python tkinter界面 多进程启动scrapy爬取百度贴吧的回复,显示爬取进度,并可以搜索回帖人,指定时间生成词云图,用pyinstaller打包成exe(六)
爬取指定贴吧的帖子 one_tieba_spider.py
'''
这个是爬取 单个贴吧的爬虫
大概思路:
1.进入该贴吧的第N页-第M页,获取所有帖子的初始信息(标题、发帖人、tid)等,组成request_list
2.分别进入每个帖子,先爬取帖子内所有楼层信息,
3.接着根据tid、pid再进入楼内楼,把数据放进对应的楼层里=======>比较难理解一部分,特别是判断锁定楼层next_comment
4.楼内楼都爬取完毕,返回item,以tid为名保存json'''
'''
要点:
1.默认每个帖子最多只爬取前100页,每个楼内楼前100页
2.设定理论爬取item数量,用以进度条等显示爬取进度
3.返回每个items时,也把信息保存到info文件,用在tree上
4.帖子是爬取过的,先获取json文件内容,,若内容有变动,则以此为底,添加新的回复(包括新楼层、新楼内楼)=======>>最难搞的一部分'''
这是具体的思路图,光搞这图,弄清了逻辑关系,也费了我不少时间
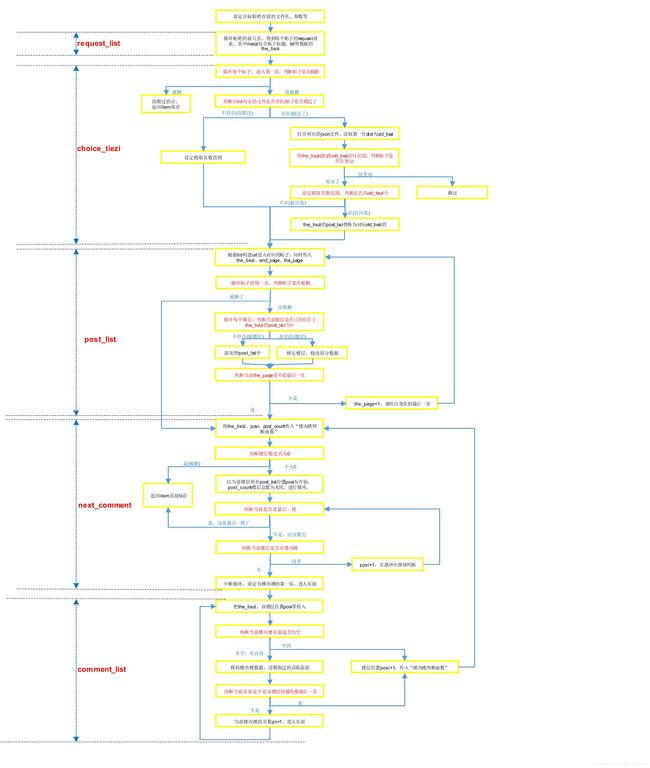
class One_tiebaSpider(scrapy.Spider):
name = "one_tieba"
allowed_domains = ["tieba.baidu.com"]
print(name)
#设定贴吧
kw = None
# 设定存放总文件、贴吧对应文件夹、及其旧帖子文件夹
dir_path = None
path = None
old_file_path = None
#设定贴吧的开始页跟结束页(实际上在pipelines设定)
start_kw_page=1
end_kw_page=1#(此参数是几,那就是前几页)
# 设定每个帖子爬取前N页
max_pages = 100
#设定每个楼内楼爬取前N页
max_comment_page=9
#每10页返回一个item,多了几个10页,意味着就要多返回几个item,用于进度条显示
item_counts=Crawling_item_counts(r'爬取进度详情/the_spider_counts.json')
#每次返回item都要标记(页数范围/被删/没变动)
#把所有帖子标题、发帖人等信息记录,用在treeview进度条上显示详情
log_Crawling=Record_Crawl(r'爬取进度详情/TieBa_info.json')
#总帖子数、进去帖子第一页发现被删、没变动帖子数、返回item数
tiezi_count=0 #理论帖子总数:每页贴子数50*页数
unchanged_count=0 #已经存在的帖子,而且内容没变动
return_count=0
del_count = 0
# 发现被删的几个可能点:1.从贴吧首页发现帖子,但是进入第一页就被删了
# 2.进入完第一页得到总页数后,再次进入第一页,被删了
# 3.已经爬了好几页,突然到某一页,就被删了(这个不记录,因为能被return)
def start_requests(self):
'''设定初始爬取页数,进入某个帖子的第一页'''
self.build_dir() #创建该贴吧所需的文件夹
url = 'https://tieba.baidu.com/f?kw=%s&pn=%d' % (self.kw, (self.start_kw_page-1)*50)
target_word=parse.quote(self.kw)
yield Request(url, callback=self.request_list, dont_filter=True,
meta={'the_page': self.start_kw_page,'request_list':[],'target_word':target_word})
def request_list(self, response):
'''作用:进入某个贴吧的第N页,爬取帖子标题完善request_list后,进入下个parse爬取帖子
传入meta的参数:
the_page:当前贴吧所在的页数
request_list:存放帖子request的list
操作步骤:判断是否空贴吧:···空的,停止爬取
···没问题的,得到帖子标题等信息,设定request放进list
判断是否最后一页:---不是,继续调用自身爬取
---是,去重后循环list,进入下个parse处理每个帖子'''
#提取meta的数据
the_page=response.meta['the_page']
request_list=response.meta['request_list']
target_word=response.meta.get('target_word') #理论爬取贴吧的url,防止没有该贴吧时,自动跳转
text1=re.sub(r'', '', response.body.decode('utf-8'))#贴吧的实际代码都在注释里
req=Selector(text = text1)
threads = req.xpath('//li[contains(@class,"j_thread_list clearfix")]') # 每个帖子
crawl_word=re.findall(r'kw=(.*?)&pn',response.url)[0]
if threads==[] or crawl_word!=target_word:#不是指定的贴吧
print(crawl_word,target_word)
shutil.rmtree(self.path) #删除这个不对的贴吧文件夹
messagebox.showerror("贴吧名不对!!", "这是个错误的贴吧:『%s』"%self.kw)
print('这个贴吧是空的!')
else:
for thread in threads:
the_tiezi = self.the_tiezi(thread) #方法:得到该帖子的标题、发帖人等组成的dict
#设定每个帖子的request
url = 'https://tieba.baidu.com/p/%s' % the_tiezi['tid']
request=Request(url, callback=self.choice_tiezi, dont_filter=True)
request.meta['the_tiezi']=copy.deepcopy(the_tiezi)
#把每个帖子的request放进总list
request_list.append(request)
#添加一页
the_page=the_page+1
next_page = req.xpath('//a[@class="next pagination-item "]/@href')#贴吧的页面是否有“下一页”这个提示
# 此时the_page还不是最后一页而且有下一页的提示,继续调用自身爬取
if the_page<= self.end_kw_page and next_page:
url = 'https://tieba.baidu.com/f?kw=%s&pn=%d' % (self.kw, (the_page-1) * 50)
yield Request(url, callback=self.request_list, dont_filter=True,
meta={'the_page': the_page,'request_list':request_list,'target_word':target_word})
# 此时是最后一页了,那就循环yield每个帖子的request,进入下一步分类处理该帖子
else:
request_list = self.quchong(request_list) # 去重
#标记理论爬取总数
self.tiezi_count=len(request_list)
self.item_counts.update_items(self.tiezi_count-50) #理论返回items数
self.end_kw_page = the_page - 1 # 该贴吧实际爬取的最后页数(因为the_page前面+1了)
for one in request_list:
yield one
def choice_tiezi(self,response):
'''作用:进入帖子的第一页,得到总页数pages,然后分类设定数据,进入帖子的页面爬取楼层
传入meta的参数:
the_tiezi:从首页得到的每个帖子初始数据(除了pages),
操作步骤:判断帖子被删:···被删,返回item保存
···没被删,判断帖子是否爬过:---没爬过,设定爬取页数范围(每10页),进入下一步,爬取楼层
---爬过了,判断是否有变动:***没变动,跳过
***变动了,前N行还是用回文件里的旧楼层post_list,根据页数范围,进入下一步,爬取楼层
后n行,根据页数范围,进入下一步,爬取楼层
'''
sep=Selector(response)
url_alive = sep.xpath('//title/text()').extract_first()
#获取文件路径名字、tid等
the_tiezi = response.meta['the_tiezi']
tid = the_tiezi['tid']
file_path = self.path + os.sep + str(tid) + '.json'#该帖子的json文件,没有就创建,有就说明爬过了
print('准备爬取帖子————《%s》' % the_tiezi['title'])
#只有帖子存在,才会进行操作
if url_alive != '贴吧404':
#设定帖子的总页数、
pages = sep.xpath('//li[@class="l_reply_num"]/span[2]/text()').extract_first() # 该帖子有多少页
pages= int(pages)
the_tiezi['pages']= pages
#一旦多于100页,那就只提取前100页数据,记录此帖子
if pages>self.max_pages:
pages=self.max_pages
Log_Large_TieZi().log(self.kw,the_tiezi)
# 计算出需要多少行dict储存帖子 9页帖子需要1行,44个需要5行
new_lines = (pages - 1) // 10 + 1
#这个帖子是否已经爬过了
if os.path.exists(file_path):
# 得到每10页的old_tiezi字典 组成的list
with open(file_path, 'r', encoding='utf-8') as f:
old_tiezis = [json.loads(tiezi) for tiezi in f.readlines()]
# 原文件共有多少行
old_lines = len(old_tiezis)
old_tiezi = old_tiezis[0] # 取出第一行帖子的dict
# 当最后回复人变动了/回复数量变动/行数变动,那肯定帖子有变,那就更新帖子(没变动就不用理)
if the_tiezi['last_reply_author'] != old_tiezi['last_reply_author'] or the_tiezi['reply_num'] > \
old_tiezi['reply_num'] or old_lines != new_lines:
# 移动旧帖子,把文件放进旧帖子的文件夹里
shutil.move(file_path, r'%s/%s.json'%(self.old_file_path,str(tid)))
# 有可能被删页,例如文件有4行,网页只剩3行了,此时还是循环4次
if old_lines > new_lines:
new_lines = old_lines
##=====标记理论返回items总数
self.item_counts.update_items(new_lines-1)
'''这个循环的思路,分几种:
---多了很多回复,比如旧10页新22页,那么旧文件就是1行,新文件得是3行,
***已经存在的旧行数,the_tiezi就使用旧行数里的post_list,然后更新楼层里的具体数据,
***新的行数,那就直接拿the_tiezi爬取数据
---上面是新≥旧,如果是旧<新,比如:文件是4行(起码31页,才需要保存为4行),
现在只剩29页了,只需3行,那么最后一行运作时,调用的old_tiezi范围是[31,40],
进入post_list函数,url实际跳到29页,可能添加下新楼层,接着就会判断32>29结束'''
#理论是n行,那就循环几次
for i in range(0, new_lines):
#设定该个request进入帖子的页数范围,比如:1~10,41~50,71~80
range_pages = [i * 10 + 1, 10 * i + 10]
# i从0开始,旧的有4行,那么就是0,1,2,3 <4,此时就调用旧的old_tiezi所有行数
if i < old_lines:
#因为爬取时写入顺序不对的,循环整个旧帖子组成的list,
# 若当前的oli_tiezi的第一个post_dict的page跟i页数一致,那么就是这个old_tiezi
try :
old_tiezi=[old_tiezi for old_tiezi in old_tiezis
if old_tiezi['post_list'][0]['page']==range_pages[0]][0]
except:
old_tiezi=the_tiezi
#将the_tiezi的post_list替换,
the_tiezi['post_list'] = old_tiezi['post_list'].copy()
#方法:建立对应的request,下一步开始真正的爬取帖子(再一次爬取第一页)
request = self.post_request(the_tiezi, self.post_list, range_pages)#此时的the_tiezi楼层list为json文件的
yield request
else:
request = self.post_request(the_tiezi, self.post_list, range_pages)#此时的the_tiezi楼层list为[]
yield request
else:
#标记没有变动过的帖子
self.unchanged_count += 1
self.log_Crawling.tiezi_info(the_tiezi, '帖子爬过,没有变动')
# 这个帖子没爬过的,进行爬取
else:
##=====标记理论返回的item数量!!!
self.item_counts.update_items(new_lines - 1)
# 设定为每10页为一个循环
for i in range(0, new_lines):
range_pages = [i * 10 + 1, 10 * i + 10]
# 方法:建立对应的request,下一步开始真正的爬取帖子(再一次爬取第一页)
request=self.post_request(the_tiezi, self.post_list, range_pages)#此时的the_tiezi楼层list为[]
yield request
else:
print('帖子被删了')
#这个是进入第一页时(想获取总页数)发现帖子被删,没有进行判断这时旧帖子还是新帖子,所以只有当这是新帖子时,才会保存,
#标记 进入第一页想获取总页数时就被删
self.del_count+=1
self.log_Crawling.tiezi_info(the_tiezi, '还没进入第一页就被删了')
if not os.path.exists(file_path): #如果不存在这个文件,那也保存下来(只保存下标题发帖人等数据) 没什么卵用,去掉把
return the_tiezi
def post_request(self,the_tiezi,post_list,range_pages):
'''作用:进入 某个帖子 的第N页
设定好需要request的url、处理的parse、及其需要的meta'''
url = 'https://tieba.baidu.com/p/%s?pn=%d' % (the_tiezi['tid'], range_pages[0])
request = Request(url, callback=post_list,dont_filter=True,
meta={'end_page': range_pages[1],
'the_tiezi': copy.deepcopy(the_tiezi), 'the_page': range_pages[0]})
return request
def post_list(self,response):
'''作用:进入帖子的某一页,添加/修改楼层数据(新旧楼都行,不包含楼内楼),根据情况进入下一页或者开始爬取楼内楼
传入meta的三个参数
the_tiezi :整个帖子数据
end_page :该帖子的结束页数
the_page :当前页数
操作步骤:判断帖子被删:···被删,进入下一步,爬取楼内楼
···没被删,得到楼层数据,添加新楼层,修改旧楼层
判断当前是不是最后一页:---是,进入下一步,爬取楼内楼
---不是,调用自身,进入下一页
'''
sep = Selector(response)
the_tiezi = response.meta['the_tiezi']
end_page = response.meta['end_page']
the_page = response.meta['the_page']
tid = the_tiezi['tid']
#帖子没被删,那就进行操作
url_alive = sep.xpath('//title/text()').extract_first()
if url_alive != '贴吧404':
#可能爬的过程中页数变动,所以每次进入帖子都更新页数
pages = sep.xpath('//li[@class="l_reply_num"]/span[2]/text()').extract_first()
the_tiezi['pages'] = int(pages)
# 指向存放楼层的post_list,
the_post_list = the_tiezi['post_list']
# 已经爬取的楼层的pid组成的list,没爬过的帖子为空,得设定
# 用于判断这个楼层是否已经被爬取过了(1.旧json的,包含楼内楼 2.可能中途被删楼,所以重复了)
if the_post_list==[]:
all_pids=[]
else:
all_pids = [post['pid'] for post in the_post_list]
#当前url的所有楼层
all_post = sep.xpath('//div[@class="l_post l_post_bright j_l_post clearfix "]')
#循环所有楼层,对post_list进行添加(新楼层),修改(旧楼层)
for one_post in all_post:
new_post_dict = self.post_dict(one_post, tid, the_page) # 方法:得到该楼层发帖人、时间、内容等组成的dict,除了楼内楼
# 此楼层是新楼层,那把new_post_dict整个放进post_list
if new_post_dict['pid'] not in all_pids:
the_post_list.append(new_post_dict)
# 该楼层已经存在了,先找出它,
else:
# 锁定已经存在的楼层(根据pid)
old_post_dict = [the_post for the_post in the_post_list if the_post['pid'] == new_post_dict['pid']][0]
# 更新该楼层的page、楼内楼回复数量
old_post_dict['page'] = the_page
old_post_dict['comment_num'] = new_post_dict['comment_num']
#添加下一页
the_page = the_page + 1
# 爬好的楼层是10,那么此时page是11>10,或者page>最大页数时,那么就开始爬楼内楼,进入下一个parse
if the_page > end_page or the_page > the_tiezi['pages']:
# post_list里楼层总数量
post_count = len(the_tiezi['post_list'])
#方法:循环楼层,有楼内楼回复的才需要进入下一个parse,如果直接到最后一个回复,就保存
request = self.next_comment(the_tiezi, tid, 0, post_count)
yield request
# 此时还没爬够10页 或者没到最后一页,循环调用自身(相当于进入下一页,继续添加补全the_tiezi)
else:
url = 'https://tieba.baidu.com/p/%s?pn=%d' % (tid, the_page)
request = Request(url, callback=self.post_list,dont_filter=True,
meta={'end_page': end_page, 'the_tiezi': copy.deepcopy(the_tiezi),
'the_page': the_page})
yield request
# 爬到一半,帖子被删了,那么就开始爬楼内楼,进入下一个parse (#也有可能是进入第一页就发现被删,此时楼层数量0)
else:
post_count = len(the_tiezi['post_list'])
# 方法:循环楼层,有楼内楼回复的才需要进入下一个parse,如果直接到最后一个回复,就保存
request = self.next_comment(the_tiezi, tid, 0, post_count)
yield request
def comment_list(self,response):
'''作用:锁定楼层后添加楼内楼,分情况进入下一页或者下一楼层继续爬取楼内楼
传入meta的三个参数
the_tiezi :整个帖子数据
posi :当前楼层所在的位置,用于锁定添加楼内楼的楼层
pn :当前楼层的楼内楼的页数
post_count:总楼层数
先定位各个参数
操作步骤:判断是否空楼内楼:···空的,进入下一楼层的楼内楼
···非空,得到楼内楼数据,添加新楼内楼
判断是不是最后一页了:---是,进入下一楼层的楼内楼
---不是,调用自身,进入下一页'''
post_count=response.meta['post_count']
posi = response.meta['posi']
pn = response.meta['pn']
the_tiezi = response.meta['the_tiezi']
#定位对应楼层、及其楼内楼list
post_dict=the_tiezi['post_list'][posi]
comment_list=post_dict['comment_list']
pid =post_dict['pid']
tid = the_tiezi['tid']
# 当前页面每个楼内楼回复 组成的list
sep = Selector(response)
comments = sep.xpath('//div[@class="lzl_cnt"]')
# 没有内容时,跳出,循环判断下一个有楼内楼的楼层
if comments == []:
request=self.next_comment(the_tiezi,tid,posi,post_count)
yield request
else:
# 循环楼内楼的每个回复
for one_comment in comments:
comment_dict = self.comment_dict(one_comment, pn,tid) # 方法:得到该楼内楼发帖人、时间、内容等组成的dict
# 当此楼内楼没爬过时,就放到该楼层的楼内楼
if comment_dict not in comment_list:
comment_list.append(comment_dict)
comment_pages = sep.xpath('//li[@class="lzl_li_pager j_lzl_l_p lzl_li_pager_s"]/p').xpath('string(.)').extract()[0]
# 当尾页不在页数里面时,说明此楼内楼已经结束了/页数是10页了, 这2种情况出现一种,那就进入下一个楼层的楼内楼
if '尾页' not in comment_pages or pn>self.max_comment_page:
request = self.next_comment(the_tiezi, tid, posi, post_count)
yield request
#继续循环这个楼层的楼内楼,页数+1,进入下一页的楼内楼
else:
pn=pn+1
url = 'https://tieba.baidu.com/p/comment?tid=%s&pid=%s&pn=%s' % (tid, pid, pn)
yield Request(url, callback=self.comment_list,dont_filter=True,
meta={'the_tiezi': copy.deepcopy(the_tiezi), 'posi': posi,
'pn': pn,'post_count':post_count})
def next_comment(self,the_tiezi,tid,posi,post_count):
'''作用:只用于楼内楼,循环楼层,若有楼内楼则进入parse爬取数据,直到最后一楼,然后保存
the_tiezi:整个帖子的数据
posi:已经添加了的楼内楼的楼层在post_list的位置,
post_count:楼层总数,
"循环判断是否要爬取该楼层的楼内楼时比较复杂:
假设post_count共4个,posi是0,1,2,3 ;range(0,4)实际是0,1,2,3
爬完最后一个,posi=3,要循环的话,下一个元素posi就是 4:3+1,
rang(4,4)是没有元素的,所以循环的数列得是range(posi +1, post_count + 1)→→→:range(4,5)
此时i==4==post_count,完成了,保存"
判断楼层总数:···为0,帖子没爬到,直接保存
···以posi+1,post_count+1为循环,判断是否爬完:---最后一个,返回item进入pipelines保存
---没爬完,是否有楼内楼:***有,中断循环,设定为第一页进入楼内楼parse爬取数据
***没有,继续循环'''
posi=posi + 1
#没有楼层,那就是帖子刚爬了标题就被删了,return直接中断保存
if post_count == 0:
print('帖子没爬就被删了')
#标记 正式开始爬取时发现被删
self.del_count+=1
self.log_Crawling.tiezi_info(the_tiezi, '再一次进入第一页被删了')
return the_tiezi
for i in range(posi , post_count + 1):
#是否是最后一个
# (比如共10个楼层,post_list那就是0~9,最后一个时,传入的初始posi=9,循环是range(10,11),此时i=post_count=10,结束)
if i == post_count:
#标记 爬取完后,实际返回的item
self.return_count+=1
self.log_Crawling.tiezi_info(copy.deepcopy(the_tiezi))#需要deep.copy不然the_tiezi会被修改
print('爬完帖子————《%s》' % (the_tiezi['title']))
return the_tiezi
else:
#此楼层有楼内楼时,就会return中断循环,进入楼内楼parse,否则跳过继续循环
#此时i就是该楼层在post_list的位置
if the_tiezi['post_list'][i]['comment_num'] > 0:
# 没爬过的楼层得添加楼内楼list
if the_tiezi['post_list'][i].get('comment_list') is None:
the_tiezi['post_list'][i]['comment_list'] = []
pid = the_tiezi['post_list'][i]['pid']
#进入下一个parse,注意的meta是位置posi,第一页
url = 'https://tieba.baidu.com/p/comment?tid=%s&pid=%s&pn=%s' % (tid, pid, 1)
request=Request(url, callback=self.comment_list,dont_filter=True,
meta={'the_tiezi': copy.deepcopy(the_tiezi), 'posi': i, 'pn': 1,
'post_count': post_count})
return request
#==========================================================================================================
def build_dir(self):
# 设定贴吧文件夹,不存在就创建
self.path = self.dir_path + os.sep +self.kw
if os.path.exists(self.path) is False:
os.mkdir(self.path)
# 设定里面的旧帖子文件夹,不存在就创建
self.old_file_path = self.path + os.sep + '旧帖子'
if os.path.exists(self.old_file_path) is False:
os.mkdir(self.old_file_path)
def quchong(self,request_list):
'''把request重复的帖子请求去掉'''
quchong_list=[]
for request in request_list:
if request not in quchong_list:
quchong_list.append(request)
return quchong_list
def the_tiezi(self,one_thread):
'''输入的是贴吧首页的每条帖子标题的原始信息,
返回标题、发帖人等信息组成的 dict'''
tiezi = TiebaItem()
data = json.loads(one_thread.xpath("@data-field").extract_first()) # 相当于大纲吧
title = one_thread.xpath('.//a[@class="j_th_tit "]/text()').extract_first().strip() #标题
author = data['author_name'] #发帖人
tid = data['id'] #帖子的tid
reply_num = int(data['reply_num']) #帖子的回复数量
last_reply_time = one_thread.xpath(
'.//span[@class="threadlist_reply_date pull_right j_reply_data"]/text()').extract_first()
if last_reply_time is not None: #帖子最后回复时间(顶置的帖子没有)
last_reply_time = last_reply_time.strip()
if re.match(r'\d+:\d+', last_reply_time): # 最后回复时间,以前的只会显示日期;今天的只显示时分,得加上日期
last_reply_time = time.strftime("%Y-%m-%d ", time.localtime()) + last_reply_time
#最后回复人,顶置帖子好像没有?
last_reply_author=one_thread.xpath('.//span[@class="tb_icon_author_rely j_replyer"]/@title').re_first(r'最后回复人: \s*(.*)')
tiezi['title'] = title
tiezi['author'] = author
tiezi['tid'] = tid
tiezi['pages']=None
tiezi['reply_num'] = int(reply_num)
tiezi['last_reply_author'] = last_reply_author
tiezi['last_reply_time'] = last_reply_time
tiezi['post_list'] = [] #所以楼层信息组成的list
return dict(tiezi)
def post_dict(self,one_post,tid,page):
'''输入的是单个楼层的原始信息,
返回楼层的 发帖人、时间、内容等组成的 dict'''
post_dict = {}
data = json.loads(one_post.xpath("@data-field").extract_first()) # 相当于大纲吧
author = data['author']['user_name'] # 发帖人,原ID
pid = data['content']['post_id'] # pid 楼层的id
comment_num = data['content']['comment_num'] # 楼内回复数量
floor = one_post.xpath('.//div[@class="post-tail-wrap"]/span[last()-1]/text()').extract_first() # 第几楼
p_time = one_post.xpath('.//div[@class="post-tail-wrap"]/span[last()]/text()').extract_first() # 回复时间
the_content = one_post.xpath('.//div[@class="d_post_content j_d_post_content "]') # 定位帖子内容
# 文字跟图片、自定义表情提取(忽略了表情)
content = the_content.xpath(
'./text()|./img[@class="BDE_Image"]/@src|./img[@class="BDE_Meme"]/@src').extract()
content = ' '.join(content).strip() # 提取的内容list转为字符串
post_dict['author'] = author
post_dict['floor'] = floor
post_dict['time'] = p_time
post_dict['page'] = page
post_dict['pid'] = pid
post_dict['comment_num'] = int(comment_num)
post_dict['content'] = content
voice = the_content.xpath('.//a[@class="voice_player_inner"]').extract() # 如果有语音回复,就不为空
if voice != []:
post_dict['voice'] = 'https://tieba.baidu.com/voice/index?tid=%s&pid=%s' % (tid, pid) # 语音回复的url
return post_dict
def comment_dict(self,one_comment,pn,tid):
'''输入的是单个楼内楼的原始信息,
返回楼内楼的 发帖人、时间、内容等组成的 dict'''
comment_dict = {}
author = one_comment.xpath('.//a[@class="at j_user_card "]/text()').extract_first() # 发帖人,原ID
content = one_comment.xpath('span[@class="lzl_content_main"]').xpath('string(.)').extract_first().strip() # 内容
reply_time = one_comment.xpath('.//span[@class="lzl_time"]/text()').extract_first() # 发帖时间
spid = one_comment.xpath('../a/@name').extract_first() # spid
comment_dict['author'] = author
comment_dict['content'] = content
comment_dict['time'] = reply_time
comment_dict['spid'] = spid
comment_dict['page'] = pn
voice = one_comment.xpath(
'span[@class="lzl_content_main"]//a[@class="voice_player_inner"]').extract() # 如果有语音回复,就不为空
if voice != []:
comment_dict['voice'] = 'https://tieba.baidu.com/voice/index?tid=%s&pid=%s' % (tid, spid) # 语音回复的url
return comment_dict
哈哈,够恐怖吧,不过大家看懂了那张图,就很快搞清楚代码的了!接下来就是爬取单个帖子,思路差不多,不过