数据挖掘招聘关键字分析
想以后从事数据挖掘行业,但是想看看这个行业对于工作能力有什么样的要求,一般招聘的时候都需要什么有什么样的基础能力,所以就打算先爬取智联上关于数据挖掘的岗位的招聘要求及其职责,然后根据结巴分词,提取关键字,看看哪些词汇出现的频率比较高,这样就知道数据挖掘这个行业一般对于从业有什么样的要求的。当然提取出来的关键字肯定是有一些无用的信息,这个需要我们去进一步的甄别。
首先是爬取智联招聘的数据挖掘岗位的招聘要求,初始页如下图。
请求到这个页面的信息后对每一条的详情页进行继续的请求,以获得招聘的要求,因为我们只关注与招聘的要求所以对于其他的信息并没有提取。因为最近都在使用jupyterlab所以代码写的比较随意:
‘’‘首先是导入相关的库,请求头’‘’
import requests
from bs4 import BeautifulSoup
import re
from redis import StrictRedis
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:47.0) Gecko/20100101 Firefox/47.0',
}
job_url = StrictRedis(host='localhost', port=6379, db=0)####redis数据库,用于存放详情页的url,和招聘要求
base_url = 'https://fe-api.zhaopin.com/c/i/sou'
s=requests.Session()
def get_data(page,kw):####请求头
page=page*30
data={
'start': page,
'pageSize': '90',
'cityId': 635,
'salary': '0,0',
'workExperience':'-1',
'education': '-1',
'companyType': '-1',
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': kw,
'kt': '3',
'at': '10b87f09cc11471ba97a8ec59068315b',
'rt': '25fa7d33ce874ed78a44c894e33182be',
' _v': '0.94232770',
'userCode': '719493971',
'x-zp-page-request-id': '5c873aecc7414997a182ee49cf59a08e-1548682114509-860029'
}
return data
##### kw=input('please input kw :')
kw='数据挖掘'####因为只关注于数据挖掘岗位,所以就把kw固定了,实际可以根据需要进行输入。
# page=1
def get_basePage(page,kw):
data=get_data(page,kw)
r=s.get(url=base_url,headers=header,params=data)
print(r.status_code)
# print(r.text)
r=r.json()
results=r.get('data').get('results')
# print(results)
for info in range(len(results)):####获取详情页的url
new_url=results[info].get('positionURL')
job_url.sadd('new_url',new_url) #### 详情页url加入redis中为new_url的集合中。
‘’‘遍历多个详情页’‘’
for i in range(10):
get_basePage(i,kw)
print('一共写入'+str(job_url.scard('new_url'))+'个url')
‘’‘将岗位要求加入redis的info列表中,这个耗时比较长,因为我跑的时候没有出现过错误所以也没有加入异常处理,实际上应当加入异常处理,以防有些详情页出现一点问题’‘’
import time
t1=time.time()
for i in range(job_url.llen('info')):
job_url.lpop('info')
print(job_url.llen('info'))
while job_url.scard('new_url'):####若new_url集合不空的话
new_url=job_url.spop('new_url')####拿出一个详情页的url
r=requests.get(url=new_url,headers=header)
soup=BeautifulSoup(r.text,'lxml')
many_info=soup.find('div',class_='job-detail')
for i in many_info.find_all('p'):
# print(i.text)
if i.text:
job_url.rpush('info',i.text)####将岗位要求加入redis的info列表中
print('加入第'+str(job_url.llen('info'))+'条信息成功')
t2=time.time()
print('time'+' '*3+':'+str(t2-t1))
已经成功的将数据挖掘招聘要求写入了redis的info列表中,下一步就是利用结巴分词将招聘要求的关键字提取出来,并统计关键字出现的频率,以分析什么技能才是数据挖掘岗位所需要的技能。
import jieba
import time
import re
t1=time.time()
dic={}####用于存储各个关键字出现的频率。
while job_url.llen('info'):####若info列表不空。则进入while循环
s=job_url.lpop('info') ####取出第一个信息
s=s.decode('utf-8')
info = jieba.cut(s,cut_all=False)####将招聘要求进行分词,提取关键字
for i in info:
if re.findall(r'[a-z,A-Z]{2,}',i):####如果是英文,就将其首部大写,其余小写(防止出现python/Python,明明是一个关键字却占两个键)
i=i.capitalize()
if i not in dic:####统计各个关键字出现的次数
dic[i]=1
else:
dic[i]+=1
t2=time.time()
print(t2-t1,len(dic))
字典dic的结果如下图。
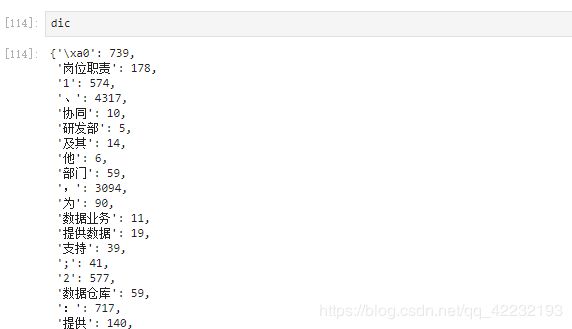
可以发现关键字里面有很多标点和特殊符号,我们可以将这些特殊符号和标点去掉,简单处理下这个字典,并且可以将其进行按照值排序。
import re
result=dict()
for k in dic:
if re.findall(r'[\u4e00-\u9fa5]{2,}|[a-z,A-Z]{2,}',k):####匹配出大于两个字的中文或者英文
result[k]=dic[k]
s=sorted( result.items(),key=lambda p:p[1],reverse=True)##按照出现的次数进行排序
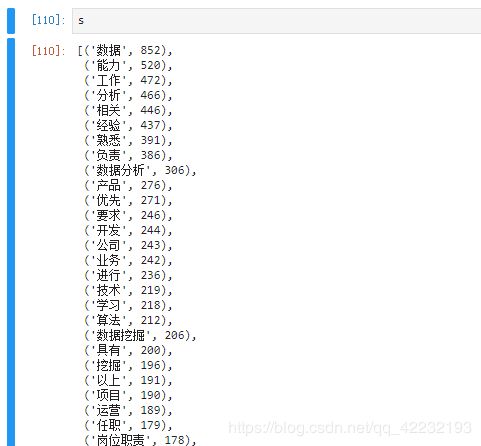
基本上来说已经找出数据挖掘要求的关键字了,但是这些好像都与工作要求无关,大部分是常用的词语,而不是工作要求的关键字,这只能自己观察找出与工作相关的关键字,看看哪些比较重要了,我们也可以保留英文的关键字,一般来说英文的关键字都是一些编程语言,或者是会使用的软件之类的。和工作要求比较贴近点。
import re
r1=dict()
for k in dic:
if re.findall('[a-z,A-Z]{2,}',k): ####匹配英文
r1[k]=dic[k]
r1=sorted( r1.items(),key=lambda p:p[1],reverse=True) ###排序
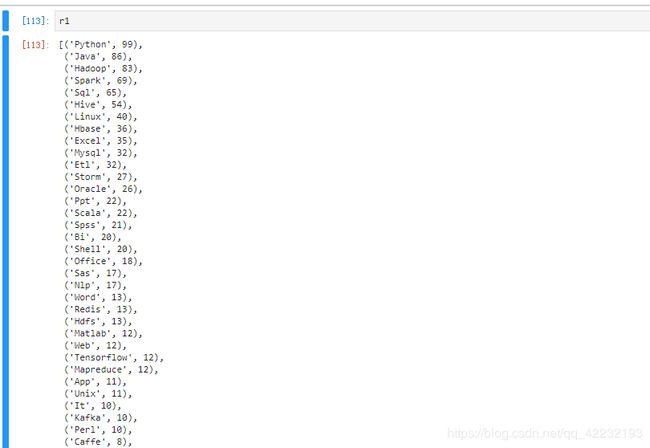
这样就可以看出来,在南京这边,智联的招聘数据挖掘的岗位的,公司普遍要求python,java,hadoop,spark,数据库这些。包括对中文那个高频词汇进行观察分析,可以看出数据挖掘这个岗位普遍来说都要求一些算法水平。大概也可以知道,在将机器学习的算法学的同时还需要对hadoop,spark等大数据处理平台的框架学习一下,对于数据库的一些知识也需要去了解。