Flink DataStream API 再理解
文章目录
- DataStream API 概览
- DataStream 的转换
- KeyedStream 的理解
- 数据分区调配算子
- 类型概览
- 示例
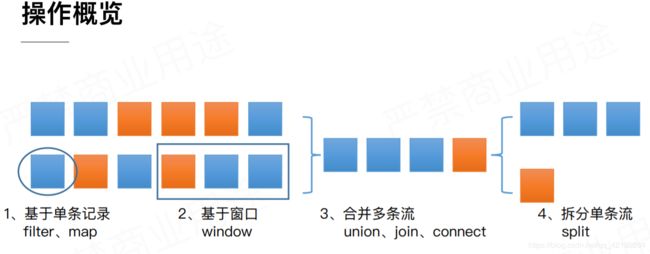
DataStream API 概览
DataStream 的转换
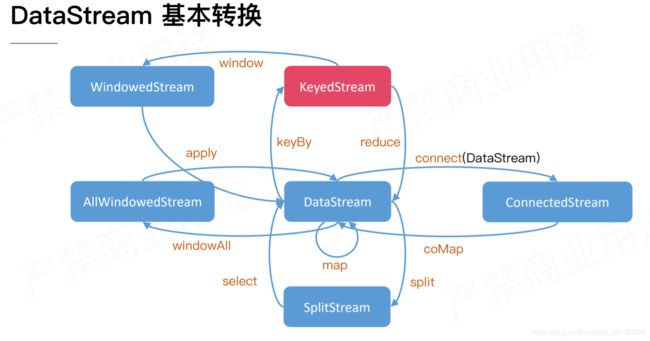
- DataStream 通过 split 给流中的数据打上标签成为 SplitStream,在使用 select 获取指定标签的流,又得到一个 DataStream。
- DataStream 通过 Connect 操作,在调用 streamA.connect(streamB)后可以得到一个专门的 ConnectedStream。ConnectedStream 支持的操作与普通的 DataStream 有所区别,由于它代表两个不同的流混合的结果,因此它允许用户对两个流中的记录分别指定不同的处理逻辑,然后它们的处理结果形成一个新的 DataStream 流。由于不同记录的处理是在同一个算子中进行的,因此它们在处理时可以方便的共享一些状态信息。上层的一些 Join 操作,在底层也是需要依赖于 Connect 操作来实现的。ConnectedStream 可以使用 coMap 方法对 ConnectedStreams 中的每一个流分别进行 map。
- DataStream 通过 windowAll 方法得到 AllWindowStream,将所有的 window 划分成为一个一个 mini batch,具体的切分逻辑可以由进行选择。当 mini batch 中所有记录都到达后,可以拿到 mini batch 中的所有记录,使用 apply 进行一些遍历或者累加操作,处理得到的结果就形成一个流,又得到了 DataStream。
- allWindow 操作
对于普通的 DataStream,必须使用 allWindow 操作,代表对整个流进行统一的 Window 处理,因此是不能使用多个算子实例进行同时计算的。针对这一问题,就需要首先使用 KeyBy 方法对记录按 Key 进行分组,然后才可以并行的对不同 Key 对应的记录进行单独的 Window 操作。KeyBy 操作是日常编程中最重要的操作之一。 - KeyBy 操作
DataStream 通过 keyBy方法得到 一个 KeyedStream,对于 KeyedStream 进行 reduce 聚合操作,每一 key 得到的聚合结果会形成一个 DataStream。 - KeyedStream 通过 window 方法得到一个 WindowedStream,对于每一个 Window 中的数据进行 apply 操作得到的结果又会形成一个 DataStream。
KeyedStream 的理解

以上是基本流上的 Window 操作与 KeyedStream 上的 Window 操对比。
KeyedStream 上的 Window 操作使采用多个实例并发处理成为了可能。
可以这样理解,KeyBy 和 Window 操作都是对数据进行分组,但是 KeyBy 是在水平分向对流进行切分,而 Window 是在垂直方式对流进行切分。
使用 KeyBy 进行数据切分之后,后续算子的每一个实例可以只处理特定 Key 集合对应的数据。除了处理本身外,Flink 中算子维护一部分状态(State),在KeyedStream 算子的状态也是可以分布式存储的。
由于 KeyBy 是一种确定的数据分配方式(下文将介绍其它分配方式),因此即使发生 Failover 作业重启,甚至发生了并发度的改变,Flink 都可以重新分配 Key 分组并保证处理某个 Key 的分组一定包含该 Key 的状态,从而保证一致性。
一般情况下,KeyBy 操作只有当 Key 的数量超过算子的并发实例数才可以较好的工作。由于同一个 Key 对应的所有数据都会发送到同一个实例上,因此如果Key 的数量比实例数量少时,就会导致部分实例收不到数据,从而导致计算能力不能充分发挥。
数据分区调配算子
以下是 Flink 内置的分区调节方式
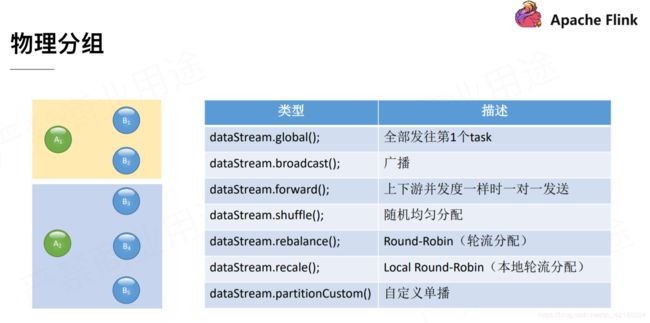
- global 每个上游算子只会将数据发往下游算子的第一个实例,会默认将并行度降为1,很少使用。
- broadcast 相当于上游算子将数据 copy 了多份,发往下游算子的每一个实例,一般用于较小的流的共享。
- forward 只适用于上游算子实例数与下游算子相同时,每个上游算子实例将记录发送给下游算子对应的实例。
- shuffle 上游算子随机打乱数据发往下游,起到负载均衡效果。
- rebalance 上游算子通过轮询的方式发送数据。
- recale 当上游和下游算子的实例数为 n 或 m 时,如果 n < m,则每个上游实例向ceil(m/n)或floor(m/n)个下游实例轮询发送数据;如果 n > m,则 floor(n/m) 或 ceil(n/m) 个上游实例向下游实例轮询发送数据。
- partitionCustom 当上述内置分配方式不满足需求时,用户还可以选择自定义分组方式。自定义数据分组的函数,目前返回值只能是下游的一个实例,所以是一对一传播,也叫单播。
类型概览

使用 scala 进行开发时,很多 TypeInformation 的方法都是通过隐式的参数传递进行的。再使用 java 调用 Scala 的一些方法时,需要进行 TypeInformation 的传递
同时,由于 java 中存在泛型擦除的情况,也需要显示的指定DataStream 中数据的类型以及 TypeInformation。
示例
public class GroupedProcessingTimeWindowSample {
// 模拟数据 商品类型 + 个数
private static class DataSource extends RichParallelSourceFunction<Tuple2<String, Integer>> {
private volatile boolean isRunning = true;
@Override
public void run(SourceContext<Tuple2<String, Integer>> ctx) throws Exception {
Random random = new Random();
while (isRunning) {
Thread.sleep((getRuntimeContext().getIndexOfThisSubtask() + 1) * 1000 * 5);
String key = "类别" + (char) ('A' + random.nextInt(3));
int value = random.nextInt(10) + 1;
System.out.println(String.format("Emits\t(%s, %d)", key, value));
ctx.collect(new Tuple2<>(key, value));
}
}
@Override
public void cancel() {
isRunning = false;
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStream<Tuple2<String, Integer>> ds = env.addSource(new DataSource());
KeyedStream<Tuple2<String, Integer>, Tuple> keyedStream = ds.keyBy(0);
keyedStream.sum(1).keyBy(new KeySelector<Tuple2<String, Integer>, Object>() {
@Override
public Object getKey(Tuple2<String, Integer> stringIntegerTuple2) throws Exception {
return "";
}
}).fold(new HashMap<String, Integer>(), new FoldFunction<Tuple2<String, Integer>, HashMap<String, Integer>>() {
@Override
public HashMap<String, Integer> fold(HashMap<String, Integer> accumulator, Tuple2<String, Integer> value) throws Exception {
accumulator.put(value.f0, value.f1);
return accumulator;
}
}).addSink(new SinkFunction<HashMap<String, Integer>>() {
@Override
public void invoke(HashMap<String, Integer> value, Context context) throws Exception {
// 每个类型的商品成交量
System.out.println(value);
// 商品成交总量
System.out.println(value.values().stream().mapToInt(v -> v).sum());
}
});
env.execute();
}
}
模拟的数据源,它继承自 RichParallelSourceFunction,它是可以有多个实例的 SourceFunction 的接口。
两个方法需要实现,一个是 Run 方法,Flink 在运行时对 Source 会直接调用该方法,该方法需要不断的输出数据,从而形成初始的流。在 Run 方法的实现中,会随机的产生商品类别和交易量的记录,然后通过 ctx#collect 方法进行发送。另一个是 Cancel 方法,当 Flink 需要 Cancel Source Task 的时候会调用该方法,使用一个 Volatile 类型的变量来标记和控制执行的状态。
创建 StreamExecutioniEnviroment 对象。创建对象调用的 getExecutionEnvironment 方法会自动判断所处的环境,从而创建合适的对象。例如,如果在 IDE 中直接右键运行,则会创建 LocalStreamExecutionEnvironment 对象;如果是在一个实际的环境中,则会创建 RemoteStreamExecutionEnvironment 对象。
第一个需求是统计每一个类型的成交量。
基于 Environment 对象,创建一个 Source,从而得到初始的<商品类型,成交量>流。然后,为了统计每种类别的成交量,使用 KeyBy 按 Tuple 的第 1 个字段(即商品类型)对输入流进行分组,并对每一个 Key 对应的记录的第 2 个字段(即成交量)进行求合。在底层,Sum 算子内部会使用 State 来维护每个Key(即商品类型)对应的成交量之和。当有新记录到达时,Sum 算子内部会更新所维护的成交量之和,并输出一条<商品类型,更新后的成交量>记录。
在 Sum 后添加一个 Sink 算子对不断更新的各类型成交量进行输出。
第二个需求是对所有类型的总成交量进行统计。
需要将所有记录输出到同一个节点的实例上。
通过 KeyBy 并且对所有记录返回同一个 Key,将所有记录分到同一个组中,从而可以全部发送到同一个实例上。
使用 Fold 方法来在算子中维护每种类型商品的成交量。虽然目前 Fold 方法被标记为 Deprecated,但是在 DataStream API 中暂时还没有能替代它的其它操作,所以仍然使用 Fold 方法。
Fold 方法接收一个初始值,然后当后续流中每条记录到达的时候,算子会调用所传递的 FoldFunction 对初始值进行更新,并发送更新后的值。
Fold 方法中传入一个初始的 HashMap来对各个类别的当前成交量进行维护,当有一条新的<商品类别,成交量>到达时,更新该 HashMap。这样在 Sink 中,收到的就是最新的商品类别和成交量的 HashMap。
例子主要是用来演示 DataStream API 的用法,实际上还会有更高效的写法,此外,更上层的 Table / SQL 还支持 Retraction 机制,可以更好的处理这种情况。
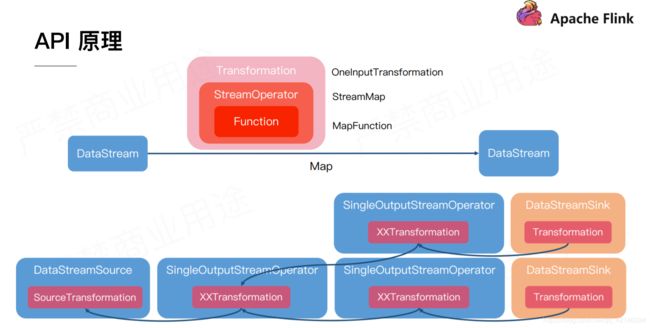
调用 DataStream#map 算法时,Flink 在底层会创建一个 Transformation 对象,这一对象就代表计算逻辑图中的节点。其中记录了传入的 MapFunction,也就是 UDF(User Define Function)。随着调用更多的方法,创建更多的 DataStream 对象,每个对象在内部都有一个 Transformation 对象,这些对象根据计算依赖关系组成一个图结构。后续 Flink 将对这个图结构进行进一步的转换,从而最终生成提交作业所需要的 JobGraph。
以上内容来自对 https://www.bilibili.com/video/av47970985 的学习总结。