总输出文件大小,当其超过fileLength时中止循环
if (line.indexOf(match) > -1) {
f_match.append(match + "匹配文件《" + filePath_w + "》中记录:" + line + "\r");
}
} else {
break;
}
}
fw.flush();
count++;
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
f_match.close();
fw.close();
in.close();
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
long ed = System.currentTimeMillis();
System.err.println(filePath_r + "大小" + fileLength / (1024 * 1024) + "M处理用时:" + (ed - st) / 1000 + "s");
}
}结果大概就这样

到这我的问题就解决了,BufferedReader还是可以的。顺便也看了下Mappedbytebuffer,收工。