人工智能 - 理解
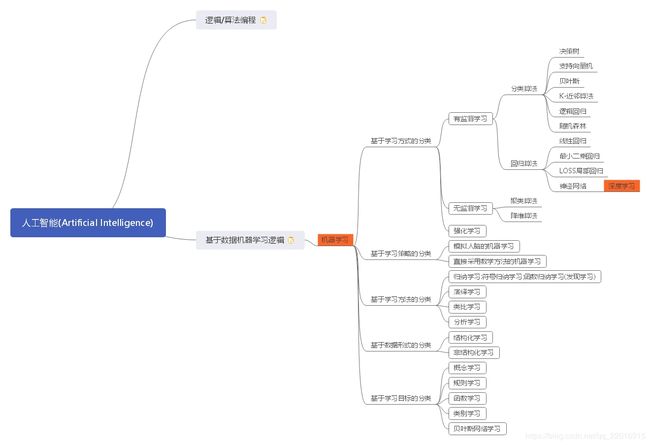
逻辑/算法编程:由人工编程指定逻辑和算法,从而实现预定义的弱人工智能
基于数据机器学习逻辑:提供大量数据由通过算法来学习内在的逻辑
1 人工智能
1.1 概念理解
人工智能(Artificial Intelligence)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。包括机器人、语言识别、图像识别、自然语言处理和专家系统等。
人工智能是一门极富挑战性的科学,从事这项工作的人必须懂得计算机知识,心理学和哲学。
人工智能研究的一个主要目标是使机器能够胜任一些通常需要人类智能才能完成的复杂工作。但不同的时代、不同的人对这种“复杂工作”的理解是不同的
1.2 科学介绍
1.2.1 实际应用
机器视觉,指纹识别,人脸识别,视网膜识别,虹膜识别,掌纹识别,专家系统,自动规划,智能搜索,定理证明,博弈,自动程序设计,智能控制,机器人学,语言和图像理解,遗传编程等
1.2.2 学科范畴
人工智能是一门边缘学科,属于自然科学和社会科学的交叉
1.2.3 设计学科
哲学和认知科学,数学,神经生理学,心理学,计算机科学,信息论,控制论,不定性论
1.2.4 研究范畴
自然语言处理,知识表现,智能搜索,推理,规划,机器学习,知识获取,组合调度问题,感知问题,模式识别,逻辑程序设计软计算,不精确和不确定的管理,人工生命,神经网络,复杂系统,遗传算法
2 机器学习
2.1 概念理解
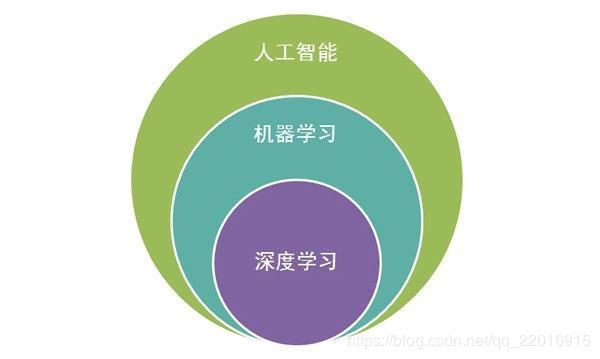
机器学习(Machine Learning,ML)是人工智能的子领域,也是人工智能的核心。
专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。
机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论,凸分析,算法复杂度理论等多门学科。
机器学习是一门多学科交叉专业,涵盖概率论知识,统计学知识,近似理论知识和复杂算法知识,使用计算机作为工具并致力于真实实时的模拟人类学习方式, 并将现有内容进行知识结构划分来有效提高学习效率。
我们在这里提到的机器学习更多是让机器帮助人类做一些大规模的数据识别、分拣、规律总结等人类做起来比较花时间的事情。
机器学习是人工智能最重要的内容,先看它的定义(有很多定义)
“Machine learning is the idea that there are generic algorithms that can tell you something interesting about a set of data without you having to write any custom code specific to the problem. Instead of writing code, you feed data to the generic algorithm and it builds its own logic based on the data.”
这里面有几个重要的关键词,就是你不用写专门的业务逻辑代码而是通过输入大量的数据给机器,由机器通过一个通用的机制来建立它自己的业务逻辑,也就是机器“自我学习”了业务的逻辑,当然这种学习后的逻辑可以用来处理新的数据。这和人类的学习过程有些类似,如下图:

机器学习有下面几种定义:
(1)机器学习是一门人工智能的科学,该领域的主要研究对象是人工智能,特别是如何在经验学习中改善具体算法的性能。
(2)机器学习是对能通过经验自动改进的计算机算法的研究。
(3)机器学习是用数据或以往的经验,以此优化计算机程序的性能标准。
-机器学习,就是在任务T上,随经验E的增加,效果P随之增加。
-机器学习的过程是通过大量数据的输入,生成一个模型,再利用这个生成的模型,实现对结果的预测。
机器学习是不断的训练过程,其模型是在连续的优化调整中,随着训练数据越多其模型越准确,但是人类的学习不仅仅是一个连续的学习过程,还是一种跳跃式学习,也就是常常所说的“顿悟”,这是机器学习所没有的。
同时,机器学习是通过大量的数据 来训练得到模型,因此模型考虑的是相关性逻辑,而不是因果性逻辑
举个例子,假设要构建一个识别猫的程序。传统上如果我们想让计算机进行识别,需要输入一串指令,例如猫长着毛茸茸的毛、顶着一对三角形的的耳朵等,然后计算机根据这些指令执行下去。但是如果我们对程序展示一只老虎的照片,程序应该如何反应呢?更何况通过传统方式要制定全部所需的规则,而且在此过程中必然会涉及到一些困难的概念,比如对毛茸茸的定义。因此,更好的方式是让机器自学。
我们可以为计算机提供大量的猫的照片,系统将以自己特有的方式查看这些照片。随着实验的反复进行,系统会不断学习更新,最终能够准确地判断出哪些是猫,哪些不是猫。
2.2 常见算法
(1)决策树算法
(2)朴素贝叶斯算法
(3)支持向量机算法
(4)随机森林算法
(5)人工神经网络算法
(6)Boosting与Bagging算法
(7)关联规则算法
(8)EM(期望最大化)算法 i
(9)深度学习
2.3 机器学习常见名词
2.3.1 有监督学习和无监督学习
有监督学习:训练用历史数据是既有问题又有答案
无监督学习:训练用历史数据是只有问题没有答案
注:正式的说法是一般把答案称之为标签(label)
半监督学习:介于有监督学习和无监督学习之间的混合学习方法
无监督学习中,主要是发现数据中未知的结构或者是趋势。虽然原数据不含任何的标签,但我们希望可以对数据进行整合(分组或者聚类),或是简化数据(降维、移除不必要的变量或者检测异常值)。
因此无监督算法主要的分类包含:
- 聚类算法 (代表:K均值聚类,系统聚类)
- 降维算法 (代表:主成份分析PCA【1】【2】,线性判断分析LDA)
有监督学习中,可以根据预测变量的类型再细分。如果预测变量是连续的,那这就属于回归问题。而如果预测变量是独立类别(定性或是定类的离散值),那这就属于分类问题了。
因此有监督学习主要的分类包含:
- 回归算法 (线性回归,最小二乘回归,LOESS局部回归,神经网路,深度学习)
- 分类算法(决策树,支持向量机,贝叶斯,K-近邻算法,逻辑回归,随机森林)
上面提到的算法今后的学习中会经常看到,先混个眼熟
以上算法中,目前最热的是深度学习,学习之前必须先了解它的前任(前生,父类)——神经网络。
2.3.2 神经网络
神经网络介绍网上有很多,推荐/参考如下几篇文章学习:
-神经网络浅讲:从神经元到深度学习
-用平常语言介绍神经网络
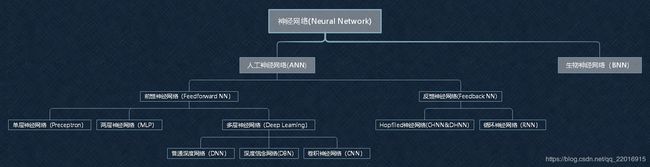
-庞大的神经网络是基于神经元结构的,是输入乘以权重,再求和,再过非线性函数的过程。
3 深度学习
3.1 概念理解
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能
深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术
深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果
3.2 研究内容
深度学习是一类模式分析方法的统称,就具体研究内容而言,主要涉及三类方法:
(1)基于卷积运算的神经网络系统,即卷积神经网络(CNN)。
(2)基于多层神经元的自编码神经网络,包括自编码( Auto encoder)以及稀疏编码两类( Sparse Coding)。
(3)以多层自编码神经网络的方式进行预训练,进而结合鉴别信息进一步优化神经网络权值的深度置信网络(DBN)。
深度学习是机器学习的一种,而机器学习是实现人工智能的必经路径。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。
深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等
3.3 特点
区别于传统的浅层学习,深度学习的不同在于;
(1)强调了模型结构的深度,通常有5层、6层,甚至10多层的隐层节点;
(2)明确了特征学习的重要性。也就是说,通过逐层特征变换,将样本在原空间的特征表示变换到一个新特征空间,从而使分类或预测更容易。与人工规则构造特征的方法相比,利用大数据来学习特征,更能够刻画数据丰富的内在信息
3.4 深度学习典型模型
(1)卷积神经网络模型;(2)深度信任网络模型;(3)堆栈自编码网络模型
3.5深度学习训练过程
(1)自下上升的非监督学习;(2)自顶向下的监督学习
3.6 应用
(1)计算机视觉;(2)语音识别;(3)自然语言处理
4 机器学习与深度学习的比较
(1)应用场景
机器学习在指纹识别、特征物体检测等领域的应用基本达到了商业化的要求。
深度学习主要应用于文字识别、人脸技术、语义分析、智能监控等领域。目前在智能硬件、教育、医疗等行业也在快速布局。
(2)所需数据量
机器学习能够适应各种数据量,特别是数据量较小的场景。如果数据量迅速增加,那么深度学习的效果将更加突出,这是因为深度学习算法需要大量数据才能完美理解。
(3)执行时间
执行时间是指训练算法所需要的时间量。一般来说,深度学习算法需要大量时间进行训练。这是因为该算法包含有很多参数,因此训练它们需要比平时更长的时间。相对而言,机器学习算法的执行时间更少。
(4)解决问题的方法
机器学习算法遵循标准程序以解决问题。它将问题拆分成数个部分,对其进行分别解决,而后再将结果结合起来以获得所需的答案。深度学习则以集中方式解决问题,而不必进行问题拆分。
参考文章
--人工智能学习笔记-基本概念