Andrew Ng-机器学习基础笔记(上)-Python实现代码
目录
1.引言:
1.1Welcome:
1.2机器学习是什么?
1.3监督学习
1.4无监督学习:
总结:
2.线性回归
单变量的线性回归
2.1模型表示
2.2代价函数
2.3代价函数的直观理解:
2.4 代价函数的直观理解
2.5 梯度下降(Gradient descent)
2.6 梯度下降的直观理解
2.7梯度下降的线性回归
3、线性代数回顾
3.1 矩阵和向量
3.2 加法和标量陈发
3.3 矩阵向量乘法
3.4 矩阵乘法
3.5 矩阵乘法的性质
3.6 矩阵的逆、转置
4、多变量线性回归
4.1 多维特征
4.3 梯度下降法时间 1-特征放缩
实现代码:
4.4梯度下降法实践 2-学习率
4.5 特征多项式回归
4.6 正规方程
正规方程的实现代码:
拟合效果查看代码:
效果如图:
4.7 正规方程及不可逆性(选修-暂时不修)
小结与课后作业:
5 熟悉Python工具:
6 逻辑回归
6.1 分类算法
6.2 假说表示
逻辑模型:
实现代码:
6.3 判定边界
6.4 代价函数
实现代码:
6.5 简化的成本函数和梯度下降
6.6 高级优化
6.7 多类别分类:一对多
小结 & 课后练习:
7 正则化(Regularization)
7.1 过拟合的问题
7.2 代价函数:
7.3 正则化线性回归
7.4 正则化的逻辑回归模型
代价函数实现代码:
小结 & 练习:
8 神经网络:表述((Neural Networks: Representation)
8.2 神经元和大脑
8.3 模型表示
Notes:
8.4 模型表示
与逻辑回归的知识结合:
8.5 特征和直观理解
单程神经元的and、or
8.6 样本和直观理解 II
8.7 多类分类
后续:
1.引言:
1.1Welcome:
学习机器学习的主要问题和算法,了解不同算法的不同应用场景
1.2机器学习是什么?
Tom定义好的学习问题,一个程序被认为能从经验E中学习,解决任务T,达到性能度量值P,当且仅当,有了经验E后,经过P拼判,程序在处理T时的性能有所提醒。
学习算法分为:监督学习、无监督学习
1.3监督学习
监督学习指的是:我们给学习算法一个数据集。这个数据集由“正确答案”组成。
两个特别的例子,后面会进行细讲,先大致了解一下:
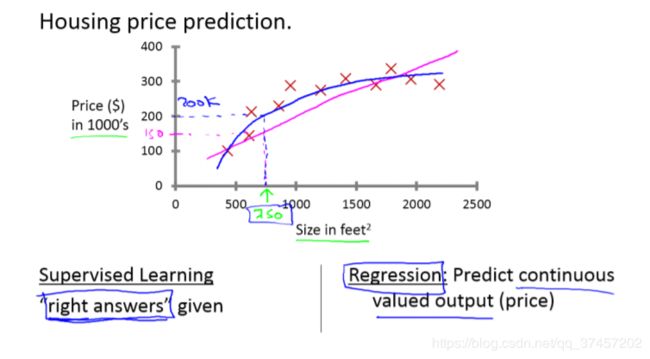 回归问题-房价预测
回归问题-房价预测
在房价的例子中,我们给了一系列房子的数据,我们给定数据集每个样本的正确价格,既它们实际的售价然后运用学习算法,算出新房子的价格,这叫回归问题,我们试着推测出连续的结果
 分类问题-良性恶性肿瘤分类
分类问题-良性恶性肿瘤分类
简单的来收,比如0或1代表良性或恶性肿瘤,通过分类算法估算出肿瘤良性或恶性的概率。
现实中,具有多种特征值,如果需要处理无限多个特征,解决存储问题,可以采用支持向量机(后面会补充),里面有一个巧妙的数学技巧,能,能让计算机处理无线多个特征
1.4无监督学习:
不同于监督学习,无监督学习没有任何的标签或者只有相同的标签。如图: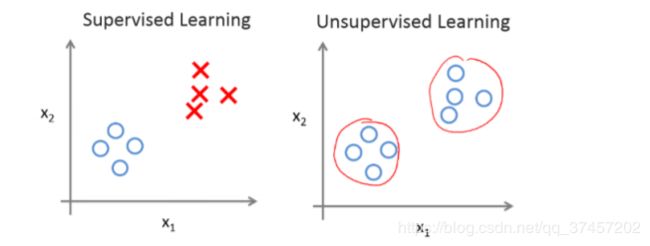
无监督学习算法可能会把这些数据分成两个不同的族。所以叫做聚类算法。
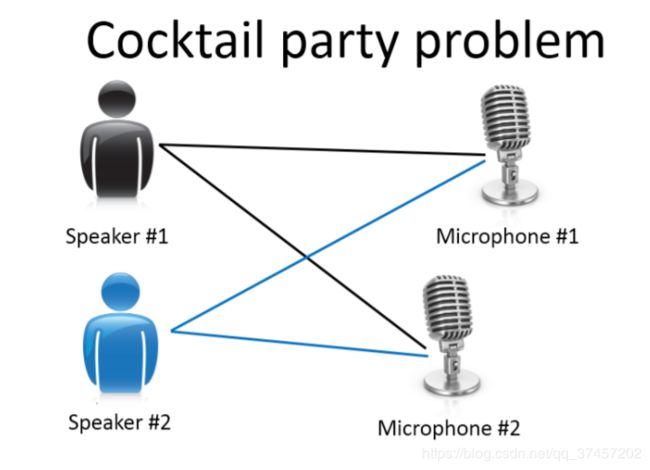
典型例子:鸡尾酒算法
总结:
垃圾邮件问题---监督学习问题、
新闻事件分类问题---无监督学习
细分市场---无监督学习
糖尿病---监督学习
2.线性回归
单变量的线性回归
2.1模型表示
在监督学习中,我们有一个数据集,这个数据集被称训练集
监督学习例子(后面的课后练习也是以房价这个为例子的)
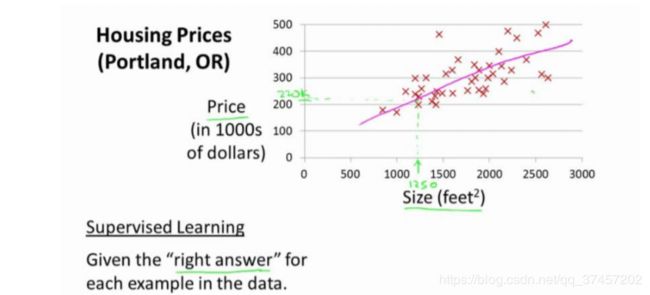
回归问题的标记

这就是监督学习算法的工作方式

h如何表达,可以如下表达(一元线性函数):![]()
因为只有 一个特征/输入变量,因此这样的问题叫做单变量线性回归问题
2.2代价函数
建模误差: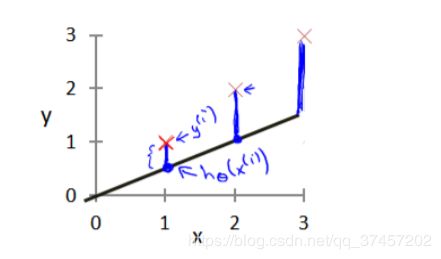
目标是选择可以使得建模误差的平分和能够最小的模型参数
代价函数:
注意:这里的1/2是为了后面求导的方便,放大和缩小并不影响结果
2.3代价函数的直观理解:

Notes:下图采用了简化版,当第一个参数为0的时候(过原点的直线)
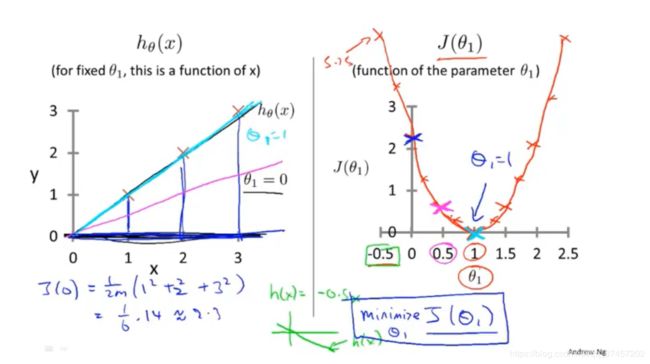
2.4 代价函数的直观理解
当我们考虑到两个参数变量的时候 ,显然图像就不容易画了,这时候我们采用等高线图来画,可是等高线图也麻烦,找最最小也麻烦,如图:

于是后面,我将介绍能够自动找出使得代价函数J最小化的参数的值(迭代或者直接计算)
2.5 梯度下降(Gradient descent)
梯度下降是一个用来求函数最小值的算法,我们将使用梯度将下降算法来求出代价函数的最小值
批量梯度下降:

Notes:
每一次都同时让所有的参数减去学习率乘以代价函数的导数
a是学习率,决定了我们沿着能让代价函数下降程度最大的方向向下卖出的步子有多大
同时更新(Simultaneous update)是梯度下降的常用方法
Python实现代码:
def gradientDescent(X, y, theta, alpha, iters):
temp = np.matrix(np.zeros(theta.shape))
parameters = int(theta.ravel().shape[1])
cost = np.zeros(iters)
for i in range(iters):
error = (X * theta.T) - y
for j in range(parameters):
term = np.multiply(error, X[:,j])
temp[0,j] = theta[0,j] - ((alpha / len(X)) * np.sum(term))
theta = temp
cost[i] = computeCost(X, y, theta)
return theta, cost2.6 梯度下降的直观理解
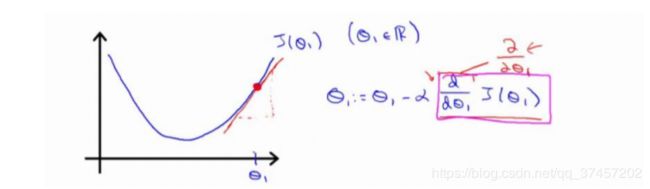
求导的目的是为了取这个红点的切线,这条直线的斜率正好是这个三角形的高度除以这个水平长度,现在有一个正斜率,我们得到新的参数1减去一个正数乘学习率

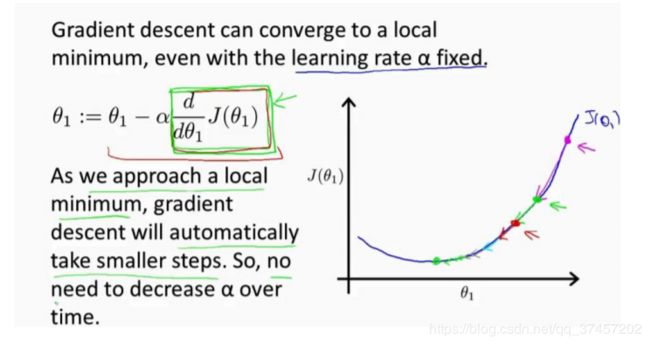
回顾一下,在梯度下降法中,当我们接近局部最低点时,梯度下降法会自动采取更小的幅度,这是因为当我们接近局部最低点时,很显然在局部最低时导数等于零,所以当我们接 近局部最低时,导数值会自动变得越来越小,所以梯度下降将自动采取较小的幅度,这就是 梯度下降的做法。所以实际上没有必要再另外减小 a 。
2.7梯度下降的线性回归
梯度下降算法和线性回归算法比较图

批量梯度算法指的是:在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个想需要对所有m个训练样本求和。
3、线性代数回顾
3.1 矩阵和向量
3.2 加法和标量陈发
3.3 矩阵向量乘法
3.4 矩阵乘法
3.5 矩阵乘法的性质
3.6 矩阵的逆、转置
非常基本就不一一回顾了,都是数学二线性代数的内容
4、多变量线性回归
4.1 多维特征
支持多变量的假设:
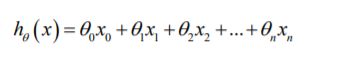
引入x0=1(这在后面的例子都是这样定义的),此时模型中的参数是一个n+1纬的向量,任何一个训练实例也都是n+1纬的向量,矩阵X的纬度是m*(n+1).
因此公示可以简化为:![]() 其中上标T代表矩阵转置
其中上标T代表矩阵转置
4.2 多变量梯度下降
代价函数是所有建模误差的平方和:
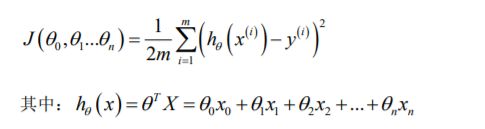
计算此代价函数的python代码
def computeCost(X, y, theta):
inner = np.power(((X * theta.T) - y), 2)
return np.sum(inner) / (2 * len(X))# 初始化一些附加变量 - 学习速率α和要执行的迭代次数。
alpha = 0.01
iters = 10004.3 梯度下降法时间 1-特征放缩
效果如图
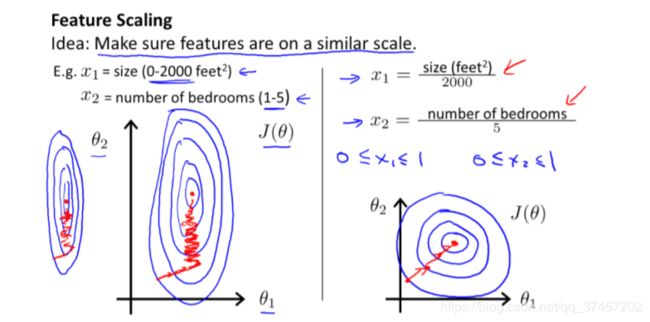
公式如下

比如课后作业多变量部分加了一个卧室的变量:
实现代码:
data2 = (data2 - data2.mean()) / data2.std()
data2.head()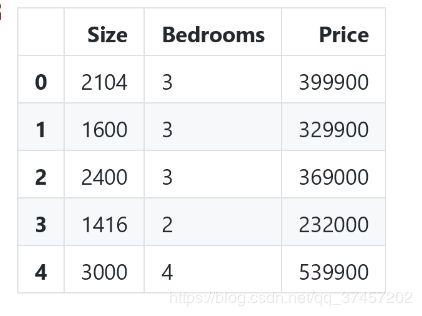 数据特征归一化之前
数据特征归一化之前
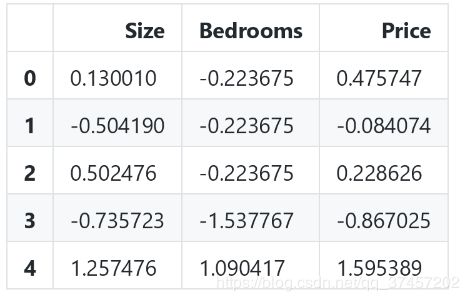 数据特征归一化之后
数据特征归一化之后
4.4梯度下降法实践 2-学习率

通常可以考虑尝试些学习率: α=0.01,0.03,0.1,0.3,1,3,10
4.5 特征多项式回归
线性回归并不适用于所有数据,此时我们需要曲线来适应我的数据

比如二次方或者三次方,但是需要注意的是,如果使用二次方,由于二次方会下降所以并不利于我们测试,所以用三次方会好点
根据图形的性质,因此还可以使:
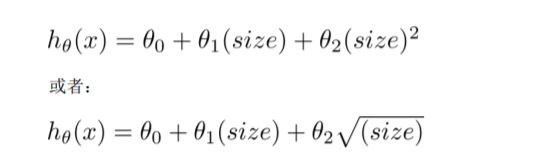
我们可以注意到。当我们采用此种方法的时候,在运行梯度下降算法前,特征缩放是非常有必要的
4.6 正规方程
正规方程是通过求解下面的方程来找出使得代价函数最小的参数的:代价函数的偏导数为0。 假设我们的训练集特征矩阵为 X(包含了x0=1)并且我们的训练集结果为向量 y,则利用正规方程解出向量 θ(如下图公式) 。 上标T代表矩阵转置,上标-1 代表矩阵的逆。
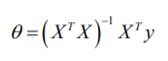
梯度下降与正规方程的比较:

总的来说,只要特征变量的数目并不大,正规方程是一个很好的计算参数的替代方法。具体地说,只要特征变量数量小于1w,通常使用正规方程法,而不是用梯度下降法
正规方程的实现代码:
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y#X.T@X等价于X.T.dot(X)
return theta拟合效果查看代码:
#现在我们来绘制线性模型以及数据,直观地看出它的拟合。
x = np.linspace(data.Population.min(), data.Population.max(), 100)
f = g[0, 0] + (g[0, 1] * x)
fig, ax = plt.subplots(figsize=(12,8))
ax.plot(x, f, 'r', label='Prediction')
ax.scatter(data.Population, data.Profit, label='Traning Data')
ax.legend(loc=2)
ax.set_xlabel('Population')
ax.set_ylabel('Profit')
ax.set_title('Predicted Profit vs. Population Size')
plt.show()
效果如图:


图片数据均来自课后作业,左图是梯度下降算法的,右图是正规方程的拟合过程
4.7 正规方程及不可逆性(选修-暂时不修)
小结与课后作业:
回归方程的知识过了两遍,接下来完成课后练习(光说不练,耍流氓)
完成练习后的笔记
https://blog.csdn.net/qq_37457202/article/details/106853058
5 熟悉Python工具:
Python 基础学习特别推荐 黄广海老师的资料,
https://github.com/fengdu78/Data-Science-Notes
然后自己在黄博士的基础上整理了自己的学习笔记
AI 基础:Python 简易入门(附上链接)
AI 基础:Numpy 简易入门(附上链接)
AI 基础:Pandas 简易入门(2天)(已完成)
AI基础:数据可视化简易入门(matplotlib和seaborn)(已完成)
额外:数据获取---学习了一下爬虫。可以查看
https://blog.csdn.net/qq_37457202/article/details/106537627
6 逻辑回归
6.1 分类算法
你要预测的变量 y 是离散的值,我们将学习一种叫做逻辑回归 (Logistic Regression) 的算法,这是目前最流行使用最广泛的一种学习算法
我们将因变量(dependant variable)可能属于的两个类分别称为负向类(negative class)和 正向类(positive class),则因变量 y={10,},其中 0 表示负向类,1 表示正向类。
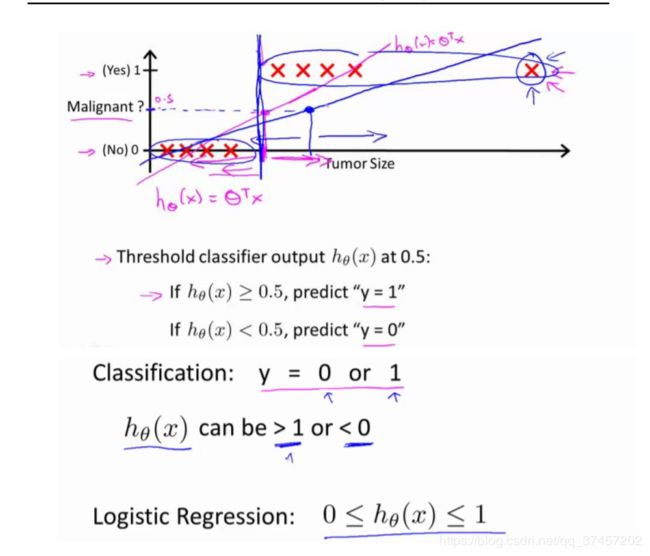
逻辑回归算法实际上是一种分类算法,它适用于标签y取值离散的情况
6.2 假说表示
线性回归的方法求出适合数据的一条直线:
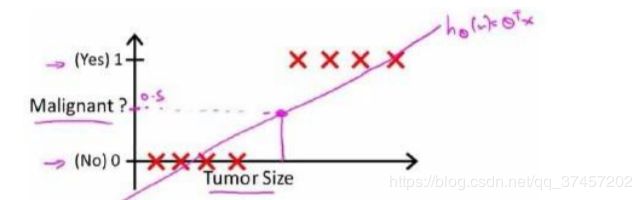
可是,当我们预测到一个非常大的恶性肿瘤的时候,将他加入我们的训练集中,将得到新的直线
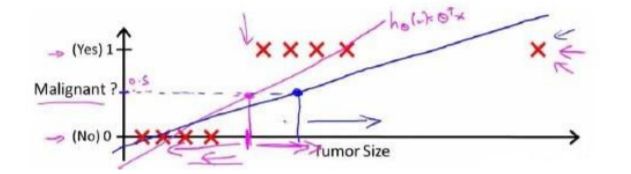
因为预测的数值超过了[0,1]且我们显然可以看见预测的数据不够准确,因此我们需要引入新的模型
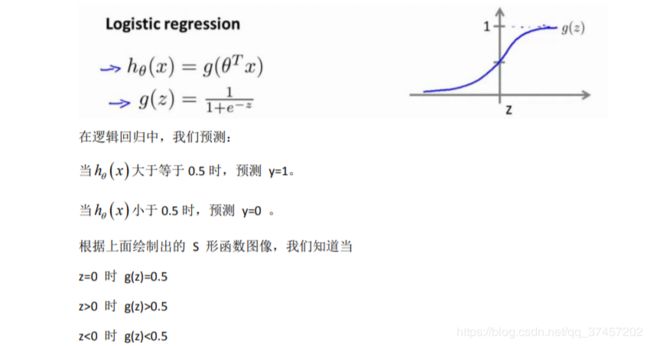
逻辑模型:


函数的图像:

实现代码:
import numpy as np
def sigmoid(z):
return 1 / (1 + np.exp(-z))h(x)的作用:对于给定的输入变量,根据选择的参数计算输出变量=1的可能性
6.3 判定边界
现在我们假设一个模型:
我们将参数设置为(后面会介绍如何拟合,先略过)[-3,1,1]

当z>=0的时候,g(z)>=0.5,也就是,h(x)>=0.5 预测y=1,因此x1+x2>=3是模型的分界线:

针对一些复杂的情况,如: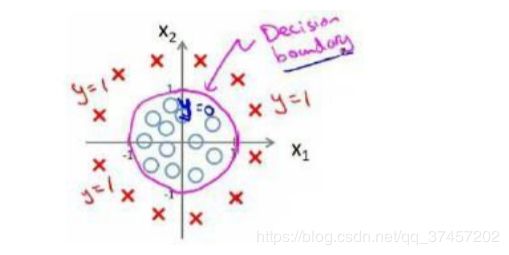
方法与线性多项式一样,我们需要用到二次方特征:
6.4 代价函数
对于线性模型,我们代价函数是所有模型的误差的平方和。可是如果直接套用会得到一份非凸函数,这超出了这么课程的学习,因此我们需要做凸优化问题。
我们的代价函数:
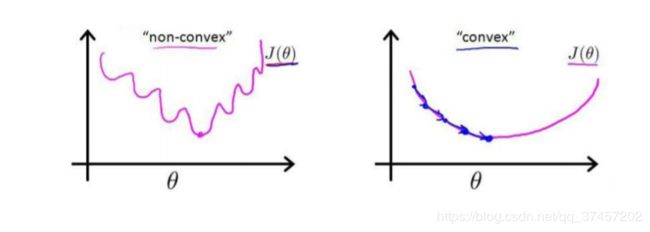

h(x)与Cost(h(x),y)之间的关系如图:
当实际的 y=1 且 h (x) 也为 1 时误差为 0,当 y=1 但 h (x) 不为 1 时误差随着 h(x)的变小而变大

实现代码:
Import numpy as np
def cost(theta, X, y):
#逻辑回归(Logistic Regression)
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
return np.sum(first - second) / (len(X))在得到这样一个代价函数以后,我们便可以用梯度下降算法来求得能是代价函数最小的参数:

推导过程:(略)
虽然得到的梯度下降算法表面上看上去与线性回归的梯度下降算法一样,但是这里 h (x)= g( 向量的转置换*X) 与线性回归中不同,所以实际上是不一样的。
6.5 简化的成本函数和梯度下降
逻辑回归代价函数: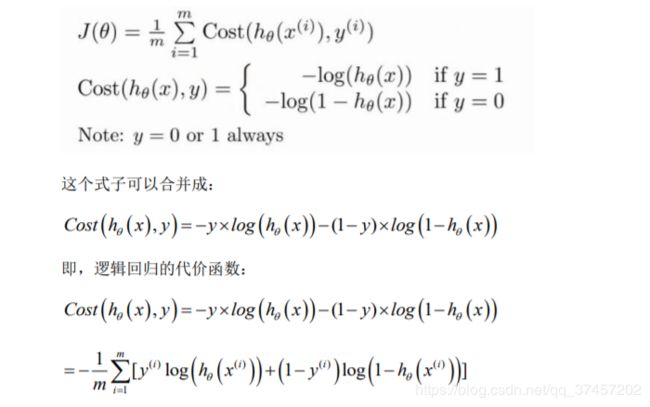

注意与线性回归相区别,虽然梯度下降看上去一样,但是假设函数是不一样的:

如果特征量范围很大,那么应用特征缩放的方法,同样也可以让逻辑回归中,梯度下降收敛更快
6.6 高级优化
一些高级优化算法和一些高级的优化概念,利用这些方法,我们就 能够使通过梯度下降,进行逻辑回归的速度大大提高,而这也将使算法更加适合解决大型的 机器学习问题,比如,我们有数目庞大的特征量。会用就可以了,这部分如果后面有实验,在看看Python的代码是如何实现的。
这些算法有 共轭梯度法BFGS(变尺度法)和L-BFGS(限制变尺度法)
这种算法有需要许多有点:
1、无需手动选择学习率,有一个智能内部循环,线性搜索的算法去自动尝试不同的学习率
2、他们最终的收敛熟读远远快于梯度下降
缺点:
实现起来过于复杂
目标:
会使用这些高级的优化算法,找到相应的可以,能将逻辑回归和线性回归应用于最大的问题中,这就是高级优化的概念
6.7 多类别分类:一对多
我们之前处理的二元类问题: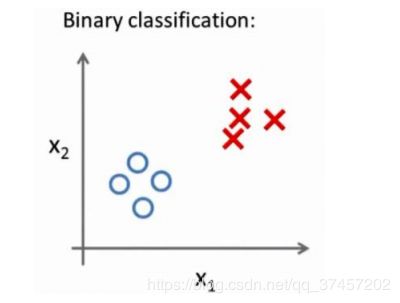
如今的多类分类问题: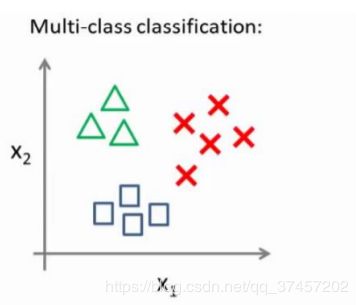
我们可以通过拟合一个合适的分类器来完成

这里的三角形是正样本,而圆形代表负样本。可以这样想,设置三角形的值为 1,圆形 的值为 0,下面我们来训练一个标准的逻辑回归分类器,这样我们就得到一个正边界。

现在要做的就是训练这个逻辑回归分类器:![]() 其中 i 对应每一个可能的 y=i,最后,为了做出预测,我们给出输入一个新的 x 值,用这 个做预测,选择出哪一个分类器是可信度最高效果最好的(max
其中 i 对应每一个可能的 y=i,最后,为了做出预测,我们给出输入一个新的 x 值,用这 个做预测,选择出哪一个分类器是可信度最高效果最好的(max ![]() ), 那么就可认为得到一个正确的分类
), 那么就可认为得到一个正确的分类
小结 & 课后练习:
逻辑回归练习题:
https://blog.csdn.net/qq_37457202/article/details/106860442
7 正则化(Regularization)
7.1 过拟合的问题
前面讲到的学习算法,但出现过拟合问题的时候,会导致他们的效果变得很差
比如回归问题:
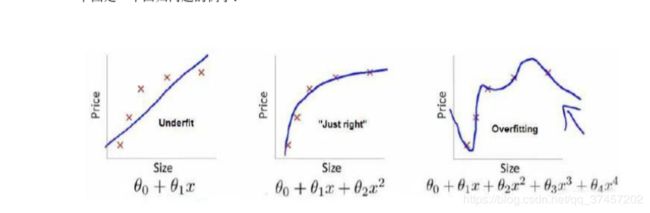 左图 欠拟合 中间图 理想 右图 过拟合
左图 欠拟合 中间图 理想 右图 过拟合
过拟合,虽然非常好地适应我们的训练集单在新输入变量进行预测时效果不好。
分类问题: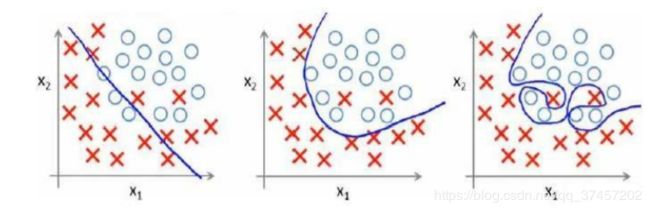
同理,x的次数越高,拟合的越好,但相应的预测能力变差
正则化(regularization)技术,可以该上或者减少过拟合的问题
处理过拟合的方法有:
1. 丢弃一些不能帮助我们正确预测的特征。可以是手工选择保留哪些特征,或者使用 一些模型选择的算法来帮忙(例如 PCA) 2. 正则化。 保留所有的特征,但是减少参数的大小(magnitude)。
7.2 代价函数:
在回归问题,如果我们的模型是:![]()
高次项导致过拟合的产生,我们可以添加惩罚(将尾部参数),修改后的代价函数: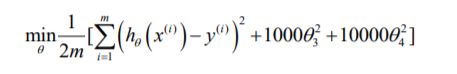
扩展到,实际情况上 有非常多的特征,我们不知道其中哪些需要这样做,我们对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度:
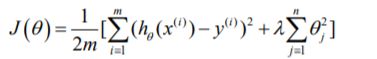
其中  又称为正则化参数(Regularization Parameter)。 注:根据惯例,我们不对 0 进 行惩罚。经过正则化处理的模型与原模型的可能对比如下图所示:
又称为正则化参数(Regularization Parameter)。 注:根据惯例,我们不对 0 进 行惩罚。经过正则化处理的模型与原模型的可能对比如下图所示:

那为什么这一项,可以参数减少:
因为如果我们令λ的值很大的话,为了使 Cost Function 尽可能的小,所有的  (不包括 0 )都会在一定程度上减小。
(不包括 0 )都会在一定程度上减小。
但若λ的值太大了,那么 (不包括 0 )都会趋近于 0,这样我们所得到的只能是一条 平行于 x 轴的直线。
所以对于正则化,我们要取一个合理的λ的值,这样才能更好的应用正则化。
回顾一下代价函数,为了使用正则化,让我们把这些概念应用到到线性回归和逻辑回归 中去,那么我们就可以让他们避免过度拟合了。
7.3 正则化线性回归
正则化线性回归的代价函数:
如果采用的是梯度算法,令这个代价函数最小:

每次都在原有算法更新规则的 基础上令 值减少了一个额外的值。 我们同样也可以利用正规方程来求解正则化线性回归模型,方法如下所示:
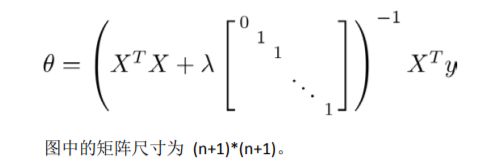
7.4 正则化的逻辑回归模型
在高级优化算法中,需要自己设计代价函数:

增加一个正则化的表达式:

代价函数实现代码:
Import numpy as np
def costReg(theta, X, y, learningRate):
theta = np.matrix(theta)
X = np.matrix(X)
y = np.matrix(y)
first = np.multiply(-y, np.log(sigmoid(X * theta.T)))
second = np.multiply((1 - y), np.log(1 - sigmoid(X * theta.T)))
reg = (learningRate / 2 * len(X)) *
np.sum(np.power(theta[:,1:theta.shape[1]], 2))
return np.sum(first - second) / (len(X)) + reg要最小化该代价函数,通过求导,得出梯度下降苏阿帆:

注意:
1.虽然正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但 由于两者的 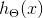 不同所以还是有很大差别。
不同所以还是有很大差别。
2. 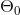 不参与其中的任何一个正则化。
不参与其中的任何一个正则化。
小结 & 练习:
结合逻辑回归使用正则化,代码实现见:
https://blog.csdn.net/qq_37457202/article/details/106860442
8 神经网络:表述((Neural Networks: Representation)
8.1 非线性假设

针对生活中图像处理的特征过多的情况,普通的逻辑回归模型,不能有效地处理这么多的特征,这时候我 们需要神经网络。
8.2 神经元和大脑
通俗的来收,就是模拟大脑的神经元,国外这项技术比价成熟。
8.3 模型表示
一个处理单元/神经核(processing unit/ Nucleus),它含有许多输入/树突 (input/Dendrite),并且有一个输出/轴突(output/Axon)。

在神经网络中,参数又可 被成为权重(weight)
我们设计出了类似于神经元的神经网络,效果如下

下图为一个 3 层的神经网络,第一层成为输入层(Input Layer),最后一 层称为输出层(Output Layer),中间一层成为隐藏层(Hidden Layers)。我们为每一层都增 加一个偏差单位(bias unit):
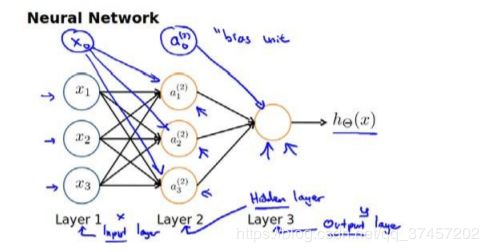

对于上图所示的模型,激活单元和输出分别表达为:

Notes:
注意上、下标、注意上、下标、注意上、下标
(我们把这样从左到右的算法称为前向传播算法( FORWARD PROPAGATION ))

8.4 模型表示
这部分理解得有点卡壳,符号的问题,就直接上图了
 图片文字整理来源于-黄海广博士的笔记
图片文字整理来源于-黄海广博士的笔记
与逻辑回归的知识结合:
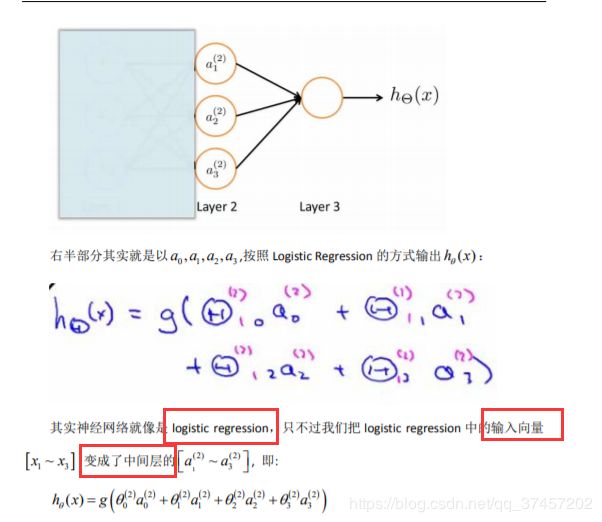

这些更高级的特征值远比仅仅将 x 次方厉害,也能更好的预测新数据
这就是神经网络相比于逻辑回归和线性回归的优势。
8.5 特征和直观理解
单程神经元的and、or
and:
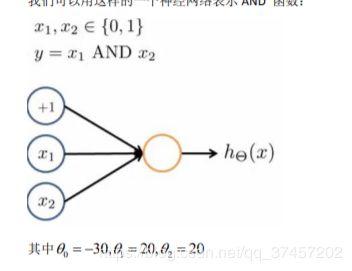
g(x)的图像入图则有:
or:
OR 与 AND 整体一样,区别只在于的取值不同。
8.6 样本和直观理解 II
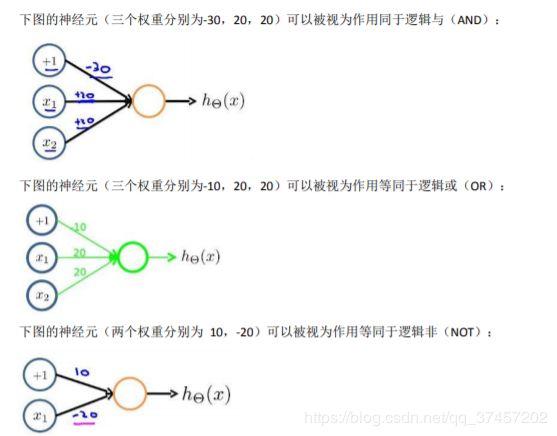

按这种方法我们可以逐渐构造出越来越复杂的函数,也能得到更加厉害的特征值。 这就是神经网络的厉害之处。
8.7 多类分类
画饼!!! 目标分析一波。。。
当我们有不止两种分类时(也就是 y=1,2,3….),比如以下这种情况,该怎么办?如果 我们要训练一个神经网络算法来识别路人、汽车、摩托车和卡车,在输出层我们应该有 4 个 值。例如,第一个值为 1 或 0 用于预测是否是行人,第二个值用于判断是否为汽车。

后续:
接下来进入第九章实践。
下一部分,将会开启新的一篇博文进行书写。
如果喜欢的话 ,麻烦点个赞支持一下咯
未完待续