服务框架的技术栈
https://mp.weixin.qq.com/s/rPRTEqJWv59Iba9kHrcgRQ
1. 概述
架构的改变,往往是因为业务规模的扩张。
随着业务规模的扩张,为了满足业务对技术的要求,技术架构需要从单体应用架构升级到分布式服务架构,来降低公司的技术成本,更好的适应业务的发展。分布式服务架构的诸多优势,这里就不一一列举了,今天围绕的话题是服务框架,为了推行服务化,必然需要一套易用的服务框架,来支撑业务技术架构升级。
2. 服务框架
服务框架的核心是服务调用,分布式服务架构中的服务分布在不同主机的不同进程上,服务的调用跟单体应用进程内方法调用的本质区别就是需要借助网络来进行通信。
下图是服务框架的架构图,主流的服务框架的实现都是这套架构,如 Dubbo、SpringCloud 等。
-
Invoker 是服务的调用方
-
Provider 是服务的提供方
-
Registry 是服务的注册中心
-
Monitor 是服务的监控模块
Invoker 和 Provider 分别作为服务的调用和被调用方,这点很明确。但是仅有这两者还是不够的,因为作为调用方需要知道服务部署在哪,去哪调用服务,所以有了 Registry 模块,它的功能是给服务提供方注册服务,给服务调用方发现服务。Monitor 作为服务的监控模块,负责服务的调用统计以及链路分析功能,也是服务治理重要的一环。
3. 核心模块
下图是服务框架的流程图,我们分服务注册、发现、调用三个方面来进行流程分解。
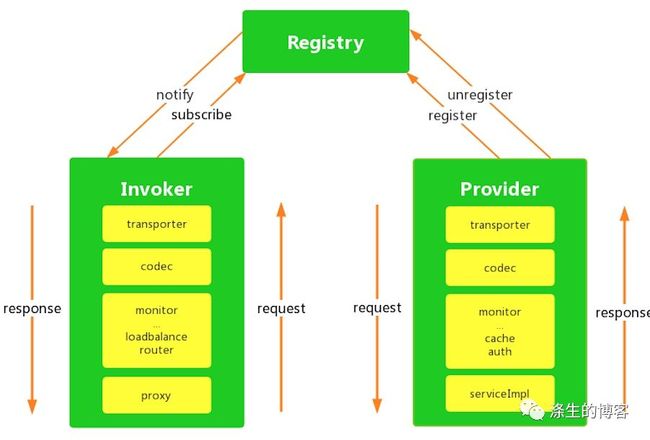 服务注册是服务提供方向注册中心注册服务信息;当提供服务应用下线时,负责将服务注册信息从注册中心删去。
服务注册是服务提供方向注册中心注册服务信息;当提供服务应用下线时,负责将服务注册信息从注册中心删去。
服务发现是服务调用方从注册中心订阅服务,获取服务提供方的相关信息;当服务注册信息有变更时,注册中心负责通知到服务调用方。
服务调用是服务调用方通过从注册中心拿到服务提供方的信息,向服务提供方发起服务调用,获取调用结果。
对照上述流程图,我们按照请求的具体过程进行分析。
作为服务调用方 Invoker 的具体流程是: a. Request 从下往上,由于服务调用方只能拿到服务提供方提供的 API 接口或者 API 接口的 JAR 包,所以服务调用方需要经过一层代理 Proxy 来伪装服务的实现; b. 经过代理 Proxy 之后,会经过路由 Router、负载均衡 LoadBalance 模块,目的是从一堆从注册中心拿到的服务提供方信息中选出最合适的服务提供方机器进行调用。另外,还会经过 Monitor 监控等模块; c. 接着会经过服务编码 Codec 模块,这个模块的目的是因为请求在网络传输前需要按照通信协议以及对象的序列化方式,对传输的请求进行编解码; d. 最终会经过网络通信 Transporter 模块,这个模块将 Codec 编码好的请求进行传输。
作为服务提供方 Provider 的具体流程是: a. Request 从上往下,经过网络通信 Transporter 模块,获取到的是由调用方发送的Request字节数组。 b. 接着经过服务编码 Codec 模块,根据通信协议解出一个完整的请求包,然后使用具体的序列化方式反序列化成请求对象。 c. 紧接着会经过监控、限流、鉴权等模块。 d. 最终会执行服务的真正业务实现 ServiceImpl,执行完后,结果按原路返回。
按照上述流程分解一个服务框架的相关工作,再去看一些开源的服务框架也就不难理解了。一般服务框架的核心模块应该有注册中心、网络通信、服务编码(通信协议、序列化)、服务路由、负载均衡,服务鉴权,可用性保障(服务降级、服务限流、服务隔离)、服务监控(Metrics、Trace)、配置中心、服务治理平台等。
3.1 注册中心
注册中心是用来注册和发现服务的,需要具备的基本功能有注册服务、下线服务、发现服务、通知服务变更等。 当前使用比较多的开源注册中心有 Zookeeper、ETCD、Eureka 等。 Zookeeper 与 ETCD 在整体架构上都比较类似,使用方式非常便捷,应用比较广泛。这两套系统按照 CAP 理论,属于 CP 系统,可用性会差一点,但是作为中小规模服务注册中心,还是游刃有余,并没有某些人说的那么差劲。 Eureka 是 Spring Cloud Netflix 微服务套件中的一部分,很不幸的是 Eureka 2.0 开源工作宣告停止。
3.2 网络通信
服务的调用方和提供方都来自不同的主机的不同的进程,所以要进行调用,必然少不了网络通信。可以说网络通信是分布式系统的重中之重,网络通信框架的好坏直接影响服务框架的性能。从零实现一套性能高,稳定性强的通信框架还是非常难的,好在目前已经有很多开源的高性能的网络通信框架。 针对 Java 生态有 Mina、Netty 等,目前使用最广泛的也当属 Netty。Netty 使用的是 per thread one eventloop 线程模型,这点与 Nginx 等其他高性能网络框架类似。另外,Netty 非常易用,所以网络通信选择 Netty 框架自然是毫无疑问的。
3.3 服务编码
内存对象要经过网络传输前需要做两件事:第一是确定好通信协议,第二序列化。
3.3.1 通信协议
通信协议说白了在发送数据前按照一定的格式来处理数据,然后进行发送,保证接收方拿到数据知道按照什么样的格式进行处理。 有些同学可能不理解,为什么需要通信协议,不是有 TCP、UDP 协议了吗?这里说的不是传输层的通信协议,应该是应用层的协议类似 HTTP。因为的 TCP 协议虽然已经保证了可靠有序的传输,但是如果没有一套应用层的协议,就不知道发过来的字节数据是不是一个完整的数据请求,或者说是多个请求的字节数据都在一起,无法拆分,这就是是所谓的粘包,需要按照协议进行拆包,拆成一个个完整的请求包进行处理。 协议的实现上一般大厂或者开源的服务框架选择自建协议,更偏向服务领域。如 Dubbo,当然也有些框架直接使用 HTTP,HTTP/2,比如 GRPC 使用的就是 HTTP/2。
3.3.1 序列化
由于向网络层发送的数据必须是字节数据,不可能直接将一个对象发送到网络,所以在发送对象数据前,一般需要将对象序列化成字节数据,然后进行传输。 在服务方收到网络的字节数据时,需要经过反序列化拿到相关的对象。 序列化的实现目前现成比较多,如 Hessian、JSON、Thrift、ProtoBuf 等。Thrift 和 ProtoBuf 能支持跨语言,性能比较好,不过使用时需要编写 IDL 文件,有点麻烦。Hessian、JSON 使用起来比较友好,但是性能会差一点。
3.4 服务路由
服务路由指的是向服务提供方发起调用时,需要根据一定的算法从注册中心拿到的服务方地址信息中选择其中的一批机器进行调用。 路由的算法一般是根据场景来进行选择的,比如有些公司实施两地三中心这种高可用部署,但是由于两地的网络延时比较大,那这时就可以实施同地区路由策略,比如上海的调用方请求会优先选择上海的服务进行调用,来降低网络延时导致的服务端到端的调用耗时。 还有些框架支持脚本配置来进行定向路由策略。
3.5 负载均衡
负载均衡是紧接着服务路由的模块,负载均衡负责将发送请求均匀合理的发送到服务提供方的节点上,而备选机器,一般就是经过路由模块选择出来的。 负载均衡的算法有很多,如 RoundRobin、Random、LeastActive、ConsistentHash 等。而且这些算法一般都是基于权重的增强版本,因为需要根据权重来调节每台服务节点的流量。
3.6 服务鉴权
服务鉴权是服务安全调用的基础,虽然绝大部分服务都是公司内部服务,但是对于敏感度较高的数据还是需要进行鉴权的。鉴权的服务需要对服务的调用方进行授权,未经授权的调用方是不能够调用该服务的。 关于服务鉴权的实现大都是基于 token 的认证方案,如 JWT(JSON Web Token) 认证。
3.7 可用性保障
可用性保障模块是服务高可用的一个重要保证。服务在交互中主要分成调用方和提供方两种角色,作为服务调用方,可以通过服务降级提升可用性。作为服务提供方,可以通过服务限流、服务隔离来保证可用性。
3.7.1 服务降级
服务降级指的是当依赖的服务不可用时,使用预设的值来替代服务调用。 试想一下,假设调用一个非关键路径上的服务(也就是说该调用获取的结果是否实时,是否正确不是特别重要)出现问题,导致调用超时、失败等,在没有降级措施的情况下,会直接应用服务调用方业务。 因此,有些非关键路径上服务调用,可以通过服务降级实现有损服务,柔性可用。 开源的降级组件有 Netflix 的 Hystrix,Hystrix 使用比较广泛。
3.7.2 服务限流
服务降级保护的是服务的调用方,也就是服务的依赖方。而服务的提供方呢,如何保证服务的可用性呢? 服务限流指的是对服务调用流量的限制,限制其调用频次,来保护服务。在高并发的场景中,很容易出现流量过高,导致服务被打垮。这里就需要限流来保证服务自身的稳定运行。 Hystrix 也是可以用来限流的,但是用的比较多的有 guava 的 RateLimiter,其使用的是令牌桶算法,能够保证平滑限流。
3.7.3 服务隔离
除了服务限流对服务提供方进行保护,就够了吗? 可能还不够,考虑一下这样的场景,假设某一个有问题的方法出现问题,处理非常耗时,这样会堵住整个服务处理线程,导致正常的服务方法也不能够正常调用。因此还需要服务隔离。 服务隔离指的是对服务执行的方法进行线程池隔离,保证异常耗时方法不会对正常的方法调用产生干扰,进而保护服务的稳定运行,提升可用性。
3.8 服务监控
服务监控是高可用系统不可或缺的重要支撑。服务监控不仅包括服务调用等业务统计信息 Metrics,还包括分布式链路追踪 Trace。 分布式系统监控比单体应用要复杂的多,需要将大量的监控信息进行聚合展示,尤其是在分布式链路追踪方面,由于服务调用过程中涉及到多个分布在不同机器上的服务,需要一个调用链路展示系统方便查看调用链路中耗时和出问题的环节。
3.8.1 Metrics
Metrics 监控主要是服务调用的一些统计报表,包括服务调用次数、成功数、失败数,以及服务方法的调用耗时,如平均耗时,耗时99线,999线等。全方位展示服务的可用性以及性能等信息。 目前开源的 Metrics 监控有美团点评的 Cat、SoundCloud 的 Prometheus 以及基于 OpenTracking 的 SkyWalking。
3.8.2 Trace
Trace 监控是对分布式服务调用过程中的整体链路展示和分析。方便查看链路上各个环境的性能问题。 分布式链路追踪的原理大都是基于 Google 的论文 Dapper, a Large-Scale Distributed Systems Tracing Infrastructure。 开源的分布式链路追踪系统有美团点评的 Cat,基于 OpenTracking 的SkyWalking、Twitter 的 ZipKin。
3.9 配置中心
配置中心不光是常见的系统需要,服务框架也需要,它能够对系统中使用的配置进行管理,也能够针对修改配置动态通知到应用系统。 一套完善的服务框架,必然少不了配置,如一些动态开关、降级配置、限流配置、鉴权配置等。 开源的配置中心有阿里的 Diamond,携程的 Apollo。
3.10 治理平台
治理平台指的是对服务进行管理的平台。微服务微了之后,必然会导致服务数量的上升,如果没有一个完善的治理平台,服务规模扩大之后,很难去维护,也必然导致故障频频,并且极度影响开发效率。 治理平台主要是服务功能的相关操作平台,包括服务权重修改、服务下线、鉴权降级等配置修改等。 治理平台跟服务框架的耦合比较强,所以开源的比较少。
4. 总结
一套优秀全面的服务框架,包含各个方面的核心模块,每个模块各自展开又是一个细分领域,都可以抽象成单独的组件。后续文章将会围绕各个模块的知识细节进行展开。