MySQL 学习记录系列(四)
目录
1、应用优化
1.1、使用连接池
1.2、减少对MySQL的访问
1.3、负载均衡
2.Mysql中查询缓存优化
2.1、概述
2.2、操作流程
2.3、查询缓存配置
2.4、开启查询缓存
2.5、查询缓存SELECT选项
2.6、查询缓存失效的情况
3、ysql内存管理及优化
3.1、内存优化原则
3.2、MyISAM内存优化
3.3 、InnoDB内存优化
4、Mysql并发参数调整
4.1、max_connections
4.2、back log
4.3、table_open_cache
5、Mysql锁
5.1、锁
5.2、锁分类
5.3、Mysql锁
5.4、MyISAM表锁
5.5、lnnoDB行锁
6、常用SQL技巧
6.1、SQL执行顺序
6.2、正则表达式
6.3、MySQL 常用函数
1、应用优化
1.1、使用连接池
对于访问数据库来说,建立连接的代价是比较昂贵的,因为频繁的创建关闭连接,是比较耗费资源的,因此有必要建立数据库连接池,以提高访问的性能。
1.2、减少对MySQL的访问
1.2.1、避免对数据进行重复检索
在编写应用代码时,需要能够理清对数据库的访问逻辑。能够一次连接就获取到结果的,就不用两次连接,这样可以大大减少对数据库无用的重复请求。
比如,需要获取书籍的id和name字段,则查询如下:
select id,name from tb_book;
之后,在业务逻辑中有需要获取到书籍状态信息,则查询如下:
select id,status from tb_book;
1.2.2、增加cache层
可以在应用中增加缓存层来达到减轻数据库负担的目的。缓存层有很多种,也有很多实现方式,只要能达到降低数据库的负担又能满足应用需求就可以。
因此可以部分数据从数据库中抽取出来放到应用端以文本方式存储,或者使用框架(Mybatis,Hibernate)提供的一级缓存/二级缓存,或者使用redis数据库来缓存数据。
1.3、负载均衡
负载均衡是应用中使用非常普遍的一种优化方法,它的机制就是利用某种均衡算法,将固定的负载量分布到不同的服务器上,以此来降低单台服务器的负载,达到优化的效果。
1.3.1、利用MySQL复制分流查询
通过MySQL的主从复制,实现读写分离,使增删改操作走主节点,查询操作走从节点,从而可以降低单台服务器的读写压力。

1.3.2、采用分布式数据库架构
分布式数据库架构适合大数据量、负载高的情况,它有良好的拓展性和高可用性。通过在多台服务器之间分布数据,可以实现在多台服务器之间的负载均衡,提高访问效率。
2.Mysql中查询缓存优化
2.1、概述
开启Mysq的查询缓存,当执行完全相同的SQL语句的时候,服务器就会直接从缓存中读取结果,当数据被修改,之前的缓存会失效,修改比较频繁的表不适合做查询缓存。
2.2、操作流程
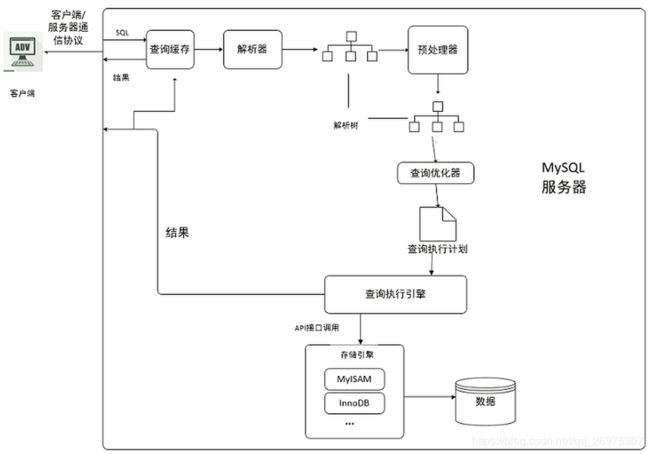
1.客户端发送一条查询给服务器;
2.服务器先会检查查询缓存,如果命中了缓存,则立即返回存储在缓存中的结果。否则进入下一阶段;
3.服务器端进行SQL解析、预处理,再由优化器生成对应的执行计划;
4.MySQL根据优化器生成的执行计划,调用存储引擎的API来执行查询;
5.将结果返回给客户端。
2.3、查询缓存配置
查看当前的MySQL数据库是否支持查询缓存:
SHOW VARIABLES LIKE 'have_query_cache';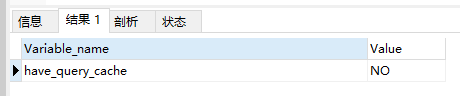
查看当前MySQL是否开启了查询缓存:
SHOW VARIABLES LIKE 'query_cache_type';
查看查询缓存的占用大小:(单位是字节)
SHOW VARIABLES LIKE'query_cache_size';查看查询缓存的状态变量:
SHOW STATUS LIKE 'Qcache%';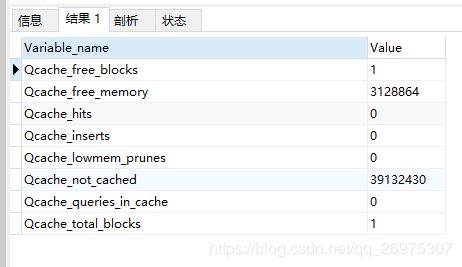

2.4/开启查询缓存
MvSOL的查询缓存默认是关闭的,需要手动配置参数 querv cache tvpe,来开启查询绣存。querv cache tvpe该参数的可取值有三个:

在/usr/my.cnf配置中,增加以下配置:
#开启mysq1的查询缓存
query_cache_type=1配置完毕之后,重启服务既可生效;然后就可以在命令行执行SQL语句进行验证,执行一条比较耗时的SQL语句,然后再多执行几次,查看后面几次的执行时间;获取通过查看查询缓存的缓存命中数,来判定是否走查询缓存。
2.5、查询缓存SELECT选项
可以在SELECT语句中指定两个与查询缓存相关的选项:
SQL_CACHE:如果查询结果是可缓存的,并且query_cache_type系统变量的值为ON或DEMAND,则缓存查询结果。
SQL_NO_CACHE:服务器不使用查询缓存。它既不检查查询缓存,也不检查结果是否已缓存,也不缓存查询结果。
SELECT SQL_CACHE id,name FROM customer;
SELECT SQL_NO_CACHE id,name FROM customer;2.6、查询缓存失效的情况
1)SQL语句不一致的情况,要想命中查询缓存,查询的SQL语句必须一致。
select count(*)from tb_item;
Select count(*)from tb_item;2)当查询语句中有一些不确定的时,则不会缓存。如:now(),current date(),curdate(),curtime(),rand(),uuid(),user(),database()。
select * from tb_item where updatetime < now()limit 1;
select user();
select database();3)不使用任何表查询语句。
select 'A';4)查询mysql,information_schema或performance_schema数据库中的表时,不会走查询缓存。
select * from information_schema.engines;5)在存储的函数,触发器或事件的主体内执行的查询,不会缓存。
6)如果表更改,则使用该表的所有高速缓存查询都将变为无效并从高速缓存中删除。这包括使用MERGE映射到已更改表的表的查询。一个表可以被许多类型的语句,如被改变INSERT,UPDATE,DELETE,TRUNCATE TABLE,ALTER TABLE,DROP TABLE,或DROP DATABASE
3、ysql内存管理及优化
3.1、内存优化原则
1)将尽量多的内存分配给MySQL做缓存,但要给操作系统和其他程序预留足够内存。
2)MyISAM存储引擎的数据文件读取依赖于操作系统自身的IO缓存,因此,如果有MyISAM表,就要预留更多的内存给操作系统做IO缓存。
3)排序区、连接区等缓存是分配给每个数据库会话(session)专用的,其默认值的设置要根据最大连接数合理分配,如果设置太大,不但浪费资源,而且在并发连接较高时会导致物理内存耗尽。
3.2、MyISAM内存优化
myisam存储引擎使用key_buffer 缓存索引块,加速myisam索引的读写速度。对于myisam表的数据块,mysql没有特别的缓存机制,完全依赖于操作系统的IO缓存。
key buffer size
key_buffer_size决定MyISAM索引块缓存区的大小,直接影响到MyISAM表的存取效率。
可以在MySQL参数文件中设置key_buffer_size的值,对于一般MyISAM数据库,建议至少将1/4可用内存分配给key_buffer_size。
在/usr/my.cnf中做如下配置:
key_buffer_size=512M
read_buffer_size
如果需要经常顺序扫描myisam表,可以通过增大read_buffer_size的值来改善性能。但需要注意的是read_buffer_size是每个session独占的,如果默认值设置太大,就会造成内存浪费。
read_rnd_buffer_size
对于需要做排序的myisam表的查询,如带有order by子句的sql,适当增加 read_rnd_buffer_size的值,可以改善此类的sql性能。但需要注意的是read_rnd_buffer_size是每个session独占的,如果默认值设置太大,就会造成内存浪费。
3.3 、InnoDB内存优化
innodb用一块内存区做I0缓存池,该缓存池不仅用来缓存innodb的索引块,而且也用来缓存innodb的数据块。
innodb_buffer_pool size
该变量决定了innodb存储引擎表数据和索引数据的最大缓存区大小。在保证操作系统及其他程序有足够内存可用的情况下,innodb_buffer_pool_size的值越大,缓存命中率越高,访问InnoDB表需要的磁盘I/O就越少,性能也就越高。
innodb_buffer-pool_size=512Minnodb log buffer_size
决定了innodb重做日志缓存的大小,对于可能产生大量更新记录的大事务,增加innodb_log_buffer_size的大小,可以避免innodb在事务提交前就执行不必要的日志写入磁盘操作。
innodb_1og_buffer_size=10M4、Mysql并发参数调整
MySQL Server 是多线程结构,包括后台线程和客户服务线程。多线程可以有效利用服务器资源,提高数据库的并发性能。
在Mysql中,控制并发连接和线程的主要参数包括max_connections、back log、thread_cache_size、table_open_cahce。
4.1、max_connections
采用max_connections 控制允许连接到MySQL数据库的最大数量,默认值是151。如果状态变量connection_errors_max_connections不为零,并且一直增长,则说明不断有连接请求因数据库连接数已达到允许最大值而失败,这是可以考虑增大max_connections的值。
Mysgl 最大可支持的连接数,取决于很多因素,包括给定操作系统平台的线程库的质量、内存大小、每个连接的负荷、CPU的处理速度,期望的响应时间等。在Linux平台下,性能好的服务器,支持500-1000个连接不是难事,需要根据服务器性能进行评估设定。
4.2、back log
back_log 参数控制MySQL监听TCP端口时设置的积压请求栈大小。如果MySql的连接数达到max_connections时,新来的请求将会被存在堆栈中,以等待某一连接释放资源,该堆栈的数量即back_log,如果等待连接的数量超过back_log,将不被授予连接资源,将会报错。
5.6.6版本之前默认值为50,之后的版本默认为50+(max_connections/5),但最大不超过900。
如果需要数据库在较短的时间内处理大量连接请求,可以考虑适当增大back_log的值。
4.3、table_open_cache
该参数用来控制所有SQL语句执行线程可打开表缓存的数量,而在执行SQL语句时,每一个SQL执行线程至少要打开1个表缓存
该参数的值应该根据设置的最大连接数max_connections以及每个连接执行关联查询中涉及的表的最大数量来设定:
max_connectionsx N;5、Mysql锁
5.1、锁
锁是计算机协调多个进程或线程并发访问某一资源的机制。
在数据库中,除传统的计算资源(如CPU、RAM、I/O等)的争用以外,数据也是一种供许多用户共享的资源。
如何保证数据并发访问的一致性、有效性是所有数据库必须解决的一个问题,锁冲突也是影响数据库并发访问性能的一个重要因素。
从这个角度来说,锁对数据库而言显得尤其重要,也更加复杂。
5.2、锁分类
从对数据操作的粒度分:
1)表锁:操作时,会锁定整个表。
2)行锁:操作时,会锁定当前操作行。
从对数据操作的类型分:
1)读锁(共享锁):针对同一份数据,多个读操作可以同时进行而不会互相影响。
2)写锁(排它锁):当前操作没有完成之前,它会阻断其他写锁和读锁。
5.3、Mysql锁
相对其他数据库而言,MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。
MySQL各存储引擎对锁的支持情况:

MySQL 3种锁的特性可大致归纳如下:

仅从锁的角度来说:表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;
而行级锁则更适合于有大量按索引条件并发更新少量不同数据,同时又有并查询的应用,如一些在线事务处理(OLTP)系统。
5.4、MyISAM表锁
MyISAM 存储引擎只支持表锁,这也是MySQL开始几个版本中唯一支持的锁类型。
5.4.1、如何加表锁
MyISAM 在执行查询语句(SELECT)前,会自动给涉及的所有表加读锁,在执行更新操作(UPDATE、DELETE、INSERT等)前,会自动给涉及的表加写锁,这个过程并不需要用户干预,因此,用户一般不需要直接用LOCK TABLE命令给MyISAM表显式加锁。
加读锁:lock table table_name read;
加写锁:lock table table_name write;5.4.2、读锁案例
CREATE TABLE tb_book(
id INT(11)auto_increment,
name VARCHAR(50)DEFAULT NULL,
publish_time DATE DEFAULT NULL,
status CHAR(1) DEFAULT NULL, PRIMARY KEY (id)
)ENGINE=myisam DEFAULT CHARSET=utf8;INSERT INTO tb_book(id,name,publish_time,status)VALUES(NULL,'java编程思想','2088-08-01','1');
INSERT INTO tb_book(id,name,publish_time,status)VALUES(NULL,'solr编程思想','2088-08-08','0');CREATE TABLE tb_user(
id INT(11)auto_increment,
name VARCHAR(50)DEFAULT NULL,
PRIMARY KEY (id)
)ENGINE=myisam DEFAULT CHARSET=utf8;INSERT INTO tb_user(id,name)VALUES(NULL,'令狐冲');
INSERT INTO tb_user(id,name)VALUES(NULL,'田伯光');5.4.4、结论
锁模式的相互兼容性如表中所示:

1)对MyISAM表的读操作,不会阻塞其他用户对同一表的读请求,但会阻塞对同一表的写请求;
2)对MISAM表的写操作,则会阻塞其他用户对同一表的读和写操作;简而言之,就是读锁会阻塞写,但是不会阻塞读。而写锁,则既会阻塞读,又会阻塞写。
可见,MyISAM的读写锁调度是写优先,这也是MyISAM不适合做以 写 为主的表的存储引擎的原因。因为写锁后,其他线程不能做任何操作,大量的更新会使查询很难得到锁,从而造成永远阻塞。
5.4.5、查看锁的争用情况
show open tables;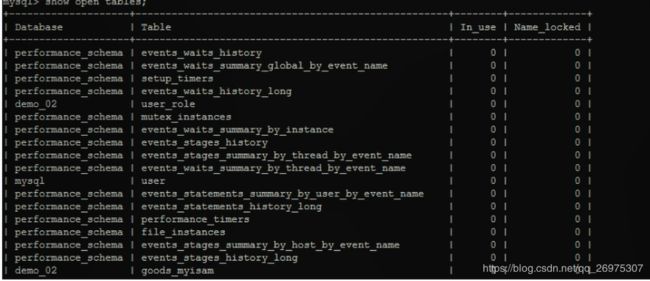
In_user:表当前被查询使用的次数。如果该数为零,则表是打开的,但是当前没有被使用。
Name_locked:表名称是否被锁定。名称锁定用于取消表或对表进行重命名等操作。
show status like'Table_locks%';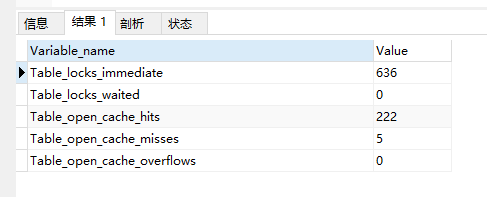
Table_locks_immediate
指的是能够立即获得表级锁的次数,每立即获取锁,值加1。
Table_locks_waited
指的是不能立即获取表级锁而需要等待的次数,等待一次,该值加1,此值高说明存在着较为严重的表级锁争用情况
5.5、lnnoDB行锁
5.5.1、行锁
行锁特点:偏向lnnoDB存储引擎,开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。
InnoDB与MyISAM的最大不同有两点:一是支持事务(原因就是采用了行级锁);二是采用了行级锁。
5.5.2 、事务及其ACID属性
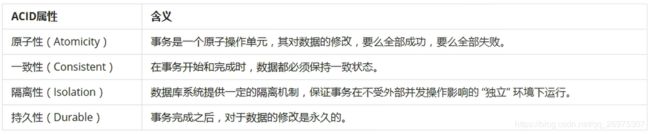
事务是由一组SQL语句组成的逻辑处理单元。
事务具有以下4个特性,简称为事务ACID属性。
并发事务处理带来的问题
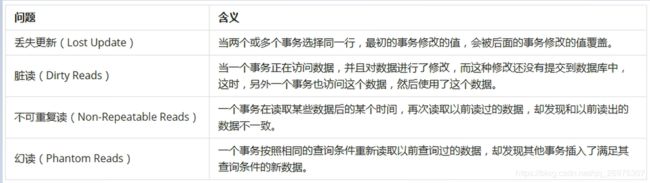
事务隔离级别
为了解决上述提到的事务并发问题,数据库提供一定的事务隔离机制来解决这个问题。
数据库的事务隔离越严格,并发副作用越小,但付出的代价也就越大,因为事务隔离实质上就是使用事务在一定程度上“串行化”进行,这显然与“并发”是矛盾的。
数据库的隔离级别有4个,由低到高依次为Read uncommitted、Read committed、Repeatable read、Serializable,这四个级别可以逐个解决脏写、脏读、不可重复读、幻读这几类问题。

备注:√ 代表可能出现,× 代表不会出现。
Mysgl的数据库的默认隔离级别为Repeatable read
show variables like 'tx_isolation';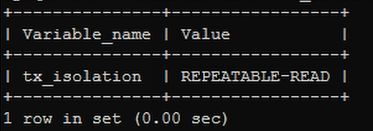
5.5.3、InnoDB的行锁模式
InnoDB实现了以下两种类型的行锁。
·共享锁(S)
又称为读锁,简称S锁,共享锁就是多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。·
排他锁(X)
又称为写锁,简称×锁,排他锁就是不能与其他锁并存,如一个事务获取了一个数据行的排他锁,其他事务就不能再获取该行的其他锁,包括共享锁和排他锁,但是获取排他锁的事务是可以对数据就行读取和修改。
可以通过以下语句显示给记录集加共享锁或排他锁。
共享锁(S):SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE排他锁(×):SELECT * FROM table_name WHERE ... FOR UPDATE对于UPDATE、DELETE和INSERT语句,InnoDB会自动给涉及数据集加排他锁(X);
对于普通SELECT语句,lnnoDB不会加任何锁;
举个栗子:
create table test_innodb_lock(
id int(11), name varchar(16), sex varchar(1)
)engine=innodb;insert into test_innodb_lock values(3,'3','1');
insert into test_innodb_lock values(4,'400','0');
insert into test_innodb_lock values(5,'500','1');
insert into test_innodb_lock values(6,'600','0');
insert into test_innodb_lock values(7,'700','0');
insert into test_innodb_lock values(8,'800','1');
insert into test_innodb_lock values(9,'900','1');
insert into test_innodb_lock values(1,'200','0');
create index idx_test_innodb_lock_id on test_innodb_lock(id);
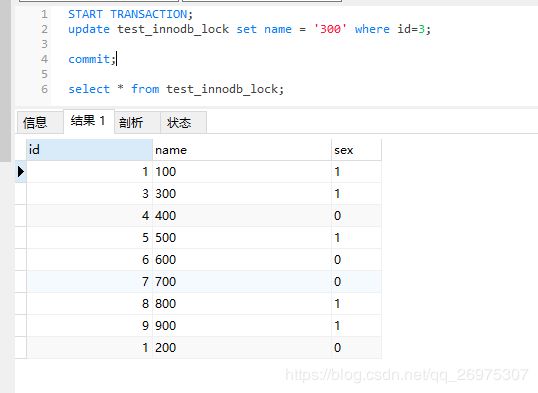
create index idx_test_innodb_lock_name on test_innodb_lock(name);5.5.5、行锁
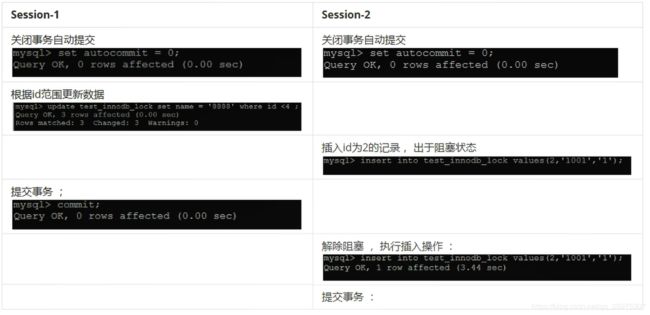
客户端1 客户端2

正常查询出所有的数据


更新并提交 查询到的是旧数据


5.5.6、无索引行锁升级为表锁
如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,实际效果跟表锁一样。
查看当前表的索引:
show index from test_innodb_lock;
关闭自动提交:set autocommit = 0;
客户端1 客户端2
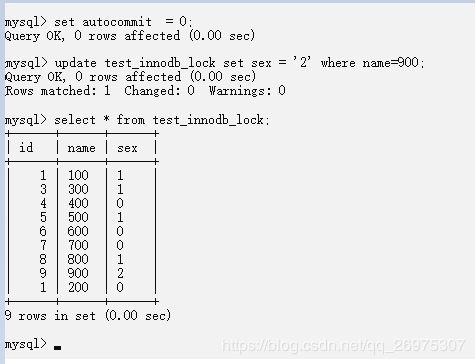

可见,客户端1 更新时,行锁失效,从而 升级为了表锁。
name 字段创建了索引,但原来的类型是varchar,没有加单引号,索引失效,从而导致行锁升级为表锁
5.5.7、间隙锁危害
当用范围条件,而不是使用相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据进行加锁;
对于键值在条范围内但并不存在的记录,叫做”间隙(GAP)",InnoDB也会对这个”间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
比如 id < 7 ,存在的为 1 2 5 6 ,此时3和4则成为 间隙
尽量缩小条件,比如要更新的是从 100,1000结束,那么条件可以为 100 < xxx < 1000
5.5.8、InnoDB行锁争用情况
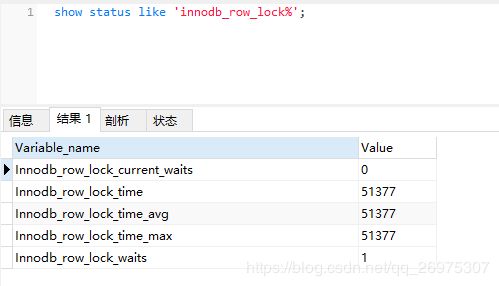
- Innodb_row_lock_current_waits:当前正在等待锁定的数量
- Innodb_row_lock_time:从系统启动到现在锁定总时间长度
- Innodb_row_lock_time_avg:每次等待所花平均时长
- Innodb_row_lock_time_max:从系统启动到现在等待最长的一次所花的时间
- Innodb_row_lock_waits:系统启动后到现在总共等待的次数
当等待的次数很高,而且每次等待的时长也不小的时候,需要分析系统中为什么会有如此多的等待,根据分析结果制定优化计划
5.5.9、总结
InnoDB存储引擎由于实现了行级锁定,虽然在锁定机制的实现方面带来了性能损耗可能比表锁会更高一些,但是在整体并发处理能力方面要远远优于MyISAM的表锁的。
当系统并发量较高的时候,InnoDB的整体性能和MyISAM相比就会有比较明显的优势。
但是,InnoDB的行级锁同样也有其脆弱的一面,当使用不当时,可能会让InnoDB的整体性能表现不仅不能比MyISAM高,甚至可能会更差。
- 尽可能让所有数据检索都能通过索引来完成,避免无索引行锁升级为表锁。
- 合理设计索引,尽量缩小锁的范围
- 尽可能减少索引条件,及索引范围,避免间隙锁
- 尽量控制事务大小,减少锁定资源量和时间长度
- 尽量使用低级别事务隔离(但是需要业务层面满足需求)
6、常用SQL技巧
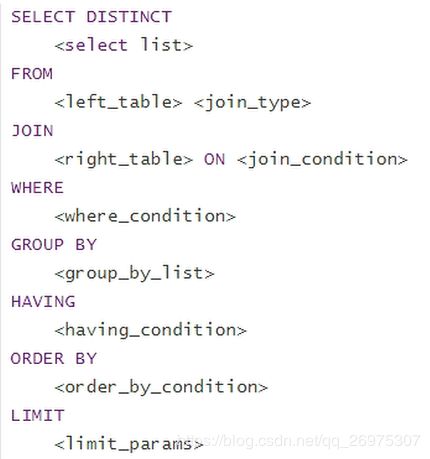
6.1、SQL执行顺序
编写顺序
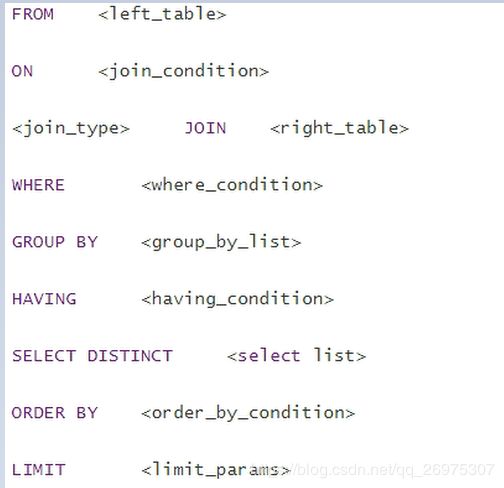
执行顺序
6.2、正则表达式
正则表达式(Regular Expression)是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。
查询 name 中以 j 开头的数据
select * from tb_book where name REGEXP '^j';查询 name 中以 j 结尾的数据
select * from tb_book where name REGEXP '$j';查询 name 中包含了 u / v / w 当中任意一个单词 的数据
select * from tb_book where name REGEXP '[uvw]';
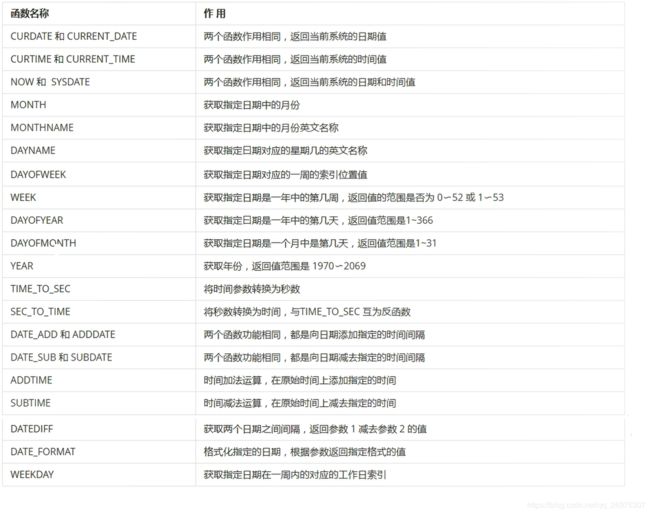
6.3、MySQL 常用函数
数学函数

字符串函数

聚合函数

日期函数