#每天一篇论文#232/365 基于计连续对抗学习自监督深度里程
Sequential Adversarial Learning for Self-Supervised Deep Visual Odometry
摘要
我们提出了一个视觉里程计(vo)的自监督学习框架,该框架结合了连续帧的相关性,并利用了对抗学习的优势。以前的方法将自监督vo作为运动局部结构(sfm)来处理,通过最小化扭曲图像和捕获图像之间的光度损失,从图像对中恢复单个图像的深度和相对姿态。由于单视深度估计是一个不适定问题,且光度损失无法识别扭曲图像的畸变伪影,估计的深度模糊,姿态不准确。与以往的方法相比,我们的框架学习了一种帧间相关性的紧凑表示,并通过合并序列信息来更新。更新后的表示用于深度估计。此外,我们将vo作为一个自监督的图像生成任务来处理,并利用生成性对抗网络(gan)。生成器学习估计深度和姿势以生成扭曲的目标图像。该鉴别器利用高层次的结构感知对生成的图像进行质量评价,克服了以往方法中像素丢失的问题。在kitti和cityscapes数据集上的实验表明,我们的方法在保留细节的情况下获得了更精确的深度,并且预测的姿态明显优于art自监督方法。
贡献
本文的主要贡献概括如下:
•我们建议利用长序列上的时空相关性来显著减少自监督vo的估计误差和尺度漂移。
•我们将自我监督的vo视为生成模型,利用对抗学习进行自我监督姿势和深度估计。
方法
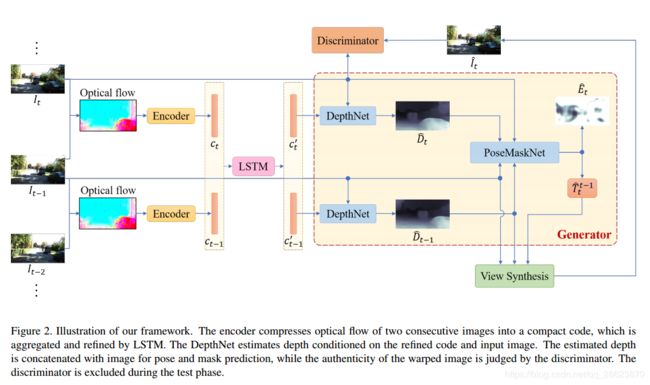
我们的方法不同于以往的技术,将自监督vo表示为一个序列学习问题,将帧间相关性表示为一个压缩码,并通过lstm集成序列信息。与目前流行的单视点深度估计方法不同,我们的框架是根据单个图像的编码来估计深度,并将vo作为一个生成任务来处理。通过对抗学习,我们的方法提供了更清晰的深度和更准确的姿态估计。
视觉里程计估计连续图像对之间的相机运动。在经典的vo/slam中,这种估计是通过特征对应或光度一致性来计算的。与以往直接从原始图像进行估计的自监督方法不同,我们为网络提供了一种用于深度和姿态估计的帧间对应表示。
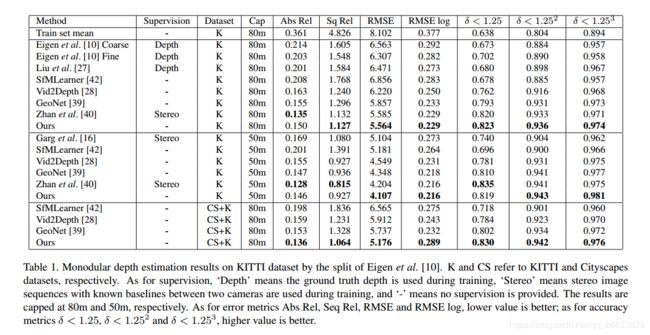
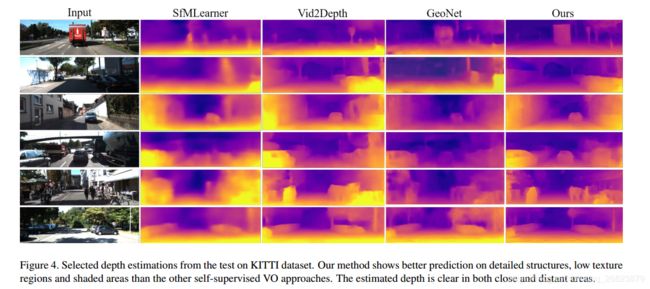
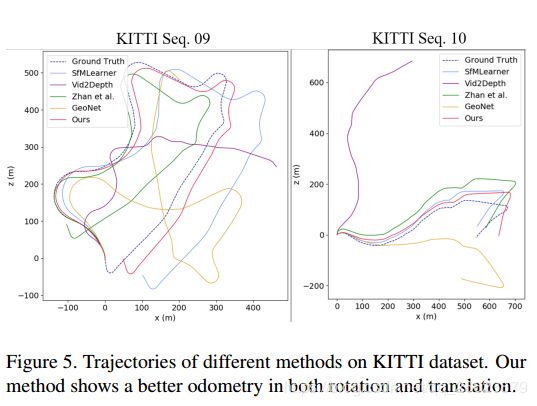
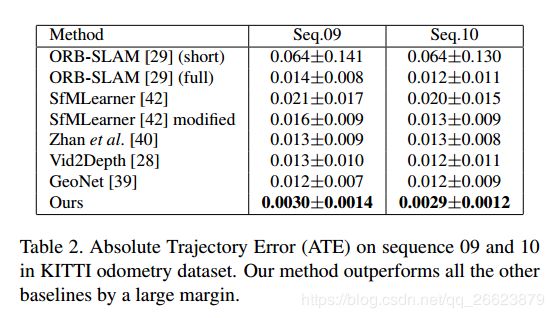
实验