利用Beautifulsoup+Xpath爬取安居客官网全国600多城市二手房信息并存储mongodb
首先给我们爬虫做个知识点的简介:
网页解析库:Beautifulsoup、xpath
请求库:requests
数据存储:pymongo
分析目标网站:安居客官网

我们从以这些城市作为起始站点,获取每一个城市二手房的链接,从Chrome审查看一下:
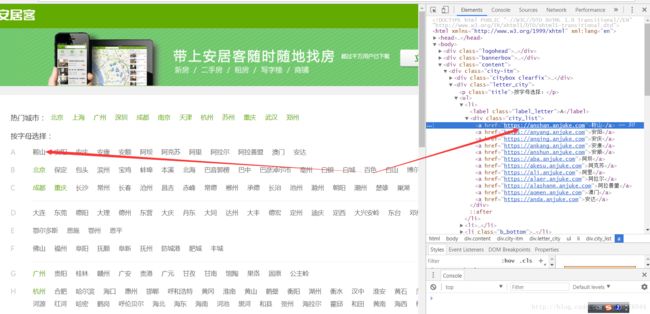
我们可以看到这些城市的‘href’元素是他们的下一级页面的url,总共有600多个城市,也就是我们可以找到600多个url。
但都是:https://anshan.anjuke.com这种形式,这样点进去并不是我们需要的相应城市的二手房界面的url。对比一下:
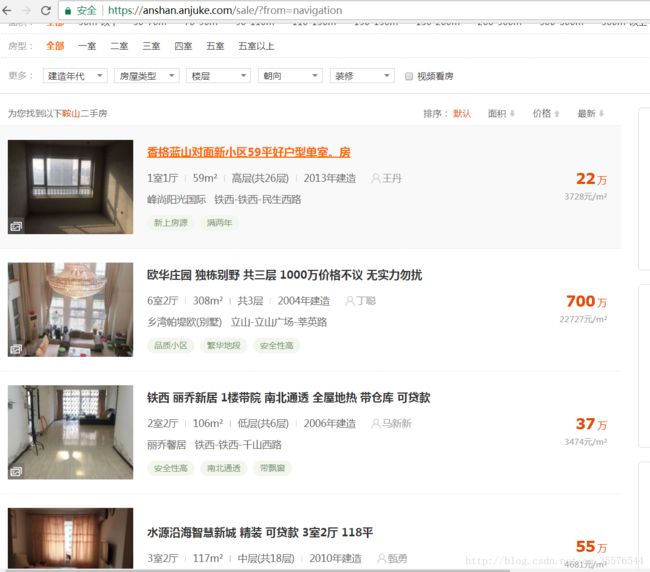
可以发现在原有的url后面多个‘/sale’,然后我们想要获得下一页,可以直接改变url后面的数值就行。
数据解析部分:
初始页面的城市的url我们用xpath,直接chrome审查copy xpath:
def first_url():#定义解析一百个城市的函数
link = 'https://www.anjuke.com/sy-city.html'
r = requests.get(link, headers=headers)
html = etree.HTML(r.text)
#解析一百个城市的链接地址
Urls = html.xpath('//*[@class="city-itm"]/div[2]/ul/li/div/a/@href')
#返回地址以供主函数调用
return Urls
#print(titles)可以看到打印出的是所有城市的url地址。
接下来我们写爬取这些城市二手房信息的主函数:
这里主要用的bs解析,因为xpath在这里解析比较麻烦,且xpath都比较长
例如这是第一个//*[@id=”houselist-mod-new”]/li[1]/div[2]/div[1]/a/text(),xpath提取出来会比较麻烦。
构建一个information字典,我们一共提取了10个字段。
def main():
#调用一百个城市函数地址的值
ism = first_url()
for Url in ism:
#print(title)
#以列表形式传入titl
for num in range(1, 50):#将titl进行翻页的操作,并补全url
i = num
url = Url + '/sale/p{}'.format(i)
#print(titl)
r = requests.get(url, headers=headers)
#time.sleep(5)
print('现在爬取的是第', i, '页')
soup = BeautifulSoup(r.text, 'lxml')
house_list = soup.find_all('li', class_="list-item")
if len(house_list) < 10:
continue
#return house_list
for house in house_list:
try:
information = {
"name": house.find('div', class_='house-title').a.text.strip(),
"price": house.find('span', class_='price-det').text.strip(),
"price_area": house.find('span', class_='unit-price').text.strip(),
"no_room": house.find('div', class_='details-item').span.text,
"area": house.find('div', class_='details-item').contents[3].text,
"floor": house.find('div', class_='details-item').contents[5].text,
"year": house.find('div', class_='details-item').contents[7].text,
"broker": house.find('span', class_='brokername').text[1:],
"address": house.find('span', class_='comm-address').text.strip(),
"tags": [i.text for i in house.find_all('span', class_='item-tags')]
}
print(information)
except:
continue
save_to_mongo(information)接下类似是关于数据的存储问题,这部分主要参考@崔大的视频教程,存储到mongodb。
MONGO_URL = 'localhost'
MONGO_DB = '安居客'
MONGO_TABLE = 'city1'
client = pymongo.MongoClient(MONGO_URL,connect=False)
db=client[MONGO_DB]这部分可以直接写在一个文件里,也可以放在另一个.py里,用from xx(另一个.py) inport *的方式导入。
相应的存储函数:
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到MONGODB成功', result)
else:print('插入失败')
except Exception:
print('存储到MONGODB失败', result)这里会在控制台打印出我们的存储内容。
最后补充一点:这里跟着崔大学习的主要是try: except这个抛出异常的方法。但是在数据存储的部分有一个问题,就是
print(information)
except:
continue
save_to_mongo(information)这里有的时候会因为页面没有字典里的某个键值,导致无法存储进去,因此整个程序也没有颁发运行,希望有大神知道哪里的原因可以指导下。
总的代码如下:
import time
from bs4 import BeautifulSoup
import requests
from lxml import etree
import pymongo
#from multiprocessing import Pool
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36'}
MONGO_URL = 'localhost'
MONGO_DB = '安居客'
MONGO_TABLE = 'city1'
client = pymongo.MongoClient(MONGO_URL,connect=False)
db=client[MONGO_DB]
def first_url():#定义解析一百个城市的函数
link = 'https://www.anjuke.com/sy-city.html'
r = requests.get(link, headers=headers)
html = etree.HTML(r.text)
#解析一百个城市的链接地址
Urls = html.xpath('//*[@class="city-itm"]/div[2]/ul/li/div/a/@href')
#返回地址以供主函数调用
return Urls
#print(titles)
def save_to_mongo(result):
try:
if db[MONGO_TABLE].insert(result):
print('存储到MONGODB成功', result)
else:print('插入失败')
except Exception:
print('存储到MONGODB失败', result)
def main():
#调用一百个城市函数地址的值
ism = first_url()
for Url in ism:
#print(title)
#以列表形式传入titl
for num in range(1, 50):#将titl进行翻页的操作,并补全url
i = num
url = Url + '/sale/p{}'.format(i)
#print(titl)
r = requests.get(url, headers=headers)
#time.sleep(5)
print('现在爬取的是第', i, '页')
soup = BeautifulSoup(r.text, 'lxml')
house_list = soup.find_all('li', class_="list-item")
if len(house_list) < 10:
continue
#return house_list
for house in house_list:
try:
information = {
"name": house.find('div', class_='house-title').a.text.strip(),
"price": house.find('span', class_='price-det').text.strip(),
"price_area": house.find('span', class_='unit-price').text.strip(),
"no_room": house.find('div', class_='details-item').span.text,
"area": house.find('div', class_='details-item').contents[3].text,
"floor": house.find('div', class_='details-item').contents[5].text,
"year": house.find('div', class_='details-item').contents[7].text,
"broker": house.find('span', class_='brokername').text[1:],
"address": house.find('span', class_='comm-address').text.strip(),
"tags": [i.text for i in house.find_all('span', class_='item-tags')]
}
print(information)
except:
continue
save_to_mongo(information)
# time.sleep(30)
# print(house_list)
if __name__ == '__main__':
main()