Turbine学习笔记
Turbine学习笔记
Turbine原理
Hystrix/stream
在微服务架构中,Hystrix提供的是一种熔断机制,当分布式系统中的一个服务出现问题时,Hystrix保证该系统不产生雪崩效应,而能继续服务。Hystrix为每一个依赖服务维护一个线程池(或者信号量),当线程池占满,该依赖服务将会立即拒绝服务而不是排队等待。每个依赖服务都被隔离开来,Hystrix 会严格控制其对资源的占用,并在任何失效发生时,执行失败回退逻辑。简单来说,Hystrix通过观察者模式对服务状态进行监听,并将监听信息存储在Hystrix/stream中,或者更确切的说,对于每一个服务的Hystrix/stream,Hystrix会不断去监听该服务,并将监听信息保存下来。具体原理与实现方式在此不做考虑。具体信息如下:

Hystrix Dashboard
Hystrix Dashboard简单来说,就是将Hystrix/stream中的信息以仪表盘的信息展示出来,如下:
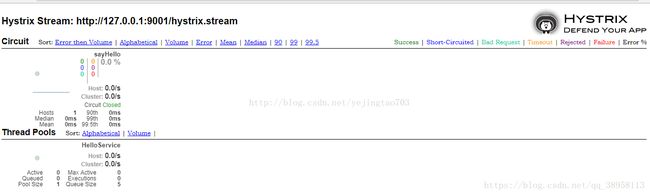
Turbine概述
Turbine真正做的,就是将每一个(指定)服务的 Hystrix/stream中的状态信息取出,并集中处理(计算与展示),应该说,它是具有自己独立的调度的,服务(实例)发现,服务连接,数据聚合,数据输出,共四个过程。
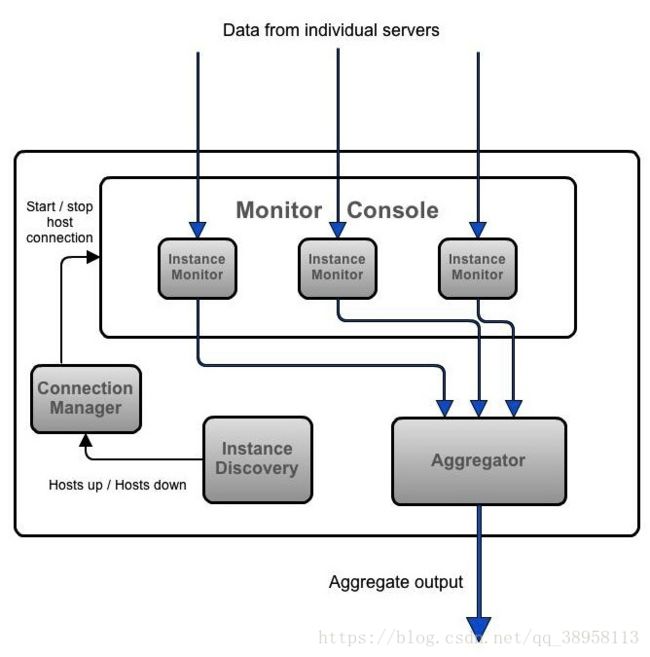
如上图:Turbine首先通过 InstanceDiscovery 模块获取所有的实例信息(定期更新获取),ConnectionManager 负责连接到实例,连接上实例后,便会有源源不断的数据流发送给聚合器 Aggregator,之后,再传送给需要的地方。
Turbine流程
启动
turbine启动的时候会调用TurbineInit的init()方法进行初始化
public static void init() {
/*省略其他·代码*/
//调用start()方式,初始化实例发现
InstanceObservable.getInstance().start(PluginsFactory.getInstanceDiscovery());
}
public void start(InstanceDiscovery iDiscovery) {
/*省略其他·代码*/
//每隔pollDelayMillis通过producer去拉取一次主机的信息
timer.schedule(producer, 0, pollDelayMillis.get());
}
private final TimerTask producer = new TimerTask() {
@Override
public void run() {
/*省略其他·代码*/
for(InstanceObserver watcher: observers.values()) {
if(currentState.get().hostsUp.size() > 0) {
try {
//通知InstanceObserver主机是UP状态
//watcher是个InstanceObserver接口的实例化对象
watcher.hostsUp(currentState.get().hostsUp);
}
}
}
}
};
实际上,Turbine启动过程中,会启用以上方法,将所有是UP状态的实例信息都记录并交给 ConnectionManager,由它负责连接实例。
数据聚合
数据聚合主要包含3个部分:
- TurbineDataMonitor:数据监听,从实例处获取指标
- TurbineDataDispatcher:派发器,将数据聚合后输出到客户端或者下游的数据监听
- TurbineDataHandler:数据处理
InstanceMonitor实例监听类中的startMonitor()方法如下:
public void startMonitor() throws Exception {
/*省略其他·代码*/
@Override
public Void call() throws Exception {
try {
//初始化
init();
monitorState.set(State.Running);
while(monitorState.get() == State.Running) {
//实现
doWork();
}
}
});
}
其中 init() 方法如下:
private void init() throws Exception {
/*省略其他代码*/
HttpGet httpget = new HttpGet(url);
}
url 如下:
private InstanceMonitor(/*省略构造函数参数*/) {
/*省略其他·代码*/
this.url = urlClosure.getUrlPath(host);
}
追本溯源:
/**
* Replaces any {placeholder} attributes in a url suffix using instance attributes
*
* e.x. :{server-port}/hystrix.stream -> :8080/hystrix.stream
*
* @param host instance
* @param url suffix
* @return replaced url suffix
*/
private String processAttributeReplacements(Instance host, String url) {
for (Map.Entry<String, String> attribute : host.getAttributes().entrySet()) {
String placeholder = "{"+attribute.getKey()+"}";
if (url.contains(placeholder)) {
url = url.replace(placeholder, attribute.getValue());
}
}
return url;
}
由此可见,init()方法正在的目的是根据实例的指标地址 hystrix.stream(hystrix/stream) 去获取指标信息。
而在 dowork 方法中:
private void doWork() throws Exception {
/*省略其他·代码*/
//向派发器中发送数据
boolean continueRunning = dispatcher.pushData(getStatsInstance(), list);
}
数据派发
在 TurbineDataDispatcher 中,有方法叫做 pushData() 如下:
public boolean pushData(final Instance host, final Collection<K> statsData) {
/*省略其他·代码*/
for (final HandlerQueueTuple<K> tuple : eventHandlers.values()) {
//HandlerQueueTuple管道中添加数据
tuple.pushData(statsData);
}
return true;
}
HandlerQueueTuple 管道中的方法 pushData() 方法如下:
public void pushData(K data) {
/*省略其他·代码*/
//往队列中写数据
boolean success = queue.writeEvent(data);
}
将数据写进 HandlerQueueTuple 管道中后,需要将他们读取到客户端,该部分在方法 dowork() 中实现:
public void doWork() throws Exception {
/*省略其他·代码*/
do {
//从队列中读取事件
K data = queue.readEvent();
if (data == null) {
numMisses++;
if (numMisses > 100) {
Thread.sleep(100);
numMisses = 0; // reset count so we can try polling again.
}
} else {
statsData.add(data);
numMisses = 0;
stopPolling = true;
}
}
while(!stopPolling);
try {
//通过事件处理器将数据输出到客户端
eventHandler.handleData(statsData);
} catch (Exception e) {
if(eventHandler.getCriteria().isCritical()) {
logger.warn("Could not publish event to event handler for " + eventHandler.getName(), e);
}
}
}
public void handleData(Collection<T> data) {
/*省略其他·代码*/
//写到stream中
writeToStream(data);
}
writeToStream() 方法最终将指标数据响应给浏览器。
Turbine使用
添加依赖
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-turbineartifactId>
dependency>
<dependency>
<groupId>org.springframework.cloudgroupId>
<artifactId>spring-cloud-starter-eurekaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
配置信息
spring.application.name=hystrix-dashboard-turbine
server.port=8009
turbine.appConfig=hello-service,server-feign,service-ribbon#turbine监控的服务名称,可以多个
turbine.aggregator.clusterConfig= default
turbine.clusterNameExpression= new String("default")
eureka.client.service-url.defaultZone=http://localhost:8081/eureka
在服务启动类上添加如下注解开启 Turbine:
@SpringBootApplication
@EnableHystrixDashboard
@EnableTurbine
将相应服务启动,并输入网址 http://localhost:8009/turbine/stream ,将出现如下界面:
信息查看

说明turbine/stream的本质是获取多个服务的hystrix/stream
我们打开Dashboard,并在地址栏里输入 http://localhost:8009/turbine/stream ,并使用Apache的ab压力测试工具测试:

结果如上,Hystrix Dashboard Wiki上详细说明了图上每个指标的含义,如下图:
