【2019.06.01】33关 python游戏 pythonchallenge 通关记录
地址http://www.pythonchallenge.com/
1. 2的38次方
print(pow(2, 38))
将原url中的 0替换为 274877906944回车就会进入下一关
2. 字符映射
图片中的笔记本给了三组字母,很容易发现规律:前面的字母往后移动两位就是后面的字母。
使用 maketrans 和 translate
text = '''g fmnc wms bgblr rpylqjyrc gr zw fylb. rfyrq ufyr amk
...: nsrcpq ypc dmp. bmgle gr gl zw fylb gq glcddgagclr ylb rfyr'q u
...: fw rfgq rcvr gq qm jmle. sqgle qrpgle.kyicrpylq() gq pcamkkclbc
...: b. lmu ynnjw ml rfc spj.'''
import string
i = string.ascii_lowercase
t = str.maketrans(i, i[2:] + i[:2])
print(text.translate(t))
print('map'.translate(t))
结果是:
i hope you didnt translate it by hand. thats what com
…: puters are for. doing it in by hand is inefficient and that’s w
…: hy this text is so long. using string.maketrans() is recommende
…: d. now apply on the url.
将url中的map也通过该映射进行转换为ocr,进入下一关
3. 统计字符串中字符频率
在网页源代码里。那就右键查看源代码往下拉看到绿色乱码区域
意思就是:要在下面这一大串字符里找到出现次数最少的几个字符
import re
import requests
url = 'http://www.pythonchallenge.com/pc/def/ocr.html'
res = requests.get(url).text
text = re.findall('.*?.*',res,re.S)
text_str = ''.join(text)
lst = []
key =[]
for i in text_str:
lst.append(i)
if i not in key:
key.append(i)
for items in key:
print(items, lst.count(items))
可以看到出现次数最少的就是最后几个字符,合起来是「equality」,替换 url 字符进入下一关
4. One small letter, surrounded by EXACTLY three big bodyguards on each of its sides.
一个小写字母两边有三个大写字母
import re
import requests
url = 'http://www.pythonchallenge.com/pc/def/equality.html'
res = requests.get(url).text
text = re.findall('.*',res,re.S)
print(text)
p = re.compile("[a-z]+[A-Z]{3}([a-z])[A-Z]{3}[a-z]+")
print("".join(p.findall(str(text))))
得到linkedlist
进入http://www.pythonchallenge.com/pc/def/linkedlist.html提示要进linkedlist.php。进入下一关
5.
点开图片到达http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing=12345提示你下一个nothing是44827,
这一关作者弄了个小恶作剧,需要手动输入数值到 url 中然后回车,你以为这样就完了么?并没有它有会不断重复弹出新的数值让你输入,貌似无穷尽。一段简单的爬虫加正则就能搞定。思路很简单,把每次网页中的数值提取出来替换成新的 url 再请求网页,循环下去。不过有个问题是当,结果i到85的时候告诉我要除以2。代码中处理一下
import requests
import re
url = 'http://www.pythonchallenge.com/pc/def/linkedlist.php?nothing='
resp = requests.get(url=url+'12345').text
count = 0
nexturl = ''
nextid = ''
while True:
try:
nextid = re.search('\d+', resp).group()
count += 1
nextid = int(nextid)
except Exception as msg:
# print(msg)
if "Divide by two" in resp:
nextid = nextid/2
else:
print(f'最后一个url为 {nexturl}')
break
nexturl = url + str(nextid)
print(f'url {count}:{nexturl}')
# 重复请求
resp = requests.get(nexturl).text
print(resp)
i = 0
while len(resp) < 5:
i += 1
print(f'再次访问{i}')
resp = requests.get(nexturl).text
最后得到250 peak.html,进入下一关
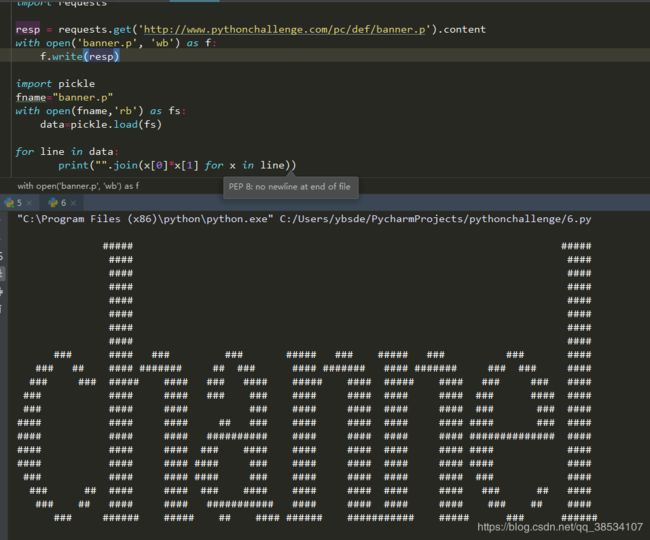
6
import requests
resp = requests.get('http://www.pythonchallenge.com/pc/def/banner.p').content
with open('banner.p', 'wb') as f:
f.write(resp)
import pickle
fname="banner.p"
with open(fname,'rb') as fs:
data=pickle.load(fs)
for line in data:
print("".join(x[0]*x[1] for x in line))