python 领英爬虫
请勿将爬虫应用于非法活动,保护网络信息安全,人人有责.
**1.**一般我们爬取领英都是想爬领英上关于那个公司的所有员工,所以我们有两种方法(我已知的),一个是百度(领英+公司名称),从中抽取个人领英页面,从而进入个人领英页面进行信息的抓取,一般百度只会提供前75页信息,so,你可能抓不全,但这里我提供一种思路,这种思路仅仅简历在你想要抓完全的情况下可用:一般领英个人界面的右边回提供,推荐认识的人,你只需在右边的推荐人里进行广度或深度遍历,再建立筛选机制,这样应该是能抓取成功的,代价是(时间成本太高,且不易控制)。第二种是直接在领英的官网页搜索公司名称,这样可以获得该公司所有员工的信息,但受制于领英人脉圈的限制,你可能无法得到大部分人的信息,我说一个比较贱的办法,你注册一个领英账号,然后,成为该公司的员工,再添加好友,这样能在最大程度获得所有人员信息这算是前期的准备工作。
**2.**我的这个爬虫程序是这样的,你在领英搜索入口搜索到公司消息后,点击下一页,见到url后面有page=,你就可以把它复制下来,填入到linkedin_crawler下面:

url链接,把url后面page=的数字去掉即可

url链接,把url后面page=的数字去掉即可

这个数字是总的页数,例如这里是这个公司的人员信息只有14页
**3.**众所周知领英的反爬是很严格的,稍有不慎就会封号让你上传个人信息,因为它会认为你是恶意的,为了解决这样的情况,最大程度的避免爬虫随时可能中断的局面,我采用了以下措施来应对这一情况:
(1):使用cookie池来假冒成非恶意爬虫:
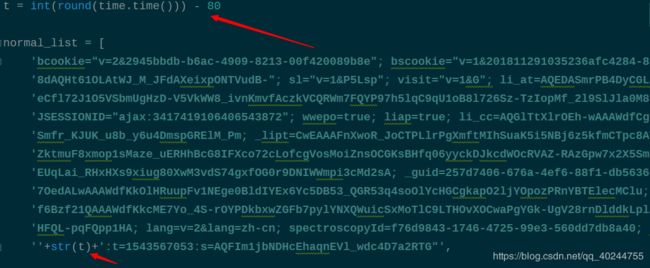
可以看到的是,我修改了时间戳,让它看起来像是很自然地人为访问,而normal_list是正常访问个人页面的cookie_list,pro_cookie则是访问个人信息所用的cookie_list,dis_cookie则是翻页的cookie_list,我是在linkedin_crawler中采用随机的形式调用的
(2)使用redis来记录哪些是已经爬取了的:

10的意思是有效日期为10天

所以你如果想使用这段爬虫代码,你还需要在你的电脑上安装redis,至于redis的教程,我在这里就不一一赘述了
有了以上两种方法,基本可以在账号被领英暂时封禁一天后(不需要提供身份信息,代价极其低),在期间更换其它账号cookie即可。
4
下面大概说说我是怎么解析个人页面的把,毫无疑问领英的前端工程师,确实有着非凡的智慧,我个人是很佩服他们所写的js代码的,真的很厉害。
(1):

清洗网页非必要的字符,这点很重要
(2):

通过正则表达式匹配相应的信息
(3):
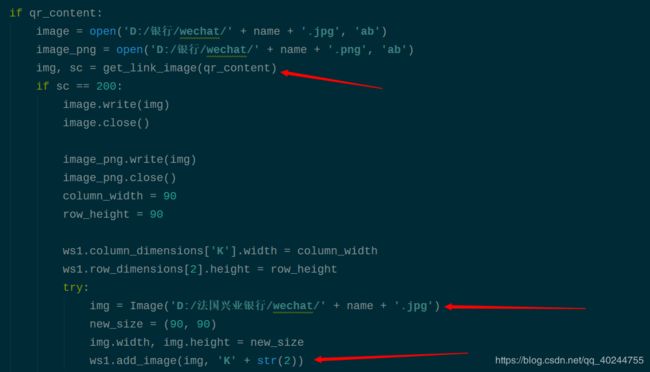
获取图片信息,例如以上的微信二维码图片
(4):

5
我觉得写的并不是很好,如果你想要查看借鉴我的代码 ,可以进入我的github仓库地址进行查看:https://github.com/madpudding/linkedIn-crawler
如果觉得好别忘了小星星哦,可以拿来主义,但请不要把我代码当成你的劳动成果进行传播,那样是很可耻的一件事情,望君三思。
如果你想联系我(领英数据抓取或者其他网站数据抓取)可以给我发邮件:[email protected]