基于Facenet与MTCNN的人脸识别
本文来自于中国科学院深圳先进技术研究院,目前发表在arXiv上,是2016年4月份的文章,算是比较新的文章。
论文地址:
https://kpzhang93.github.io/MTCNN_face_detection_alignment/
概述
相比于R-CNN系列通用检测方法,本文更加针对人脸检测这一专门的任务,速度和精度都有足够的提升。R-CNN,Fast R-CNN,FasterR-CNN这一系列的方法不是一篇博客能讲清楚的,有兴趣可以找相关论文阅读。类似于TCDCN,本文提出了一种Multi-task的人脸检测框架,将人脸检测和人脸特征点检测同时进行。论文使用3个CNN级联的方式,和Viola-Jones类似,实现了coarse-to-fine的算法结构。
框架
算法流程
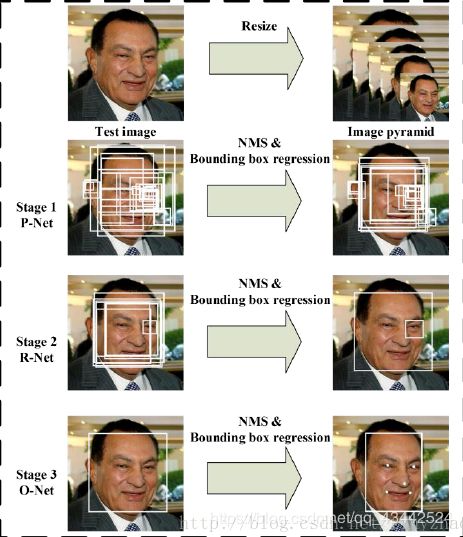
当给定一张照片的时候,将其缩放到不同尺度形成图像金字塔,以达到尺度不变。
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。全卷积网络和Faster R-CNN中的RPN一脉相承。
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置
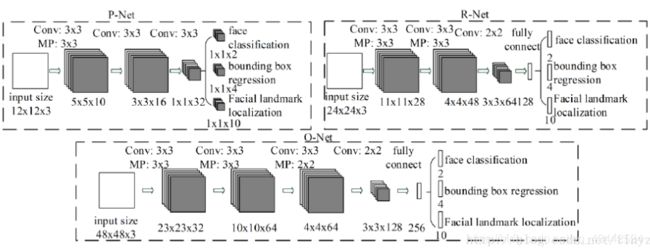
CNN结构
本文使用三个CNN,结构如图:
训练
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
(1)人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:
(2)Bounding box regression
这是一个回归问题,使用平方和损失函数:
(3)人脸特征点定位
这也是一个回归问题,目标是5个特征点与标定好的数据的平方和损失:
(4)多任务训练
不是每个sample都要使用这三种损失函数的,比如对于背景只需要计算,不需要计算别的损失,这样就需要引入一个指示值指示样本是否需要计算某一项损失。最终的训练目标函数是:
N是训练样本的数量。表示任务的重要性。在P-Net和R-Net中,在O-Net中,
(5)online hard sample mining
传统的难例处理方法是检测过一次以后,手动检测哪些困难的样本无法被分类,本文采用online hard sample mining的方法。具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
实验
本文主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
A、训练数据
本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
B、效果
本文的人脸检测和人脸特征点定位的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在Nvidia Titan达到99fps。
总结
本文使用一种级联的结构进行人脸检测和特征点检测,该方法速度快效果好,可以考虑在移动设备上使用。这种方法也是一种由粗到细的方法,和Viola-Jones的级联AdaBoost思路相似。
类似于Viola-Jones:1、如何选择待检测区域:图像金字塔+P-Net;2、如何提取目标特征:CNN;3、如何判断是不是指定目标:级联判断。
本次实验过程
使用MTCNN将人脸选择出来(分割人脸),然后使用facenet训练(欧氏距离算法
compare.py源码如下
"""Performs face alignment and calculates L2 distance between the embeddings of images."""
# MIT License
#
# Copyright (c) 2016 David Sandberg
#
# Permission is hereby granted, free of charge, to any person obtaining a copy
# of this software and associated documentation files (the "Software"), to deal
# in the Software without restriction, including without limitation the rights
# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
# copies of the Software, and to permit persons to whom the Software is
# furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in all
# copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
# SOFTWARE.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from scipy import misc
import tensorflow as tf
import numpy as np
import sys
import os
import copy
import argparse
import facenet
import align.detect_face
def main(args):
#使用MTCNN网络在原始图片中进行检测和对齐
images = load_and_align_data(args.image_files, args.image_size, args.margin, args.gpu_memory_fraction)
with tf.Graph().as_default():
with tf.Session() as sess:
# Load the facenet model
facenet.load_model(args.model)
# Get input and output tensors
# 输入图像占位符
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
#卷及网络最后输出的"特征"
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
#训练?
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
# Run forward pass to calculate embeddings
feed_dict = { images_placeholder: images, phase_train_placeholder:False }
emb = sess.run(embeddings, feed_dict=feed_dict)
nrof_images = len(args.image_files)
print('Images:')
for i in range(nrof_images):
print('%1d: %s' % (i, args.image_files[i]))
print('')
# Print distance matrix
print('Distance matrix')
print(' ', end='')
for i in range(nrof_images):
print(' %1d ' % i, end='')
print('')
for i in range(nrof_images):
print('%1d ' % i, end='')
for j in range(nrof_images):
#对特征计算两两之间的距离以得到人脸之间的相似度
dist = np.sqrt(np.sum(np.square(np.subtract(emb[i,:], emb[j,:]))))
print(' %1.4f ' % dist, end='')
print('')
def load_and_align_data(image_paths, image_size, margin, gpu_memory_fraction):
'''
返回经过MTCNN处理后的人脸图像集合 [n,160,160,3]
'''
minsize = 20 # minimum size of face
threshold = [ 0.6, 0.7, 0.7 ] # three steps's threshold
factor = 0.709 # scale factor
#创建P-Net,R-Net,O-Net网络,并加载参数
print('Creating networks and loading parameters')
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)
tmp_image_paths=copy.copy(image_paths)
img_list = []
#遍历测试图片
for image in tmp_image_paths:
img = misc.imread(os.path.expanduser(image), mode='RGB')
img_size = np.asarray(img.shape)[0:2]
#人脸检测 bounding_boxes:表示边界框 形状为[n,5] 5对应x1,y1,x2,y2,score
#_:人脸关键点坐标 形状为 [n,10]
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
if len(bounding_boxes) < 1:
image_paths.remove(image)
print("can't detect face, remove ", image)
continue
#对图像进行处理:扩展、裁切、缩放
det = np.squeeze(bounding_boxes[0,0:4])
bb = np.zeros(4, dtype=np.int32)
bb[0] = np.maximum(det[0]-margin/2, 0)
bb[1] = np.maximum(det[1]-margin/2, 0)
bb[2] = np.minimum(det[2]+margin/2, img_size[1])
bb[3] = np.minimum(det[3]+margin/2, img_size[0])
cropped = img[bb[1]:bb[3],bb[0]:bb[2],:]
aligned = misc.imresize(cropped, (image_size, image_size), interp='bilinear')
#归一化处理
prewhitened = facenet.prewhiten(aligned)
img_list.append(prewhitened)
#[n,160,160,3]
images = np.stack(img_list)
return images
def parse_arguments(argv):
'''
参数解析
'''
parser = argparse.ArgumentParser()
parser.add_argument('model', type=str,
help='Could be either a directory containing the meta_file and ckpt_file or a model protobuf (.pb) file')
parser.add_argument('image_files', type=str, nargs='+', help='Images to compare')
parser.add_argument('--image_size', type=int,
help='Image size (height, width) in pixels.', default=160)
parser.add_argument('--margin', type=int,
help='Margin for the crop around the bounding box (height, width) in pixels.', default=44)
parser.add_argument('--gpu_memory_fraction', type=float,
help='Upper bound on the amount of GPU memory that will be used by the process.', default=1.0)
return parser.parse_args(argv)
if __name__ == '__main__':
main(parse_arguments(sys.argv[1:]))
compare.py 该py文件作用是用自己的图像上应用已有模型来计算人脸之间的距离,即欧氏距离。
当欧氏距离小于1时,我们可以看做输入的两个照片为同一个人。
这三张照片分为起名为 img1.jpg,img2.jpg,img3.jpg。

在facenet目录下运行
python src/compare.py models/20180408-102900 src/img1.jpg src/img2.jpg src/img3.jpg
结果:
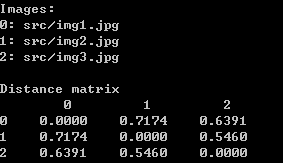
上面为官方的输入和输出
但是在该比赛中,比赛评委要求输出:
(输出)检索结果:要求参评单位将检索结果整理为CSV文件。
每一项用制表符'\t'分割,每一行具体格式如下:(所有输出以UTF-8无BOM格式编码)
查询图像ID\t底库中对应top1相似度的人脸ID\t相似度\t底库中对应top2相似度的人脸ID\t相似度\t…\t底库中对应top50相似度的人脸ID\t相似度
我尝试用compare.py文件的欧氏距离来计算出图片的相似度
开始修改源码
(过程很痛苦,网上没有修改compare.py文件的例子)
1.将矩阵输出为1行,即只取第一行矩阵。因为比赛只要求用QUERY _查询集唯一ID.jpg去DB库里比较所有图片
print('Distance matrix')
print(' ', end='')
for i in range(nrof_images):
print(' %1d ' % i, end='')
print('')
print('%1d ' % 0, end='')
list = []
for j in range(nrof_images):
dist = np.sqrt(np.sum(np.square(np.subtract(emb[0, :], emb[j, :])))) #计算欧式距离
print(' %1.4f ' % dist, end='')
list.append(dist)
print('')
print(list[1:])

2. 将图片id与矩阵里的数据组成字典,并且按照比赛要求排序
list_images=[] #图片路径的列表
print('Images:')
for i in range(nrof_images):
print('%1d: %s' % (i, image_files[i]))
list_images.append(image_files[i])#图片路径存入
print('')
print('Distance matrix')
print(' ', end='')
for i in range(nrof_images):
print(' %1d ' % i, end='')
print('')
print('%1d ' % 0, end='')
list_distance = []#欧式距离的列表
for j in range(nrof_images):
dist = np.sqrt(np.sum(np.square(np.subtract(emb[0, :], emb[j, :]))))
print(' %1.4f ' % dist, end='')
list_distance.append(dist)#欧氏距离存入
print('')
print(list_distance[1:])
images_distance=dict(zip(list_images[1:], list_distance[1:]))#用dict方法将list_images和list_distance存入字典
result=sorted(images_distance.items(),key=lambda item:item[1])#排序
print(result)
知识点:
sorted函数
sorted(iterable,key,reverse),sorted一共有iterable,key,reverse这三个参数;
其中iterable表示可以迭代的对象,例如可以是dict.items()、dict.keys()等
key是一个函数,用来选取参与比较的元素,reverse则是用来指定排序是倒序还是顺序,reverse=true则是倒序,
reverse=false时则是顺序,默认时reverse=false。
dict(zip)
zip是Python中的一个内建函数,能够用来组合多个序列类型的数据。它会把传入的所有序列中下标相同的元素组成一个个元组,以最短的序列为基准。
3.用QUERY里的照片去DB库找相似度前50的人脸照片,需要知道DB库中所有照片的路径
import glob
images_paths=glob.glob(r"./QUERY/raw/*/*.jpg")
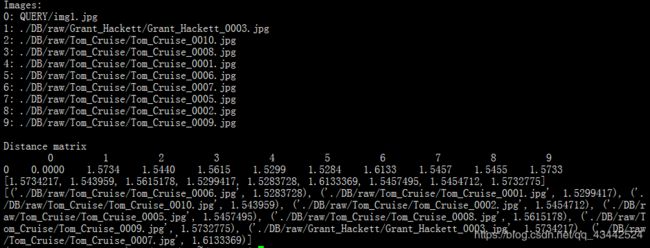
4.用for循环将QUERY _查询集唯一ID.jpg与DB库中的照片每10张就比一次
#set a b
a = 0
b = 9
while True:
image_files = image_QUERY + images_DB[a:b]
if b <= 20:
images = load_and_align_data(image_files, image_size, margin, gpu_memory_fraction)
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
feed_dict = {images_placeholder: images, phase_train_placeholder: False}
emb = sess.run(embeddings, feed_dict=feed_dict)
nrof_images = len(image_files)
list_images=[]
print('Images:')
for i in range(nrof_images):
print('%1d: %s' % (i, image_files[i]))
list_images.append(image_files[i])
print('')
print('Distance matrix')
print(' ', end='')
for i in range(nrof_images):
print(' %1d ' % i, end='')
print('')
print('%1d ' % 0, end='')
list_distance = []
for j in range(nrof_images):
dist = np.sqrt(np.sum(np.square(np.subtract(emb[0, :], emb[j, :]))))
print(' %1.4f ' % dist, end='')
list_distance.append(dist)
print('')
print(list_distance[1:])
images_distance=dict(zip(list_images[1:], list_distance[1:]))
result=sorted(images_distance.items(),key=lambda item:item[1])
print(result)
else:
break
a += 10
b += 10
5. 将数据写入列表,然后排出前50,并且写入csv文件
import csv
with open("result.csv","w") as csvfile:
writer = csv.writer(csvfile)
#先写入columns_name
writer.writerow(["查询图像ID","t底库中对应top1相似度的人脸ID","相似度","底库中对应top2相似度的人脸ID","相似度","底库中对应top3相似度的人脸ID","相似度","底库中对应top4相似度的人脸ID","相似度","底库中对应top5相似度的人脸ID","相似度","底库中对应top6相似度的人脸ID","相似度","底库中对应top7相似度的人脸ID","相似度","底库中对应top8相似度的人脸ID","相似度","底库中对应top9相似度的人脸ID","相似度","底库中对应top10相似度的人脸ID","相似度","底库中对应top11相似度的人脸ID","相似度","底库中对应top12相似度的人脸ID","相似度","底库中对应top13相似度的人脸ID","相似度","底库中对应top14相似度的人脸ID","相似度","底库中对应top15相似度的人脸ID","相似度","底库中对应top16相似度的人脸ID","相似度","底库中对应top17相似度的人脸ID","相似度","底库中对应top18相似度的人脸ID","相似度","底库中对应top19相似度的人脸ID","相似度","底库中对应top20相似度的人脸ID","相似度","底库中对应top21相似度的人脸ID","相似度","底库中对应top22相似度的人脸ID","相似度","底库中对应top23相似度的人脸ID","相似度","底库中对应top24相似度的人脸ID","相似度","底库中对应top25相似度的人脸ID","相似度","底库中对应top26相似度的人脸ID","相似度","底库中对应top27相似度的人脸ID","相似度","底库中对应top28相似度的人脸ID","相似度","底库中对应top29相似度的人脸ID","相似度","底库中对应top30相似度的人脸ID","相似度","底库中对应top31相似度的人脸ID","相似度","底库中对应top32相似度的人脸ID","相似度","底库中对应top33相似度的人脸ID","相似度","底库中对应top34相似度的人脸ID","相似度","底库中对应top35相似度的人脸ID","相似度","底库中对应top36相似度的人脸ID","相似度","底库中对应top37相似度的人脸ID","相似度","底库中对应top38相似度的人脸ID","相似度","底库中对应top39相似度的人脸ID","相似度","底库中对应top40相似度的人脸ID","相似度","底库中对应top41相似度的人脸ID","相似度","底库中对应top42相似度的人脸ID","相似度","底库中对应top43相似度的人脸ID","相似度","底库中对应top44相似度的人脸ID","相似度","底库中对应top45相似度的人脸ID","相似度","底库中对应top46相似度的人脸ID","相似度","底库中对应top47相似度的人脸ID","相似度","底库中对应top48相似度的人脸ID","相似度","底库中对应top49相似度的人脸ID","相似度","底库中对应top50相似度的人脸ID","相似度"])
#写入多行用writerows
writer.writerows([image_QUERY],result[50])
1)将QUERY的照片一个一个与DB里所有的照片进行比对
image_QUERY_path = glob.glob(r"./QUERY/*.jpg")
image_QUERY = image_QUERY_path
i=0
for image_QUERY in image_QUERY[i]:
...
i+=1
将列表里的元组用逗号分开,并且消除括号
list_result=','.join(list_result[0:50])
报错:

原因:
list包含数字,不能直接转化成字符串。
解决办法:','.join('%s' %result for result in list_result)
即遍历list的元素,把它转化成字符串
运行后报错:
TypeError: not all arguments converted during string formatting
原因: % 操作符只能直接用于字符串(‘123’),列表([1,2,3])、元组
最终版
将人脸对比写入csv文件中:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from scipy import misc
import tensorflow as tf
import numpy as np
import sys
import os
import copy
import argparse
import facenet
import align.detect_face
import glob
import csv
import codecs
def load_and_align_data(image_paths, image_size, margin, gpu_memory_fraction):
minsize = 20 # minimum size of face
threshold = [0.6, 0.7, 0.7] # three steps's threshold
factor = 0.709 # scale factor
print('Creating networks and loading parameters')
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)
tmp_image_paths = copy.copy(image_paths)
img_list = []
for image in tmp_image_paths:
img = misc.imread(os.path.expanduser(image), mode='RGB')
img_size = np.asarray(img.shape)[0:2]
bounding_boxes, _ = align.detect_face.detect_face(img, minsize, pnet, rnet, onet, threshold, factor)
if len(bounding_boxes) < 1:
image_paths.remove(image)
print("can't detect face, remove ", image)
continue
det = np.squeeze(bounding_boxes[0, 0:4])
bb = np.zeros(4, dtype=np.int32)
bb[0] = np.maximum(det[0] - margin / 2, 0)
bb[1] = np.maximum(det[1] - margin / 2, 0)
bb[2] = np.minimum(det[2] + margin / 2, img_size[1])
bb[3] = np.minimum(det[3] + margin / 2, img_size[0])
cropped = img[bb[1]:bb[3], bb[0]:bb[2], :]
aligned = misc.imresize(cropped, (image_size, image_size), interp='bilinear')
prewhitened = facenet.prewhiten(aligned)
img_list.append(prewhitened)
images = np.stack(img_list)
return images
def csv_result():
with open("result.csv", "w", newline='', encoding='utf-8-sig') as csvfile:
# first row
headers = ["查询图像ID", "底库中对应top1相似度的人脸ID", "相似度", "底库中对应top2相似度的人脸ID", "相似度", "底库中对应top3相似度的人脸ID", "相似度",
"底库中对应top4相似度的人脸ID", "相似度", "底库中对应top5相似度的人脸ID", "相似度", "底库中对应top6相似度的人脸ID", "相似度",
"底库中对应top7相似度的人脸ID", "相似度", "底库中对应top8相似度的人脸ID", "相似度", "底库中对应top9相似度的人脸ID", "相似度",
"底库中对应top10相似度的人脸ID", "相似度", "底库中对应top11相似度的人脸ID", "相似度", "底库中对应top12相似度的人脸ID", "相似度",
"底库中对应top13相似度的人脸ID", "相似度", "底库中对应top14相似度的人脸ID", "相似度", "底库中对应top15相似度的人脸ID", "相似度",
"底库中对应top16相似度的人脸ID", "相似度", "底库中对应top17相似度的人脸ID", "相似度", "底库中对应top18相似度的人脸ID", "相似度",
"底库中对应top19相似度的人脸ID", "相似度", "底库中对应top20相似度的人脸ID", "相似度", "底库中对应top21相似度的人脸ID", "相似度",
"底库中对应top22相似度的人脸ID", "相似度", "底库中对应top23相似度的人脸ID", "相似度", "底库中对应top24相似度的人脸ID", "相似度",
"底库中对应top25相似度的人脸ID", "相似度", "底库中对应top26相似度的人脸ID", "相似度", "底库中对应top27相似度的人脸ID", "相似度",
"底库中对应top28相似度的人脸ID", "相似度", "底库中对应top29相似度的人脸ID", "相似度", "底库中对应top30相似度的人脸ID", "相似度",
"底库中对应top31相似度的人脸ID", "相似度", "底库中对应top32相似度的人脸ID", "相似度", "底库中对应top33相似度的人脸ID", "相似度",
"底库中对应top34相似度的人脸ID", "相似度", "底库中对应top35相似度的人脸ID", "相似度", "底库中对应top36相似度的人脸ID", "相似度",
"底库中对应top37相似度的人脸ID", "相似度", "底库中对应top38相似度的人脸ID", "相似度", "底库中对应top39相似度的人脸ID", "相似度",
"底库中对应top40相似度的人脸ID", "相似度", "底库中对应top41相似度的人脸ID", "相似度", "底库中对应top42相似度的人脸ID", "相似度",
"底库中对应top43相似度的人脸ID", "相似度", "底库中对应top44相似度的人脸ID", "相似度", "底库中对应top45相似度的人脸ID", "相似度",
"底库中对应top46相似度的人脸ID", "相似度", "底库中对应top47相似度的人脸ID", "相似度", "底库中对应top48相似度的人脸ID", "相似度",
"底库中对应top49相似度的人脸ID", "相似度", "底库中对应top50相似度的人脸ID", "相似度"]
writer = csv.writer(csvfile) # 获取文件
writer.writerow(headers) # 写入一行记录
csvfile.close()
if __name__ == '__main__':
csv_result()
with tf.Graph().as_default():
with tf.Session() as sess:
# model
model = '/home/cuda/facenet/models/models'
facenet.load_model(model)
# images
image_size = 160
margin = 44
gpu_memory_fraction = 0.8
# DB and QUERY infors
images_DB_path = glob.glob(r"../DB/raw/*/*.jpg")
images_DB = images_DB_path
image_QUERY_path = glob.glob(r"../QUERY/*.jpg")
image_QUERY = image_QUERY_path
# image_QUERY range
image_QUERY_number = 0
for image_QUERY in image_QUERY[image_QUERY_number:]:
# set a b list_result
a = 0
b = 10
list_result = {}
while True:
image_files = [image_QUERY] + images_DB[a:b]
if b <= 100:
images = load_and_align_data(image_files, image_size, margin, gpu_memory_fraction)
images_placeholder = tf.get_default_graph().get_tensor_by_name("input:0")
embeddings = tf.get_default_graph().get_tensor_by_name("embeddings:0")
phase_train_placeholder = tf.get_default_graph().get_tensor_by_name("phase_train:0")
feed_dict = {images_placeholder: images, phase_train_placeholder: False}
emb = sess.run(embeddings, feed_dict=feed_dict)
nrof_images = len(image_files)
# list
list_images = []
list_distance = []
# append image_files
for i in range(nrof_images):
list_images.append(image_files[i])
# append list_distance
for j in range(nrof_images):
dist = np.sqrt(np.sum(np.square(np.subtract(emb[0, :], emb[j, :]))))
list_distance.append(dist)
images_distance = dict(zip(list_images[1:], list_distance[1:]))
# result=sorted(images_distance.items(),key=lambda item:item[1])
list_result = dict(list_result, **images_distance) # 字典相加
else:
break
a += 10
b += 10
print(list_result)
list_result = sorted(list_result.items(), key=lambda x: x[1]) # 排序
print(list_result[0:50])
print(list_result[i][1])
with open("result.csv", "a",newline='', encoding='utf-8-sig') as csvfile:
writer = csv.writer(csvfile) # 获取文件
list=[]
for i in range(50):
list.append(list_result[i][0])
list.append(list_result[i][1])
writer.writerow([image_QUERY]+list)
csvfile.close()
print("写入文件成功,第{}张照片比对结束".format(image_QUERY_number + 1))
image_QUERY_number += 1