向你老婆解释清楚什么是MapReduce
文章转载自「开发者圆桌」一个关于开发者入门、进阶、踩坑的微信公众号

干巴巴的定义
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)",是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。它极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统上。
当前的软件实现是指定一个Map(映射)函数,用来把一组键值对映射成一组新的键值对,指定并发的Reduce(归约)函数,用来保证所有映射的键值对中的每一个共享相同的键组。
形象的解释1:统计图书
我们要数图书馆中的所有书。你数1号书架,我数2号书架,这就是“Map”。我们人越多,数的就更快。
现在我们到一起,把所有人的统计数加在一起,这就是“Reduce”。
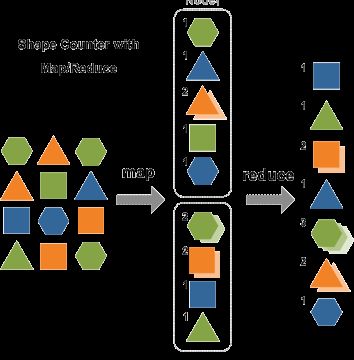
形象的解释2:统计图形
我们来看一个关于图形统计的MapReduce流程,两个人负责把左侧的一堆图形,按照形状和颜色归类统计各自的数量。
实战:计算平均成绩的Java Hadoop MapReduce程序
说了那么多,你老婆可能已经理解了MR,但是你可能还无法和程序代码联系起来,下面的这个小例子可以帮助到你,类似的样例网上很多,去搜索吧,这里简单分析一下关键代码,通过标注的name和Text key,你需要理解什么是MapReduce中的key以及key的作用。
数据环境:位于Hadoop中的chinese.txt、english.txt、math.txt文件分别记录了所有学生的语文、英语、数学成绩,文件内容格式为,姓名 分数,中间以空格分隔。
public class Score {
public static class ScoreMap extends
Mapper
// 实现map函数
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
// 将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n");
// 分别对每一行进行处理
while (tokenizerArticle.hasMoreElements()) {
// 每行按空格划分
StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
String strName = tokenizerLine.nextToken();// 学生姓名部分
String strScore = tokenizerLine.nextToken();// 成绩部分
Text name = new Text(strName);
int scoreInt = Integer.parseInt(strScore);
// 输出姓名和成绩,以name做为key对分数归类
context.write(name, new IntWritable(scoreInt));
}
}
}
public static class ScoreReduce extends
Reducer
// 实现reduce函数
public void reduce(Text key, Iterable
Context context) throws IOException, InterruptedException {
int sum = 0;
int count = 0;
Iterator
while (iterator.hasNext()) {
sum += iterator.next().get();// 计算总分
count++;// 统计总的科目数
}
int average = (int) sum / count;// 计算平均成绩
context.write(key, new IntWritable(average));
}
}
public static void main(String[] args) throws Exception {
...
// 设置Map和Reduce处理类
job.setMapperClass(ScoreMap.class);
job.setReducerClass(ScoreReduce.class);
...
}
}
最后的话
如果你要进一步了解MR,最好的方法就是从头成功运行一个hello world程序,通过一次成功的实践,你会发现MR这东西实在太简单了,否则说明你还没有成功运行过第一个小程序。实践!实践!实践!