孤读Paper——《Deep Snake for Real-Time Instance Segmentation》
《Deep Snake for Real-Time Instance Segmentation》
论文借鉴了snake算法,将snake算法做成了轮廓结构化特征学习的方法。DeepSnake是基于轮廓的两阶段实例分割的方法,是接在目标检测后面的方法。通过目标检测的定位来初始化建议轮廓,然后对建议轮廓进行变形,是其对目标更加贴合。论文使用了循环卷积取得了比通用的图卷积能更好的挖掘轮廓的周期图结构。
Key Words:Snake、Two-stage、Instance segmentation、 Circular convolution
作者:Sida Peng, Wen Jiang, Huaijin Pi, Xiuli Li, Hujun Bao, Xiaowei Zhou
CVPR 2020 oral
Subjects: Computer Vision and Pattern Recognition (cs.CV)
https://github.com/zju3dv/snake/
Agile Pioneer
介绍
DeepSnake可以加在目标检测后面来完成实例分割的,论文中加在了CenterNet的后面构成了新的实例分割模型。该模型可以实时的进行实例分割, 能达到32.3 fps对于512 × 512的图像在 GTX 1080ti GPU上,而且在Cityscapes、Kins和Sbd数据集上表现SOTA。
该模型能够达到上述效果的两个原因是:
- 该方法能够处理目标检测模型定位错误的问题所以只需要结合一个轻量级的目标检测模型即可。
- 基于contour的分割比基于pixel-based的分割具有更少的参数,而且没有Decoder过程。
为了增加算法的鲁棒性,DeepSnake算法把传统的对于contour坐标来手工定义能量的snake算法改为了Data-driven manner的算法即基于学习的方法。
该文章灵感来自于snake和Fast interactive object annotation with curve-gcn,看来多读论文还是很有好处,否则灵感何来,前两天看来一篇文章说不仅要读自己领域的paper,最好也涉猎一些其他领域的常识性东西,因为很多都是可以迁移过来的,深度学习就借鉴了很多物理领域的知识。
DeepSnake根据来自主干网络的图像特征获取轮廓作为输入,并预测对象边界的每个顶点的偏移量。
循环卷积

Pipeline

图3,基于轮廓建议的实例分割模型,(a)DeepSnake模型由三部分组成:一个主干网络,一个融合模块和一个预测的头模块。模型以轮廓作为输入,输出轮廓每个顶点的偏移量来对轮廓进行变形。(b)基于DeepSnake模型论文提出了一个两阶段的实例分割流程:初始化建议轮廓,轮廓变形。通过检测器得到的建议框得到一个菱形的轮廓,**然后通过DeepSnake模型对四个顶点进行变形得到包围对象的极端点。**然后通过极端点构建一个八边形,第一阶段结束。这个八边形就是初始化的轮廓,DeepSnake模型对其进行迭代的变形来贴合目标的边界。
网络结构
图3 展示了网络结构原理图的细节,DeepSnake网络由三部分组成:一个主干网络、一个融合模块、和一个预测头。其中主干网络由8个CirConv-Bn-ReLU组成,所有层直接都使用了残差跳跃连接的方式,CirConv就是循环卷积。融合模块的功能是融合contour上所有点的多尺度的信息。它合并了主干网络中所有层的特征,然后传入到1x1的卷积层中,再进行一次最大池化操作,这样融合的特征就和每个顶点的特征合并在了一起。预测头对于顶点特征采用了3个1x1的卷积层,然后映射到每个顶点的偏移量上输出。
第一阶段:建议contour的产生
给定一个目标检测框,从中提取四个点分别是上下左右四条边的中点,记为 { x i b b ∣ i = 1 , 2 , 3 , 4 } \{x^{bb}_i|i=1,2,3,4\} {xibb∣i=1,2,3,4},连接这四个点得到一个菱形轮廓,之后把这个菱形轮廓输入到DeepSnake中。
DeepSnake通过对菱形轮廓进行推理输出对应菱形轮廓4个顶点的4个偏移量,把通过菱形轮廓和偏移量计算得到的四个极端点记为 { x i e x ∣ i = 1 , 2 , 3 , 4 } \{x^{ex}_i|i=1,2,3,4\} {xiex∣i=1,2,3,4},这四个偏移量也就是 x i e x − x i b b x^{ex}_i - x^{bb}_i xiex−xibb。
实际上,为了提取更多的上下文信息,菱形轮廓是均匀上采样得到的40个点,然后DeepSnake相应的输出40个offset。损失函数只考虑 x i b b x^{bb}_i xibb的偏移量。(这块走的网络和第二阶段走的网络是一个吗?)
通过得到的四个极端点得到4个线段,连接线段的端点,得到一个八边形。具体来说,4个极端点对应一个水平框,对于每个极端点沿着相应水平框边的方向,向两边延伸为一个线段,线段的长度为相应边长的1/4,线段延伸如果遇到水平框端点就截断。然后连接四条线段的端点,就得到了八边形。
第二阶段:contour变形
先对八边形采样N个点,从极端点的顶点作为第一个点开始沿着边均匀采样,gt也是同样的采样方式。然利用图3所示的网络结构,通过循环卷积进行特征提取,然后通过1x1卷积映射到偏移量上。实验中论文设置N=128,能够均匀的覆盖绝大多数的物体形状了。
一次就能准确的回归偏移量是一件很有挑战的事,尤其是那种顶点距离对象较远的情况,为了解决这个问题 ,论文使用了可迭代的方法,具体来说,先基于当前的contour预测N个偏移量,然后通过该偏移量对contour进行第一轮变形作为新的contour,重复这个过程,论文实验中迭代的次数为三次。
contour也是目标空间扩展性的另外一种表示方法。通过对其进行变形是能够解决检测器的定位问题的。
处理多组件的对象
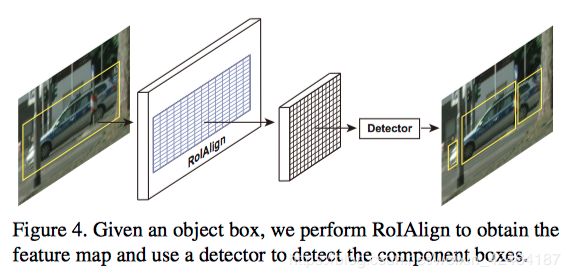
由于遮挡,许多实例不只是一个完全连接的组件,而是可能由遮挡部分切开的多个连接组件组成一个实例。而一个轮廓只能用于描述一个连接的组件,为了解决这个问题作者建议对目标框内的目标组件进行检测。具体来说就是使用一个检测框通过ROIAlign来提取特征映射图上的特征,然后对特征映射图加一个检测分支,来产生组件的框。我们的方法包含最终的整个目标形状通过对同一个目标框内的contour组件进行合并。
图卷积和循环卷积效果对比

上面的是图卷积得到的结果,下面的图是循环卷积得到的结果在Sbd数据集上。可以发现循环卷积两轮迭代的结果已经优于图卷积三轮迭代的结果了。
总结
-
该方法需要结合目标检测方法使用。
-
该方法能够在一定程度解决目标检测定位错误的问题。
-
和之前的深度学习的分割相比,该方法输入参数更少,且不需要Decoder过程。
-
和直接对边界点进行回归相比,效果好很多。
-
同过对snake算法进行改进,使其变为可学习的数据驱动的方法,鲁棒性更强。
-
论文对比了图卷积和循环卷积,在该任务上循环卷积的效果要优于图卷积。