Hadoop 的三种运行模式_完全分布式运行模式(详解)
完整:https://blog.csdn.net/qq_40794973/article/details/86681941
版本:Apache Hadoop 2.7.2
一、虚拟机环境准备
1. 克隆虚拟机
2. 修改克隆虚拟机的静态IP
- 网卡配置文件位置: /etc/sysconfig/network-scripts/ifcfg-eth0
- 地址和Mac地址绑定的文件: /etc/udev/rules.d/70-persistent-net.rules
打开 /etc/udev/rules.d/70-persistent-net.rules 文件

打开 /etc/sysconfig/network-scripts/ifcfg-eth0 文件
DEVICE=eth0
HWADDR=00:0c:29:c0:4e:e7
TYPE=Ethernet
ONBOOT=yes
NM_CONTROLLED=yes
BOOTPROTO=static
IPADDR=192.168.19.Xx
NETMASK=255.255.255.0
GATEWAY=192.168.19.2
DNS1=144.144.144.144
DNS2=8.8.8.8注:前面复制的 mac 地址就是HWADDR 的配置,实际的ip地址根据情况决定。
3. 修改主机名
vi /etc/sysconfig/network注: hostname 用于查看主机名,这里需要重启生效,我们后面统一重启。
4. 关闭防火墙
查看版本:
cat /etc/issue CentOS6:
临时关闭打开:
通过service命令
service命令开启以及关闭防火墙为即时生效,下次重启机器的时候会自动复原。
查看防火墙状态:service iptables status(在CentOS6.9中是输入iptables)
打开防火墙:service iptables start
关闭防火墙:service iptables stop通过:/etc/init.d/iptables 进行操作
查看防火墙状态:/etc/init.d/iptables status
打开防火墙:/etc/init.d/iptables start
关闭防火墙:/etc/init.d/iptables stop
开机不启动:
chkconfig命令
查看状态:chkconfig --list iptables
永久开启防火墙:chkconfig iptables on
永久关闭防火墙:chkconfig iptables off
注:CentOS6 和 CentOS7 所使用的防火墙是不同的,CentOS7有关于防护墙的命令百度即可,这里并不一定要关闭防火墙,我这里为了简单直接把防火墙关了简单粗暴。
5. 创建用户(yuanyu )
[root@hadoop1 home]# useradd yuanyu
[root@hadoop1 home]# passwd yuanyu
更改用户 yuanyu 的密码 。
新的 密码:
无效的密码: 过于简单化/系统化
无效的密码: 过于简单
重新输入新的 密码:
passwd: 所有的身份验证令牌已经成功更新。
6. 配置用户(yuanyu )具有root权限
visudo 打开 /etc/sudoers 文件

7.在/opt目录下创建文件夹
7.1、在/opt目录下创建module、software文件夹
[yuanyu@hadoop50 ~]$ cd /opt/
[yuanyu@hadoop50 opt]$ sudo mkdir module
[sudo] password for yuanyu:
[yuanyu@hadoop50 opt]$ sudo mkdir software
[yuanyu@hadoop50 opt]$ ll
总用量 12
drwxr-xr-x. 2 root root 4096 3月 30 08:46 module
drwxr-xr-x. 2 root root 4096 3月 26 2015 rh
drwxr-xr-x. 2 root root 4096 3月 30 08:46 software
注:software 用于存放安装包,module 存放软件具体的安装路径。
7.2、修改module、software文件夹的所有者cd
sudo chown yuanyu:yuanyu module/ software/[yuanyu@hadoop50 opt]$ sudo chown yuanyu:yuanyu module/ software/
[yuanyu@hadoop50 opt]$ ll
总用量 12
drwxr-xr-x. 2 yuanyu yuanyu 4096 3月 30 08:46 module
drwxr-xr-x. 2 root root 4096 3月 26 2015 rh
drwxr-xr-x. 2 yuanyu yuanyu 4096 3月 30 08:46 software
二、导入安装包,并解压
注:传文件到集群的时候使用 yuanyu ,这两文件的所有者是 yuanyu 不用在次修改权限。
[yuanyu@hadoop50 opt]$ cd /opt/software/
[yuanyu@hadoop50 software]$ ll
总用量 374196
-rw-rw-r--. 1 yuanyu yuanyu 197657687 3月 30 08:59 hadoop-2.7.2.tar.gz
-rw-rw-r--. 1 yuanyu yuanyu 185515842 3月 30 08:59 jdk-8u144-linux-x64.tar.gz
2.1、解压JDK Hadoop 到/opt/module目录下
[yuanyu@hadoop50 software]$ tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
[yuanyu@hadoop50 software]$ tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/
2.2、查看是否解压成功
[yuanyu@hadoop50 software]$ cd /opt/module/
[yuanyu@hadoop50 module]$ ll
总用量 8
drwxr-xr-x. 9 yuanyu yuanyu 4096 5月 22 2017 hadoop-2.7.2
drwxr-xr-x. 8 yuanyu yuanyu 4096 7月 22 2017 jdk1.8.0_144
2.3、配置JDK环境变量
2.3.1、获取JDK路径
[yuanyu@hadoop50 jdk1.8.0_144]$ cd /opt/module/jdk1.8.0_144/
[yuanyu@hadoop50 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
2.3.2、打开/etc/profile文件
[yuanyu@hadoop50 jdk1.8.0_144]$ sudo vi /etc/profile
2.3.3、打开/etc/profile文件
在profile文件末尾添加JDK路径
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin2.3.4、让修改后的文件生效
[yuanyu@hadoop50 jdk1.8.0_144]$ source /etc/profile
2.3.5、测试JDK是否安装成功
[yuanyu@hadoop50 jdk1.8.0_144]$ java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
注:java -version java javac 命名不可以,重启试一试 sudo reboot。
2.4、配置 Hadoop
2.4.1、获取Hadoop安装路径
[yuanyu@hadoop50 jdk1.8.0_144]$ cd /opt/module/hadoop-2.7.2/
[yuanyu@hadoop50 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
2.4.2、打开/etc/profile文件
[yuanyu@hadoop50 hadoop-2.7.2]$ sudo vi /etc/profile
在profile文件末尾添加 Hadoop 路径:(shitf+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
2.4.3、让修改后的文件生效
[yuanyu@hadoop50 hadoop-2.7.2]$ source /etc/profile
2.4.4、测试是否安装成功
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop version
Hadoop 2.7.2
Subversion Unknown -r Unknown
Compiled by root on 2017-05-22T10:49Z
Compiled with protoc 2.5.0
From source with checksum d0fda26633fa762bff87ec759ebe689c
This command was run using /opt/modul
注:hadoop version 命名不可以,重启试一试 sudo reboot。
三、其他配置
192.168.19.50 hadoop50
192.168.19.51 hadoop51
192.168.19.52 hadoop523.1、配置 Linux 里面的 host 文件
[yuanyu@hadoop50 hadoop-2.7.2]$ sudo vi /etc/hosts

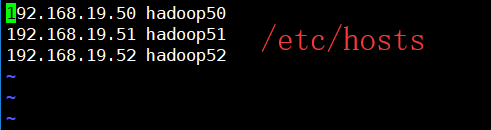
Windows 里面 c:/windows/system32/drivers/etc/hosts 也配置
3.2、修改文件 /etc/selinux/config
把 SELINUX=enforcing 改为 SELINUX=disabled
四、伪分布模式简单测试
4.1、配置:hadoop-env.sh
Linux系统中获取JDK的安装路径:
[yuanyu@hadoop50 ~]$ cd /opt/module/jdk1.8.0_144/
[yuanyu@hadoop50 jdk1.8.0_144]$ pwd
/opt/module/jdk1.8.0_144
添加 JAVA_HOME 路径(shitf+g 末尾添加):
[yuanyu@hadoop50 hadoop-2.7.2]$ vi etc/hadoop/hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144[yuanyu@hadoop50 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
[yuanyu@hadoop50 hadoop-2.7.2]$ cd etc/hadoop/
[yuanyu@hadoop50 hadoop]$ vi hadoop-env.sh
4.2、 配置:core-site.xml
[yuanyu@hadoop50 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[yuanyu@hadoop50 hadoop]$ vi core-site.xml
fs.defaultFS
hdfs://hadoop50:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
4.3、格式化NameNode
bin/hdfs namenode -format[yuanyu@hadoop50 hadoop-2.7.2]$ pwd
/opt/module/hadoop-2.7.2
[yuanyu@hadoop50 hadoop-2.7.2]$ bin/hdfs namenode -format
4.4、 启动NameNode、DataNode、查看集群
[yuanyu@hadoop50 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-namenode-hadoop50.out
[yuanyu@hadoop50 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop50.out
[yuanyu@hadoop50 hadoop-2.7.2]$ jps
2977 DataNode
2913 NameNode
3022 Jps
4.5、 web端查看HDFS文件系统
http://hadoop50:50070/dfshealth.html#tab-overview
不能访问:https://blog.csdn.net/qq_40794973/article/details/86663969
五、完全分布式模式搭建
5.1、集群规划
hadoop50 hadoop51
hadoop52
HDFS NameNode
DataNode
DataNode
SecondaryNameNode
DataNode
YARN NodeManager
ResourceManager
NodeManager
NodeManager
5.2、其余服务器的配置
前面一直都是一台服务器(hadoop50)在工作,这里还需要两台服务器 (hadoop51、hadoop52)。在 VMware 克隆 hadoop50,修改 ip 地址、主机名、host文件前面我们配置过,由于是克隆的所有不用配置了。
- 修改克隆虚拟机的静态IP:https://blog.csdn.net/qq_40794973/article/details/88904718#t2
- 修改主机名:https://blog.csdn.net/qq_40794973/article/details/88904718#t3
- 重启 reboot
注:由于我们是用 VMware 克隆得到了另外的两台主机,这个时候我们很多东西都是不需要配置的,这和真正的开发环境还是有一些差别的。
5.3、配置集群
主要配置的文件如下所示:
- core-site.xml
- hadoop-env.sh
- hdfs-site.xml
- mapred-env.sh
- yarn-env.sh
- yarn-site.xml
注:后缀为 .sh 的,是用来配置路径的,比如 JDK 路径。
5.3.1、集群分发脚本
由于我们有很多集群,每个集群的配置环境是一模一样的,这个时候我们不太可能一个一个的去配置,这样太费事费力,而且是没有必要的事情。
脚本实现:
1、在 /home/yuanyu 目录下创建bin目录,并在bin目录下xsync创建文件。在该文件中编写如下代码:
[yuanyu@hadoop50 hadoop-2.7.2]$ cd ~
[yuanyu@hadoop50 ~]$ mkdir bin
[yuanyu@hadoop50 ~]$ cd bin/
[yuanyu@hadoop50 bin]$ touch xsync
[yuanyu@hadoop50 bin]$ vi xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录的绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=51; host<53; host++)); do
echo ------------------- hadoop$host --------------
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
2、修改脚本 xsync 具有执行权限
[yuanyu@hadoop50 bin]$ chmod 777 xsync
3、调用脚本形式:xsync 文件名称
[yuanyu@hadoop50 bin]$ xsync /home/atguigu/bin
注意:如果将xsync放到/home/atguigu/bin目录下仍然不能实现全局使用,可以将xsync移动到/usr/local/bin目录下。
5.3.2、核心配置文件
配置core-site.xml
[yuanyu@hadoop50 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[yuanyu@hadoop50 hadoop]$ vi core-site.xml
fs.defaultFS
hdfs://hadoop50:9000
hadoop.tmp.dir
/opt/module/hadoop-2.7.2/data/tmp
注:其实这个配置我们前面已经配置过,这里就不用配置了。
5.3.3、HDFS配置文件
配置hadoop-env.sh
[yuanyu@hadoop50 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144注:其实这个配置我们前面已经配置过,这里就不用配置了。
配置 hdfs-site.xml
[yuanyu@hadoop50 hadoop]$ vi hdfs-site.xml
dfs.replication
3
dfs.namenode.secondary.http-address
hadoop52:50090
5.3.4、YARN配置文件
配置yarn-env.sh
[yuanyu@hadoop50 hadoop]$ vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144配置yarn-site.xml
[yuanyu@hadoop50 hadoop]$ vi yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop51
5.3.5、 MapReduce配置文件
配置mapred-env.sh
[yuanyu@hadoop50 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144配置mapred-site.xml
[yuanyu@hadoop50 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[yuanyu@hadoop50 hadoop]$ vi mapred-site.xml
mapreduce.framework.name
yarn
[yuanyu@hadoop50 hadoop]$ cd ~
[yuanyu@hadoop50 ~]$ mkdir bin
[yuanyu@hadoop50 ~]$ touch bin/xsync
[yuanyu@hadoop50 ~]$ vi bin/xsync
5.3.6、在集群上分发配置好的Hadoop配置文件
[yuanyu@hadoop50 hadoop-2.7.2]$ xsync /opt/module/hadoop-2.7.2/
5.3.7、查看文件分发情况
[yuanyu@hadoop51 hadoop-2.7.2]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
[yuanyu@hadoop52 hadoop-2.7.2]$ cat /opt/module/hadoop-2.7.2/etc/hadoop/core-site.xml
5.4、集群单点启动
5.4.1、如果集群是第一次启动,需要格式化NameNode
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop namenode -format
5.4.2、在hadoop50上启动NameNode
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop-daemon.sh start namenode
starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-namenode-hadoop50.out
[yuanyu@hadoop50 hadoop-2.7.2]$ jps
2602 Jps
2556 NameNode
5.4.3、在hadoop102、hadoop103以及hadoop104上分别启动DataNode
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop50.out
[yuanyu@hadoop50 hadoop-2.7.2]$ jps
2694 DataNode
2744 Jps
2556 NameNode[yuanyu@hadoop51 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop51.out
[yuanyu@hadoop51 hadoop-2.7.2]$ jps
2386 Jps
2344 DataNode[yuanyu@hadoop52 hadoop-2.7.2]$ hadoop-daemon.sh start datanode
starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop52.out
[yuanyu@hadoop52 hadoop-2.7.2]$ jps
2371 Jps
2329 DataNode
注:这里我只是启动了HDFS,YARN 还没有启动,单点启动集群需要输入很多命令过于繁琐,我们通过配置SSH无密登录即可实现群起集群。
5.5、SSH无密登录配置
5.5.1、配置ssh
1、基本语法
ssh 另一台电脑的ip地址2、ssh连接时出现Host key verification failed的解决方法
[atguigu@hadoop102 opt] $ ssh 192.168.1.103
The authenticity of host '192.168.1.103 (192.168.1.103)' can't be established.
RSA key fingerprint is cf:1e:de:d7:d0:4c:2d:98:60:b4:fd:ae:b1:2d:ad:06.
Are you sure you want to continue connecting (yes/no)?
Host key verification failed.
解决方案如下:直接输入yes
5.5.2、无密钥配置
路径:/home/yuanyu/.ssh
注:如果没有这个路径,执行以下 ssh 命令就有了,或者直接创建这个文件即可。
[yuanyu@hadoop50 hadoop-2.7.2]$ ssh hadoop51
yuanyu@hadoop51's password:
Last login: Mon Apr 1 00:20:45 2019 from 192.168.19.1
[yuanyu@hadoop51 ~]$ exit
logout
Connection to hadoop51 closed.
[yuanyu@hadoop50 hadoop-2.7.2]$ cd ~
[yuanyu@hadoop50 ~]$ ls -al
总用量 56
drwx------. 7 yuanyu yuanyu 4096 4月 1 01:13 .
drwxr-xr-x. 3 root root 4096 4月 1 00:12 ..
-rw-------. 1 yuanyu yuanyu 1025 4月 1 01:13 .bash_history
-rw-r--r--. 1 yuanyu yuanyu 18 5月 11 2016 .bash_logout
-rw-r--r--. 1 yuanyu yuanyu 176 5月 11 2016 .bash_profile
-rw-r--r--. 1 yuanyu yuanyu 124 5月 11 2016 .bashrc
drwxrwxr-x 2 yuanyu yuanyu 4096 4月 1 01:05 bin
drwxr-xr-x. 2 yuanyu yuanyu 4096 11月 12 2010 .gnome2
drwxr-xr-x. 4 yuanyu yuanyu 4096 1月 11 06:41 .mozilla
drwxrwxr-x. 2 yuanyu yuanyu 4096 3月 30 09:13 .oracle_jre_usage
drwx------ 2 yuanyu yuanyu 4096 4月 1 01:05 .ssh
-rw------- 1 yuanyu yuanyu 6504 4月 1 01:05 .viminfo
-rw------- 1 yuanyu yuanyu 108 4月 1 01:13 .Xauthority[yuanyu@hadoop50 .ssh]$ pwd
/home/yuanyu/.ssh
生成公钥和私钥:
ssh-keygen -t rsa然后敲(三个回车),就会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
[yuanyu@hadoop50 .ssh]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/yuanyu/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/yuanyu/.ssh/id_rsa.
Your public key has been saved in /home/yuanyu/.ssh/id_rsa.pub.
The key fingerprint is:
ec:f5:30:92:09:a9:d6:2c:f6:d8:2f:61:a9:6e:27:61 yuanyu@hadoop50
The key's randomart image is:
+--[ RSA 2048]----+
| |
| . |
| o |
| + o o |
| = o.S + |
| oE=+. o + |
| ..+o.. . |
| + o. |
| o.o .. |
+-----------------+
[yuanyu@hadoop50 .ssh]$[yuanyu@hadoop50 .ssh]$ ll
总用量 12
-rw------- 1 yuanyu yuanyu 1675 4月 1 01:56 id_rsa
-rw-r--r-- 1 yuanyu yuanyu 397 4月 1 01:56 id_rsa.pub
-rw-r--r-- 1 yuanyu yuanyu 808 4月 1 01:06 known_hosts
5.5.3、将公钥拷贝到要免密登录的目标机器上
[yuanyu@hadoop50 .ssh]$ ssh-copy-id hadoop102
[yuanyu@hadoop50 .ssh]$ ssh-copy-id hadoop103
[yuanyu@hadoop50 .ssh]$ ssh-copy-id hadoop104
注意:
还需要在hadoop50上采用root账号,配置一下无密登录到hadoop50、hadoop51、hadoop52。
还需要在hadoop51上采用yuanyu账号配置一下无密登录到hadoop50、hadoop51、hadoop52服务器上。
[root@hadoop50 .ssh]# pwd
/root/.ssh
[root@hadoop50 .ssh]# ssh-keygen -t rsa
[root@hadoop50 .ssh]# ssh-copy-id hadoop50
[root@hadoop50 .ssh]# ssh-copy-id hadoop51
[root@hadoop50 .ssh]# ssh-copy-id hadoop52
[yuanyu@hadoop51 .ssh]$ pwd
/home/yuanyu/.ssh
[yuanyu@hadoop51 .ssh]$ ssh-keygen -t rsa
[yuanyu@hadoop51 .ssh]$ ssh-copy-id hadoop50
[yuanyu@hadoop51 .ssh]$ ssh-copy-id hadoop51
[yuanyu@hadoop51 .ssh]$ ssh-copy-id hadoop52
5.6、群起集群
5.6.1、配置slaves
vi /opt/module/hadoop-2.7.2/etc/hadoop/slaveshadoop50
hadoop51
hadoop52注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
同步所有节点配置文件
[yuanyu@hadoop50 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[yuanyu@hadoop50 hadoop]$ xsync slaves
5.6.2、启动集群
如果集群是第一次启动,需要格式化NameNode(注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据)
[yuanyu@hadoop50 hadoop-2.7.2]$ bin/hdfs namenode -format
5.6.3、启动HDFS
[yuanyu@hadoop50 hadoop-2.7.2]$ jps
3152 Jps
[yuanyu@hadoop50 hadoop-2.7.2]$ sbin/start-dfs.sh
Starting namenodes on [hadoop50]
hadoop50: starting namenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-namenode-hadoop50.out
hadoop50: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop50.out
hadoop51: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop51.out
hadoop52: starting datanode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-datanode-hadoop52.out
Starting secondary namenodes [hadoop52]
hadoop52: starting secondarynamenode, logging to /opt/module/hadoop-2.7.2/logs/hadoop-yuanyu-secondarynamenode-hadoop52.out
[yuanyu@hadoop50 hadoop-2.7.2]$ jps
4449 DataNode
4723 Jps
4342 NameNode[yuanyu@hadoop51 hadoop-2.7.2]$ jps
2770 Jps
[yuanyu@hadoop51 hadoop-2.7.2]$ jps
2821 DataNode
2906 Jps
[yuanyu@hadoop52 hadoop-2.7.2]$ jps
2827 Jps
[yuanyu@hadoop52 hadoop-2.7.2]$ jps
2951 SecondaryNameNode
2876 DataNode
3039 Jps
5.6.4、启动YARN
[yuanyu@hadoop51 hadoop-2.7.2]$ sbin/start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-yuanyu-resourcemanager-hadoop51.out
hadoop51: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-yuanyu-nodemanager-hadoop51.out
hadoop52: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-yuanyu-nodemanager-hadoop52.out
hadoop50: starting nodemanager, logging to /opt/module/hadoop-2.7.2/logs/yarn-yuanyu-nodemanager-hadoop50.out
[yuanyu@hadoop50 hadoop-2.7.2]$ jps
6384 Jps
5879 DataNode
5962 NodeManager
5772 NameNode[yuanyu@hadoop51 hadoop-2.7.2]$ jps
3594 DataNode
3675 ResourceManager
3790 NodeManager
4191 Jps[yuanyu@hadoop52 hadoop-2.7.2]$ jps
3900 Jps
3597 NodeManager
3709 SecondaryNameNode
3518 DataNode
注意:NameNode和ResourceManger如果不是同一台机器,不能在NameNode上启动 YARN,应该在ResouceManager所在的机器上启动YARN。
5.6.5、Web端查看SecondaryNameNode
浏览器中输入:http://hadoop50:50070/dfshealth.html#tab-overview
5.6.6、集群基本测试
创建一个目录 /yuan
[yuanyu@hadoop52 hadoop-2.7.2]$ hadoop fs -mkdir /yuan
上传文件到 yuan 目录里面
[yuanyu@hadoop52 hadoop-2.7.2]$ hadoop fs -put /opt/software/hadoop-2.7.2.tar.gz /yuan
Web 能够查看到,集群就配置成功了。
六、其他配置
YARN的浏览器页面查看:http://hadoop51:8088/cluster
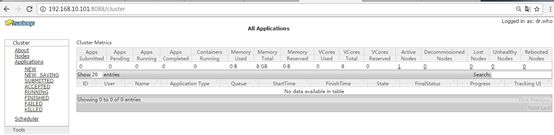
6.1运行MapReduce程序
(a)在HDFS文件系统上创建一个input文件夹
[yuanyu@hadoop50 hadoop-2.7.2]$ bin/hdfs dfs -mkdir -p /user/yuanyu/input
(b)将测试文件内容上传到文件系统上
[yuanyu@hadoop50 hadoop-2.7.2]$ mkdir wcinput
[yuanyu@hadoop50 hadoop-2.7.2]$ vi wcinput/wc.input
hadoop yarn
hadoop mapreduce
atguigu
atguigu[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop fs -put wcinput/wc.input /user/yuanyu/input
(c)查看上传的文件是否正确
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop fs -ls /user/yuanyu/input/
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop fs -cat /user/yuanyu/input/wc.input
(d)运行MapReduce程序
[yuanyu@hadoop50 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/yuanyu/input/ /user/yuanyu/output
(e)查看运行结果http://hadoop51:8088/cluster
[yuanyu@hadoop50 hadoop-2.7.2]$ bin/hdfs dfs -cat /user/yuanyu/output/*

6.2、 配置历史服务器
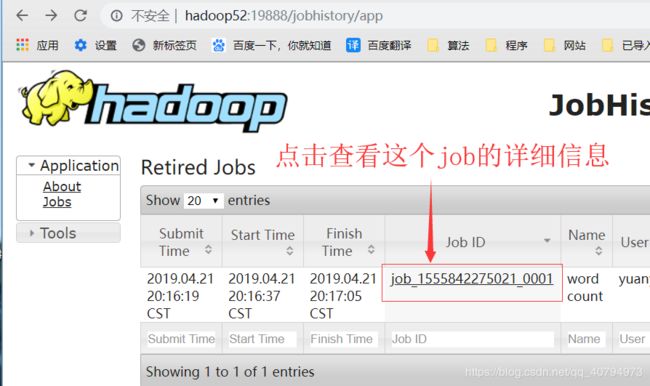
为了查看程序的历史运行情况,需要配置一下历史服务器。
1. 配置mapred-site.xml
[yuanyu@hadoop50 hadoop-2.7.2]$ cd etc/hadoop/
[yuanyu@hadoop50 hadoop]$ vi mapred-site.xml
在该文件里面增加如下配置。
mapreduce.jobhistory.address
hadoop52:10020
mapreduce.jobhistory.webapp.address
hadoop52:19888
群发
[yuanyu@hadoop50 hadoop]$ xsync mapred-site.xml
2. 启动历史服务器
[yuanyu@hadoop52 hadoop-2.7.2]$ sbin/mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /opt/module/hadoop-2.7.2/logs/mapred-yuanyu-historyserver-hadoop52.out
注意:启动历史服务器需要在配置的那台集群上启动,mr-jobhistory-daemon.sh job历史服务器的守护进程。
3. 查看历史服务器是否启动
[yuanyu@hadoop52 hadoop-2.7.2]$ jps
2328 SecondaryNameNode
2444 NodeManager
3325 Jps
2238 DataNode
3279 JobHistoryServer
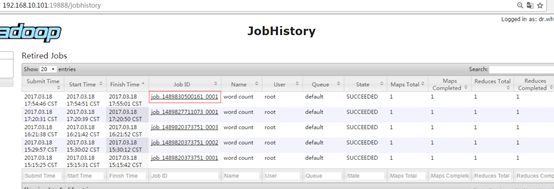
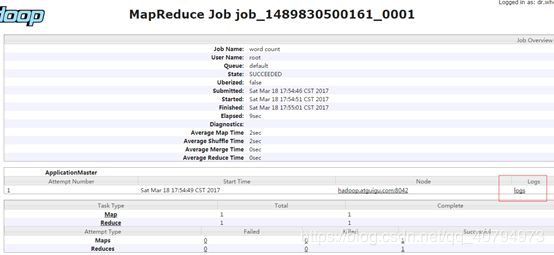
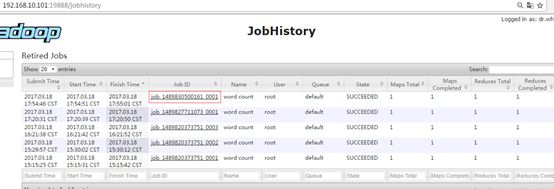
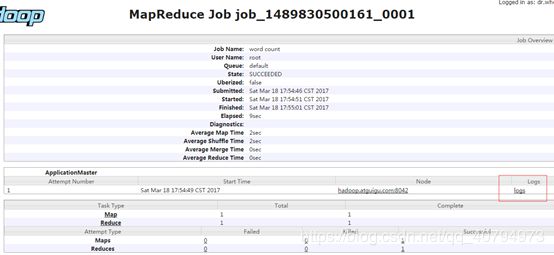
4. 查看JobHistory
http://hadoop52:19888/jobhistory
注:配置历史服务器不需要重新启动集群。
6.2、配置日志的聚集
- 日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
- 日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动NodeManager 、ResourceManager和HistoryManager。
开启日志聚集功能具体步骤如下:
1. 配置yarn-site.xml
[yuanyu@hadoop50 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[yuanyu@hadoop50 hadoop]$ vi yarn-site.xml
在该文件里面增加如下配置。
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
群发
[yuanyu@hadoop50 hadoop]$ xsync yarn-site.xml
2. 关闭NodeManager 、ResourceManager和HistoryManager(我这里就直接重新启动集群)
https://blog.csdn.net/qq_40794973/article/details/89344830
[yuanyu@hadoop50 hadoop]$ stopHadoop.sh
[yuanyu@hadoop50 hadoop]$ startHadoop.sh
stopHadoop.sh
#!/bin/bash
echo "关闭hdfs中..."
ssh hadoop50 "/opt/module/hadoop-2.7.2/sbin/stop-dfs.sh"
echo -e "\n\n"
echo "关闭yarn中..."
ssh hadoop51 "/opt/module/hadoop-2.7.2/sbin/stop-yarn.sh"
echo -e "\n\n"
#关闭历史服务器 hadoop52
echo "关闭历史服务器中..."
ssh hadoop52 "/opt/module/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh stop historyserver"
echo -e "\n\n"
echo "关闭情况..."
for i in hadoop50 hadoop51 hadoop52
do
echo "---------------------Hadoop$i jps---------------------"
ssh $i '/opt/module/jdk1.8.0_144/bin/jps'
echo -e "\n"
donestartHadoop.sh
#!/bin/bash
echo "启动hdfs中..."
ssh hadoop50 "/opt/module/hadoop-2.7.2/sbin/start-dfs.sh"
echo -e "\n\n"
echo "启动yarn中..."
ssh hadoop51 "/opt/module/hadoop-2.7.2/sbin/start-yarn.sh"
echo -e "\n\n"
#启动历史服务器 hadoop52
echo "启动历史服务器中..."
ssh hadoop52 "/opt/module/hadoop-2.7.2/sbin/mr-jobhistory-daemon.sh start historyserver"
echo -e "\n\n"
echo "启动情况..."
for i in hadoop50 hadoop51 hadoop52
do
echo "---------------------Hadoop$i启动情况---------------------"
ssh $i '/opt/module/jdk1.8.0_144/bin/jps'
echo -e "\n\n"
done3. 删除HDFS上已经存在的输出文件
[yuanyu@hadoop50 hadoop-2.7.2]$ hadoop fs -rm -R /user/yuanyu/output
4. 执行WordCount程序
[yuanyu@hadoop50 hadoop-2.7.2]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount /user/yuanyu/input/ /user/yuanyu/output
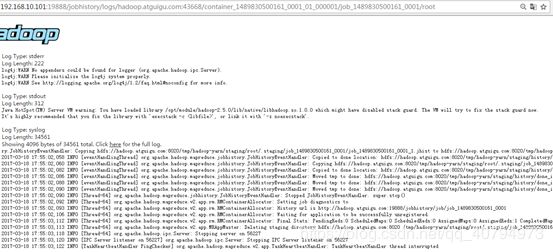
5. 查看日志
http://hadoop52:19888/jobhistory