端到端语音识别系统发展及现状 | LAS、RNN-T、NT、MochA
文章目录
- 1.传统 ASR
- 2.端到端 ASR
- 3.端到端ASR的发展历程
- 3.1 CTC
- 3.2 基于CTC的端到端ASR
- 3.3 CTC的缺点
- 4.基于attentiion的encoder-decoder模型
- 5. Online 模型介绍(RNN-T, NT, MoChA)
- 5.1 模型配置
- 5.2 数据
- 5.3 结果
- 5.4 组合方式
- 5.5 进一步的提升
- 5.5.1 结构上的改进
- Wordpiece Model
- 多头attention
- 5.5.2 优化方式的改进
- 最小字错率(MWER)
- 预定采样
- 同步异步训练
- 标签平滑
- 5.5.3 外部语言模型
- 用LM扩展LAS
- 浅融合
- State-of-the-art
- 6.Online模型
- 7.1 RNN-T
- 7.1.1 进一步的提升
- 结构提升
- 流式模型的比较
- 7.1.2 实时识别
- 时间减少层
- 推理优化
- 参数量化
- 7.2. 神经传感器模型
- 7.2.1 训练数据
- 7.2.2 神经传感器的attention图像
- 7.3 Monotonic Chunkwise Attention
- 7.4.Online模型的对比
- 8.个性化
- CLAS(语境化的LAS模型)
- CLAS训练
- 偏置器
- 9. 端点检测
- 10. 多语言模型
1.传统 ASR
- 大多数ASR系统都涉及声学,发音和语言模型组件,这些组件需要分别训练
- 整理发音词典,为特定语言定义音素集需要专业知识,而且很耗时
2.端到端 ASR
- 一种将一系列输入声学特征直接映射到一系列字或单词的系统。
- 通过训练来优化我们感兴趣的最终评估指标的系统(通常是字错率)
3.端到端ASR的发展历程
3.1 CTC
-
CTC用于训练声学模型,无需在声学特征和转写结果之间进行帧级对齐。
-
编码器:多层单向或双向RNN(通常为LSTM)。
-
CTC引入了一个特殊符号-空白(用B表示),并通过边缘化所有可能的比对来最大化标签序列的总概率
-
在常规的混合系统中,这将对应于将与每个单元相对应的HMM定义为包含一个共享的初始状态(空白),然后是实际单元的一个或多个单独状态。

-
计算损耗的梯度需要使用向前-向后算法来计算alpha-beta变量
3.2 基于CTC的端到端ASR
- Graves和Jaitly提出了一种基于字符的CTC的系统,该系统可在给定输入语音的情况下直接输出单词序列
- 使用外部LM对于获得良好的性能很重要。 通过对基准系统进行评分来报告结果
- 还提升了最小化预期的转录错误[WSJ:8.7%→8.2%]
自[Graves&Jaitly,2014]以来的改进:
- LM纳入首轮解码; 与WFST轻松集成
- 大规模GPU培训; 数据扩充; 多种语言
- 使用更长的跨度单位:用单词代替字符
CTC产生“尖峰”和稀疏激活-有时即使没有LM也可以直接从激活中读取最终转录

3.3 CTC的缺点
- 为了提高效率,CTC做出了重要的独立性假设-不同帧的网络输出有条件地独立
- 要从CTC模型中获得良好的性能,就需要使用外部语言模型-直接贪婪的解码效果不佳
4.基于attentiion的encoder-decoder模型
- 基于注意力的编码器-解码器模型首先出现在神经机器翻译的上下文中。
- 2015年首次应用于ASR。
Encoder (analogous to AM): 将输入语音转换为更高级别的表示
attention(对齐模型): 识别产生与当前输出相关的编码帧
解码器(类似于PM,LM): 根据先前的预测来预测每个输出令牌
5. Online 模型介绍(RNN-T, NT, MoChA)
12,500小时Google任务上的模型比较
比较各种端到端方法
5.1 模型配置
●基准
○最先进的CD-Phoneme模型:5x700 BLSTM; 约8000个CD-音素
○CTC训练,然后是sMBR判别序列训练
○首次通过大5-gram LM解码
○第二阶段采用更大的5-gram LM计分
○数以百万计的专家策划的发音单词词典
●序列到序列模型
○训练输出字素:[a-z],[0-9],<空格>和标点符号
○使用集束搜索评估模型(每步保留前15个提示)
○不会使用外部语言模型或发音模型对模型进行解码或重新评分
5.2 数据
●训练集
○来自Google语音搜索流量的约1500万次(〜12,500小时)匿名话语
○多种风格的训练:使用房间模拟器通过添加从YouTube视频和日常活动的环境记录中提取的噪声样本来人为扭曲
●评估集
○听写:〜13K语音(〜124K字)开放式听写
○语音搜索:语音搜索查询的发音为〜12.9K(〜63K个单词)
5.3 结果

没有LM的CTC字形模型的解码效果不佳。

基于注意力的模型表现最佳,但不能用于流应用程序。
2017,Battenberg在Switchboard上报告了类似的结论。 没有LM的RNN-T始终比带有LM的CTC更好。
5.4 组合方式
可以成功组合各种端到端方法来改善整个系统
●可以将基于CTC和基于注意力的模型结合到多任务学习框架中[Kim等,2017]
●RNN-T可以通过注意模块进行扩充,该模块可以
○将语言模型组件置于声学条件上[Prabhavalkar等,2017]
要么,
○用于使解码器偏向感兴趣的特定项[He等,2017]
●注意力模型可以通过辅助注意力模块来增强,该模块可以偏向任意数量的关注短语[Pundak等,2018]
5.5 进一步的提升
●结构改进
○文字模型
○多头关注
●优化改进
○最低单词错误率(MWER)训练
○预定采样
○异步和同步训练
○标签平滑
●外部语言模型集成
5.5.1 结构上的改进
Wordpiece Model
●代替常用的字素,我们可以使用更长的单位,例如单词
●动机:
○通常,与字素级LM相比,字级LM的困惑度要低得多
○建模字词可实现更强大的解码器LM
○建模更长的单元可以改善解码器LSTM的有效存储
○允许模型潜在地记住频繁出现的单词的发音
○较长的单元需要较少的解码步骤; 这大大加快了这些模型的推论
●对于LAS和RNN-T具有良好的性能[Rao等,2017]。
●子词单位,范围从字素一直到整个词。
●没有带有单词片段模型的词汇外单词
●对单词模型进行训练,以在训练集中最大程度地提高语言模型的可能性
●词片是“位置相关的”,因为使用特殊的词分隔符标记来表示词的边界。
●使用贪婪算法将单词确定性地分割,并且与上下文无关。
多头attention
●[Vaswani et al。,2017]首次探索了多头注意力(MHA)用于机器翻译
●MHA将传统的注意力机制扩展为具有多个头部,每个头部可以产生不同的注意力分布。
5.5.2 优化方式的改进
最小字错率(MWER)
-
通常,通过优化交叉熵损失(即,最大化训练数据的对数似然性)来训练基于注意力的序列到序列模型
-
训练条件与关注的指标不匹配:字错误率
-
在常规ASR系统的背景下,用于神经网络声学模型
- 状态级最低贝叶斯风险(sMBR)[Kingsbury,2009年]
- 基于单词级编辑的最小贝叶斯风险(EMBR)[Shannon,2017年]
-
在端到端模型中
- 连接时序分类(CTC)[Graves and Jaitly,2014年]
- 递归神经对准剂(RNA)[Sak等,2017]:将词级EMBR应用于RNA
- 机器翻译:
- REINFORCE [Ranzato等,2016]
- 集束搜索优化[Wiseman和Rush,2016年]
- Actor-Critic算法[Bahdanau等,2017]
直接将预期WER最小化是很棘手的,因为它涉及所有可能标记序列的求和。 使用样本的近似预期。
- 使用样本的近似预期[Shannon,2017]。
- 使用N-Best 列表进行逼近[Stolcke et al,1997] [Povey,2003]
●自[Prabhavalkar等人,2018]开始,我们已经在MWR训练上对许多模型(包括RNN-T [Graves等人,2013]和其他基于流关注的模型,例如MoChA [Chiu和Raffel, 2017]和神经传感器[Jaitly等,2016]
●在所有情况下,我们都观察到相对WER降低8%至20%
●实施MWER需要具备从模型中解码出N个最佳假设的能力,这在计算上可能有些昂贵
预定采样
- 将地面真相标签作为先前的预测(所谓的teacher forcing)可帮助解码器在开始时快速学习,但会在训练和推理之间产生不匹配。
- 另一方面,排定的采样过程从上一个预测的概率分布(即从softmax输出)中采样,然后在预测下一个标签时使用结果令牌作为前一个令牌进行馈送
- 此过程有助于减小训练与推理行为之间的差距。 我们的训练过程在训练步骤的开始就使用了teacher forcing,随着训练的进行,我们在指定步骤将模型预测的抽样概率线性增加到0.4,然后保持不变,直到训练结束
同步异步训练
- 同步训练可以潜在地提供更快的收敛速度和更好的模型质量,但是还需要付出更多的努力才能稳定网络训练。
- 使用多个副本时,两种方法在训练开始时的梯度变化都很大
- 在异步训练中,我们使用副本加速:即,系统不会立即启动所有训练副本,而是逐步启动它们
- 在同步训练中,我们使用两种技术:学习率提升和梯度范数跟踪器
标签平滑
- 一种正则化机制,以防止模型做出过分自信的预测。
- 鼓励模型在其预测时具有较高的熵,从而使模型更具适应性
- 我们采用了与[Szegedy et al,2016]相同的设计,通过平滑标签的分布,并在所有标签上均匀分布。
5.5.3 外部语言模型
动机:某些语音搜索错误似乎可以通过在更多纯文本数据上训练的良好语言模型来解决。
- LAS模型需要音频文本对:我们只有1500万对
- 我们的生产LM受数十亿单词纯文本数据的训练
- 我们如何看待将更大的LM纳入我们的LAS模型?
- 更多详细信息,请参见[Kannan等,2018]
用LM扩展LAS
- Listen, Attend and Spell[Chan等,2015]
- 如何合并LM?
- 浅融合[Kannan等人,2018]•在输出上应用LM
- 深度融合[Gulcehre等,2015]•假设LM是固定的
- 冷聚变[Sriram等,2018]
- 深度LM和编码器之间的简单接口
- 允许特定任务上替换LM
- 在这些实验中,在波束搜索过程中使用融合,而不是n最佳记录。
浅融合
●语言模型和seq2seq模型之间的对数线性插值:
●通常仅在推断时间执行
●语言模型会提前训练并修复
●LM可以是n-gram(FST)或RNN。
●类似于第一遍记录。
State-of-the-art
LAS比常规模型具有更好的性能。
其他团体也有类似的报道。
6.Online模型
对嵌入式应用程序的关注点:
●可靠性●延迟●隐私
- LAS没有流式传输
- 我们将展示不同在线模型的全面比较
- RNN-T [Graves,2012],[Rao等,2017],[He等,2018]
- 神经传感器[Jaitly等,2015],[Sainath等,2018]
- MoChA
7.1 RNN-T
- 由Graves等人提出,RNN-T通过循环LM组件增强了基于CTC的模型
- 对两个组件进行共同训练以获取可用的声学数据
- 与CTC一样,该方法不需要对齐的训练数据。
RNN-T [Graves,2012]通过递归神经网络LM增强了CTC编码器
- 直观地,预测网络对应于“语言模型”组件,编码器对应于“声学模型”组件
- 可以通过单独训练的CTC-AM和RNN-LM(可以对纯文本数据进行训练 )来初始化这两个组件
- 初始化可以带来一些收益[Rao et al。,2017],但对于获得良好的性能并不关键
- 一般而言,在我们的实验中,RNN-T似乎总是比单独的CTC表现更好(即使使用单独的LM解码也是如此)
- 当我们比较语音搜索任务的各种方法时,将对此进行更多介绍。
RNN-T组件可以与(分层)CTC训练的AM和循环LM分别初始化。 初始化通常可以提高性能。
- 如果将字素用作输出单位,则该模型的语言建模上下文有限: 错误:“the tortoise and the hair”
- 使用单词作为输出目标可以允许建模其他上下文,但是会引入OOV
- 中间:使用“word pieces” [Schuster&Nakajima,2012年]
- 从文本数据迭代学习单位词汇表。
- 从单个字素开始,然后根据数据训练LM。
- 以贪婪的方式反复组合单位,以提高训练的难度
- 继续合并单元,直到达到预定的单元数或困惑度改进未达到阈值
- 例如“tortoise and the hare”→_tor to ise _and _the _hare
初始化“编码器”(即声学模型)有助于将性能提高约5%。
初始化“解码器”(即预测网络,语言模型)有助于将性能提高约5%。
具有〜96M参数的RNN-T模型可以匹敌基于CTC的大型首过LM模型
7.1.1 进一步的提升
结构提升
- 循环投影层[Sak等,2014]
- 在编码器和解码器的每个LSTM层之后引入。
- 通过更紧凑的表示来提高准确性。
- 层归一化[Ba等,2016]
- 应用于所有图层。
- 稳定循环层的隐藏状态动态。
- 提高准确性。
流式模型的比较
更多详细信息:[He et al,2018]
●输入:
○每10ms帧特征:80维log-Mel。
○每3帧被堆叠为网络的输入,因此有效帧速率为30ms。
●RNN-T:
○8层编码器,2048个单向LSTM单元+ 640个投影单元。
○2层预测网络,2048个单向LSTM单元+ 640个投影单元。
○模型输出单位:字素或字词。
○系统总大小:量化后约为120MB(有关详细信息,请参见下一张幻灯片)。
●用于嵌入式语音识别的竞争性CTC基准模型:
○与[McGraw et al,2016]相似,但模型更大。
○6层,1200个单向LSTM单元+ 400个投影单元。 sMBR序列训练。
○型号输出单位:CI手机。
○具有5-gram的首过LM和第二次通过的LSTM LM。
○系统总大小:量化后约为130MB。
通过所有优化,流式RNN-T模型与常规CTC嵌入式模型+ word LM相比,将WER提高了20%以上。
7.1.2 实时识别
时间减少层
- 时间减少层[Chan等,2015; Soltau等,2017]
•通过串联减少编码器中的序列长度。
•加快训练和推理速度。
•在两个编码器LSTM层之后插入,以最大程度地节省计算而不会影响精度。
•输入帧速率为30ms,输出帧速率为60ms:在RNN-T字素和字词模型中没有准确性损失,但会损害CTC音素模型。
推理优化
- 预测网络状态缓存
•预测网络的计算与声学无关。
•类似于RNN语言模型。
•应用在RNN LM中使用的相同状态缓存技术,以避免对相同预测历史记录进行冗余计算。
•实际上,在波束搜索期间会以不同的波束大小缓存50-60%的预测网络计算。 - 编码器/预测网络多线程
•编码器分为两个线程:减少时间层之前和之后。
•预测网络在单独的线程中运行。
•通过异步启用在不同线程之间的流水线操作。
•与单线程执行相比,可将速度提高28%。
参数量化
- 将参数从32位浮点精度量化为8位定点。
•将模型尺寸减小4倍。 - 对称量化
•假设参数值分布在浮点零附近以进行量化。
•直接使用量化矢量/矩阵进行无偏移乘法,这比具有偏移的非对称量化更有效。
•与浮点执行相比,速度提高了3倍。
RNN-T在Google Pixel手机上解码语音的速度是实时解码速度的两倍,与传统的CTC嵌入式模型相比,WER提升了20%以上。
7.2. 神经传感器模型
7.2.1 训练数据

- RNN-T,Policy Gradient等在线方法与模型一起学习对齐
- 我们以预先指定的对齐方式训练神经传感器,因此在训练过程中无需重新计算对齐方式(例如,前后移动),这会降低GPU / TPU的速度。

•信号表示块结束
•由于我们没有字素级别的对齐方式,因此我们一直等到单词结束时才发出整个单词的字素
7.2.2 神经传感器的attention图像
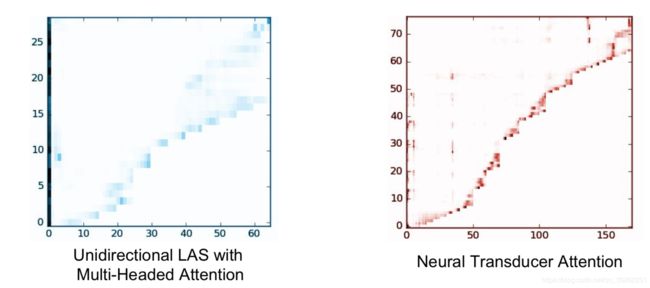
NT模型检查以前的帧而不会超出当前块
7.3 Monotonic Chunkwise Attention

•计算预期的注意力集中概率
•预期的概率分布引起了软注意
•与LAS相同的训练过程

7.4.Online模型的对比
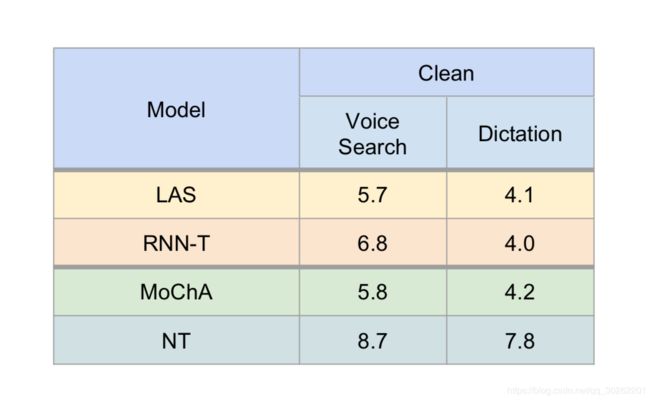
- 探索了在线端到端模型的多种选择。
与LAS相比,以较小的精度成本实现流识别。 - 深入研究RNN-T是一种有前途的选择。
与具有类似尺寸的常规CTC嵌入式模型相比,具有相当大的准确性和效率。
进一步的追求
- 个性化
- 快速终结点
- 多语言ASR
8.个性化
根据个人信息“偏向”语音模型的先验
举例:
• 联系人 - “call Joe Doe, send a message to Jason Dean”
• 唱歌 - “play Lady Gaga, play songs from Jason Mraz”
• 对话 - “yes, no, stop, cancel”
为什么这样做:相对而言,偏差可以将域的WER提高10%以上
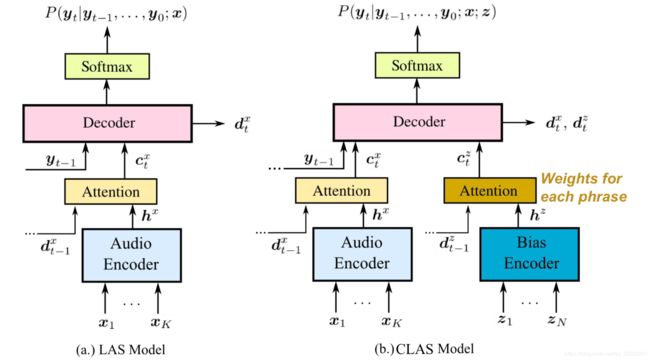
CLAS(语境化的LAS模型)
- 直接建模P(y | x,z)
- z:偏置相位,例如 联系人姓名/歌曲列表
- 目标:将模型偏向
输出特定短语 - 预测:模型必须
遵守正确的偏向
CLAS训练
- 参考示例: The grey chicken jumps over the lazy dog
- 统一采样偏向短语b, e.g. grey chicken
- 使用drop概率p(例如0.5)drop 所选短语
- 批次中其他参考增加了N-1个更多的偏向短语
• quick turtle
• grey chicken
• brave monkey - 如果没有drop(删除) b,请插入
标记以进行引用:
•The grey chickenjumps over the lazy dog
偏置器
- 偏置器将每个短语嵌入到固定长度的向量中
○→LSTM的最后状态 - 每个偏置词组嵌入一次(可能是离线)
○计算便宜 - 然后,根据嵌入集计算注意力
9. 端点检测
“确定用户何时结束发言:快速准确的ASR”