SpringBoot高级——检索
一、简介
我们的应用经常需要添加检索功能,开源的 ElasticSearch 是目前全文搜索引擎的首选。他可以快速的存储、搜索和分析海量数据。Spring Boot通过整合Spring Data ElasticSearch为我们提供了非常便捷的检索功能支持。
Elasticsearch是一个分布式搜索服务,提供Restful API,底层基于Lucene,采用多shard(分片)的方式保证数据安全,并且提供自动resharding的功能,github、stackflow等大型的站点也采用ElasticSearch作为其搜索引擎。
二、ElasticSearch 安装
1、搜索:docker search elasticsearch
2、拉取:docker pull registry.docker-cn.com/library/elasticsearch
3、查看:docker images

4、启动:docker run
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name myES 5acf0e8da90b
ElasticSearch是用Java编写的,占用的内存比较大(占用2G),虚拟机的内存不足2G,因此需要进行限制,不然启动可能会报错。
9200是ElasticSearch对外暴露的端口,9300是ElasticSearch内部通信的端口。
5、测试:访问虚拟机的9200端口
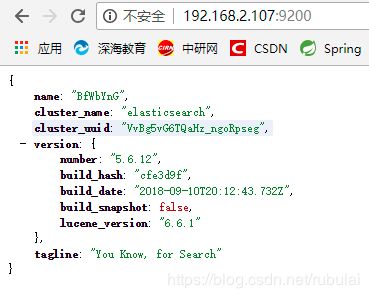
三、快速入门
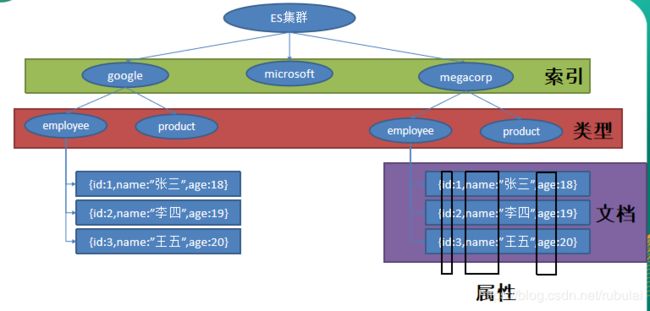
Elasticsearch 是面向文档的,意味着它存储整个对象或文档。Elasticsearch 不仅存储文档,而且索引每个文档的内容使之可以被检索。在 Elasticsearch 中,你对文档进行索引、检索、排序和过滤,而不是对行列数据。这是一种完全不同的思考数据的方式,也是 Elasticsearch 能支持复杂全文检索的原因。
Elasticsearch 使用 JavaScript Object Notation 或者 JSON 作为文档的序列化格式。JSON 序列化被大多数编程语言所支持,并且已经成为 NoSQL 领域的标准格式。 它简单、简洁、易于阅读。
存储数据到 Elasticsearch 的行为叫做索引(此处为动词——存储) ,但在索引一个文档之前,需要确定将文档存储在哪里。一个 Elasticsearch 集群可以包含多个索引(此处为名词——类似于Mysql中的库),相应的每个索引可以包含多个类型(类似于Mysql中的表)。这些不同的类型存储着多个文档(类似于Mysql中的记录),每个文档又有多个属性(类似于Mysql中的列)。
类比Mysql时的对应关系:
索引——库
类型——表
文档——记录
属性——列
1、存储数据:也叫索引数据
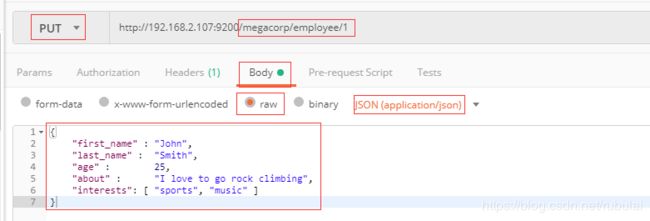
我们向ElasticSearch存储数据的时候只需要发送一个PUT类型的HTTP请求即可:
请求的地址规则为:/{索引名}/{类型名}/{唯一标识}
请求的请求体为:要发送的文档(JSON格式的数据)
示例:
PUT /megacorp/employee/1
{
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
表示将json数据文档存放在索引为megacorp、类型为employee的ElasticSearch中,唯一标识为1。类似于告诉Mysql将数据存在哪个库的哪张表,id是什么。
利用PostMan模拟如下:
响应报文如下:
{
"_index": "megacorp",
"_type": "employee",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
2、检索数据:
检索数据:发送一个HTTP的GET请求,请求的地址为/{索引名}/{类型名}/{唯一标识}
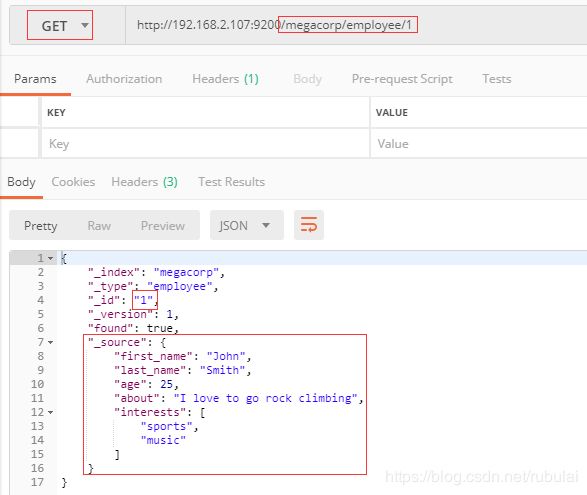
3、删除数据:删除数据使用DELETE方式的HTTP请求
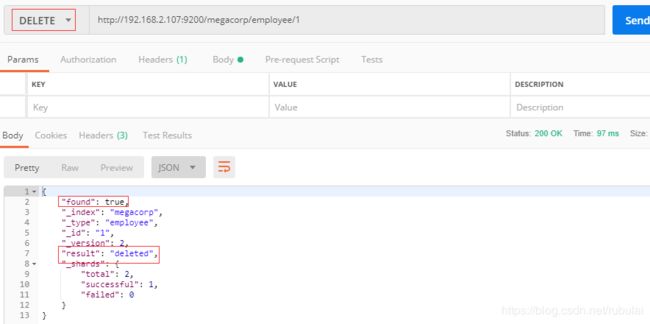
4、检查数据是否存在:检查数据在ElasticSearch中是否存在发送HEAD方式的HTTP请求:HEAD方式的请求的没有响应体,可根据响应码来判断,响应码为200表示有,为404表示没有
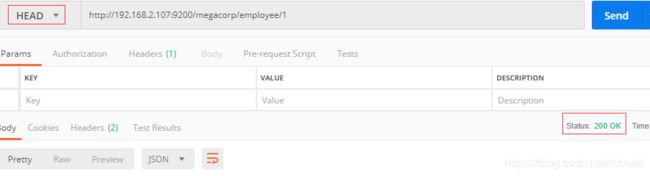
总结:将HTTP命令由PUT改为GET可以用来检索文档,同样的,可以使用DELETE命令来删除文档,以及使用HEAD指令来检查文档是否存在。如果想更新已存在的文档,只需再次 PUT。
更新文档示例:每更新一次版本会+1,且状态变为updated
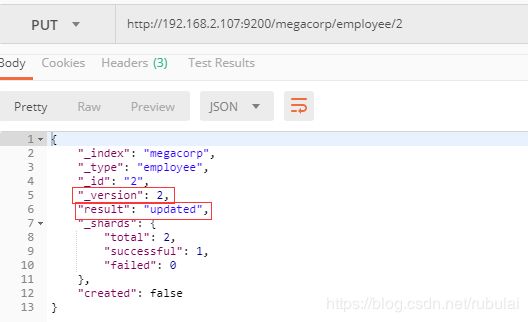
5、轻量搜索
查询所有:/{索引名}/{类型名}/_search
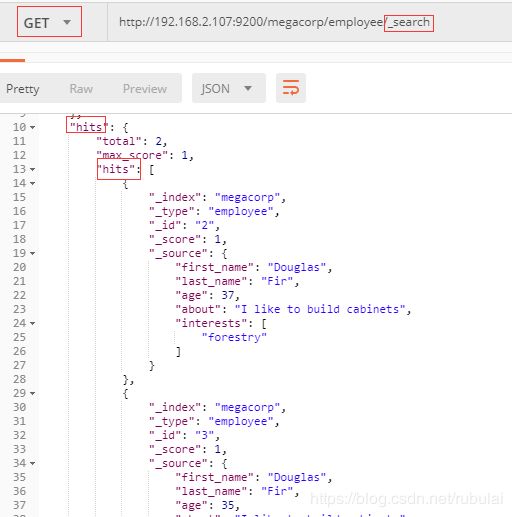
条件查询:在请求地址后加上?q=属性名:属性值(q表示查询字符串)
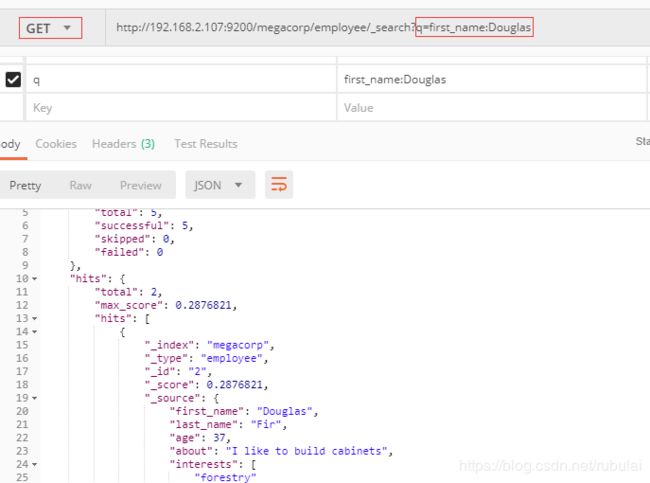
使用查询表达式检索:将JSON格式的查询表达式放在请求体中发给ElasticSearch
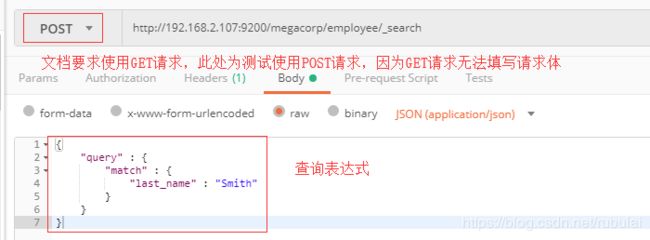
全文检索:发送的也是一个带查询表达式的HTTP请求,只不过ElasticSearch并不是向Mysql那样进行精准匹配或者模糊查询,而是只要存储的文档中有查询表达式中的某个单词就会进行匹配,但会将匹配的结果进行打分,分数越高越精准
例如检索条件为:
{
"query" : {
"match" : {
"about" : "rock climbing"
}
}
}
结果如下:
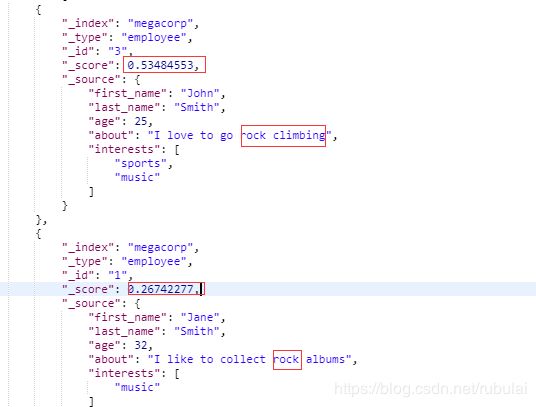
短语搜索:短语完整匹配,类似于Mysql中的模糊查询
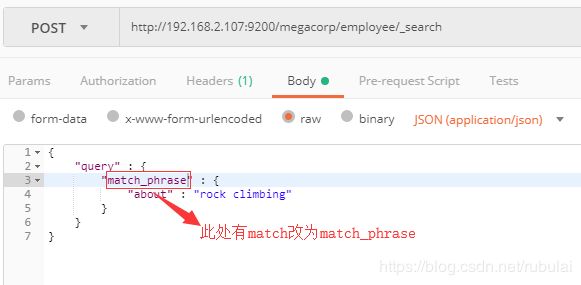
高亮检索:
{
"query" : {
"match_phrase" : {
"about" : "rock climbing"
}
},
"highlight": {
"fields" : {
"about" : {}
}
}
}
ElasticSearch中的检索其实就是把玩查询表达式。可以构建更复杂的查询表达式,参考:Elasticsearch 中文文档
四、整合ElasticSearch
1、新建工程,引入elasticsearch的启动器spring-boot-starter-data-elasticsearch:
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
2、SpringBoot默认支持两种方式整合elasticsearch的技术,一种是SpringData的方式,另一种是更流行的Jest
@Configuration
@ConditionalOnClass({JestClient.class})
@EnableConfigurationProperties({JestProperties.class})
@AutoConfigureAfter({GsonAutoConfiguration.class})
public class JestAutoConfiguration {
//...
}
3、原理:
①由于JestClient默认是不存在的,因此自动配置类JestAutoConfiguration默认不生效,要想使其生效需要引入,需要导入Jest的工具包:
<dependency>
<groupId>io.searchboxgroupId>
<artifactId>jestartifactId>
<version>5.3.3version>
dependency>
②SpringBoot的ElasticsearchAutoConfiguration为我们配置了Client,使用Client时需要配置节点信息clusterNodes和clusterName
③SpringBoot的ElasticsearchDataAutoConfiguration为我们配置了ElasticsearchTemplate
④SpringBoot的ElasticsearchRepositoriesAutoConfiguration中引入了ElasticsearchRepository,类似于JPA的方式,我们可以通过编写ElasticsearchRepository的子类来操作ElasticSearch
@NoRepositoryBean
public interface ElasticsearchRepository<T, ID extends Serializable> extends ElasticsearchCrudRepository<T, ID> {
<S extends T> S index(S var1);//索引数据
Iterable<T> search(QueryBuilder var1);//检索数据
Page<T> search(QueryBuilder var1, Pageable var2);
Page<T> search(SearchQuery var1);
Page<T> searchSimilar(T var1, String[] var2, Pageable var3);
void refresh();
Class<T> getEntityClass();
}
五、测试使用Jest的方式
1、引入Jest的依赖:
<dependencies>
<dependency>
<groupId>io.searchboxgroupId>
<artifactId>jestartifactId>
<version>5.3.3version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
dependencies>
2、在主配置文件中对elasticsearch进行属性配置:主要配置uris属性,指定ES的服务地址
# 默认值为http://localhost:9200
spring.elasticsearch.jest.uris=http://192.168.2.107:9200
3、构建Index对象并执行:
@Data
public class Article {
@JestId//指明这是ES文档的ID
private Integer id;
private String title;
private String author;
private String content;
}
@RunWith(SpringRunner.class)
@SpringBootTest
public class SpringbootElasticApplicationTests {
@Autowired
JestClient jestClient;
@Test
public void contextLoads() {
Article article = new Article();
article.setId(1);
article.setTitle("好消息");
article.setAuthor("张三");
article.setContent("Hello world");
//构建索引:意思为将该文档存储在索引为bdm,类型为news,id我们通过@JestId指定了,也可以在构建索引时指定
Index index = new Index.Builder(article).index("bdm").type("news").build();
//在构建索引时指定id
//Index index = new Index.Builder(article).index("bdm").type("news").id("1").build();
try {
//执行
jestClient.execute(index);
} catch (IOException e) {
e.printStackTrace();
}
}
}
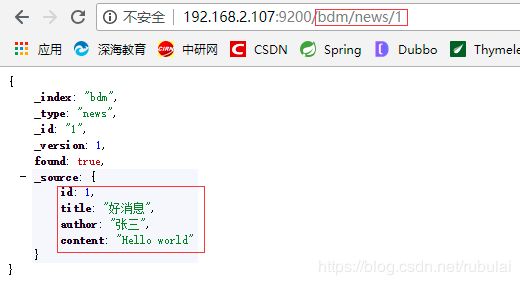
通过JestClient检索文档:通过返回的SearchResult可以获取到很多信息:比如匹配程度,匹配的数据条数等
public void search() {
//查询表达式
String json = "{\n" +
" \"query\" : {\n" +
" \"match\" : {\n" +
" \"content\" : \"hello\"\n" +
" }\n" +
" }\n" +
"}";
//构建查询:指定索引和类型,相当于指明库和表
Search build = new Search.Builder(json).addIndex("bdm").addType("news").build();
try {
//执行检索
SearchResult result = jestClient.execute(build);
//通过SearchResult可以获取到很多信息:比如匹配程度,匹配的数据条数等
System.out.println(result.getJsonString());
} catch (IOException e) {
e.printStackTrace();
}
}
结果:
{
"took": 22,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.25811607,
"hits": [{
"_index": "bdm",
"_type": "news",
"_id": "1",
"_score": 0.25811607,
"_source": {
"id": 1,
"title": "好消息",
"author": "张三",
"content": "Hello world"
}
}]
}
}
Jest的更多使用,可参考文档:Jest使用文档
六、整合SpringDataElasticSearch的方式
1、环境准备
①引入依赖:可以和Jest一起使用
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-data-elasticsearchartifactId>
dependency>
<dependency>
<groupId>io.searchboxgroupId>
<artifactId>jestartifactId>
<version>5.3.3version>
dependency>
dependencies>
②配置属性:
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=192.168.2.107:9300
cluster-name属性的值可以通过访问elastic服务的9200端口获得,cluster-nodes属性的值是elastic服务的ip:9300(端口固定为9300,因为docker启动时映射的端口为9300)
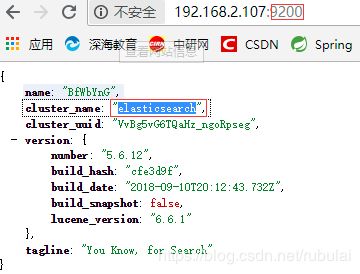
配置好这些之后启动项目可能会报错,说启动超时:


这是版本不适配导致的,可参考:SpringDataElasticSearch和ElasticSearch的版本对应关系和使用方法:
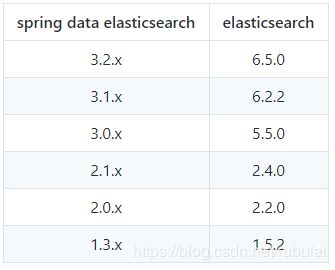
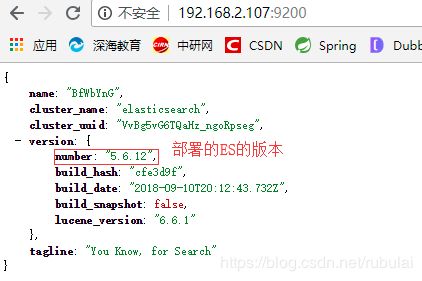

出现版本适配问题时,有两种解决方案:目的都是使SpringBootElasticSearch的版本和我们部署的ElasticSearch的版本适配
①升级SpringBoot版本
②安装和SpringBoot版本对应的ES
此处我们采用方案②,重新部署一个2.4.6版本的ES服务:
docker pull registry.docker-cn.com/library/elasticsearch:2.4.6
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9201:9200 -p 9301:9300 --name myElastic 5e9d896dc62c
由于虚拟机的9200端口和9300端口被高版本的ES占用了,此处使用虚拟机的9201和9301端口来映射容器的9200和9300端口
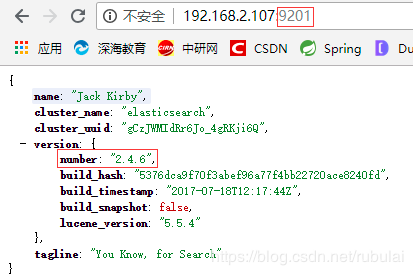
修改下配置:再次启动就不会报错了
#Jest的方式依然连接高版本ES
spring.elasticsearch.jest.uris=http://192.168.2.107:9200
spring.data.elasticsearch.cluster-name=elasticsearch
spring.data.elasticsearch.cluster-nodes=192.168.2.107:9301 #端口改为9301
以上为环境准备,下面开始集成使用,集成的时候有多种方式:
2、编写ElasticsearchRepository的子接口
①编写实体类:使用@Document注解的属性指明索引和类型
@Data
@Document(indexName = "bdm", type = "book")
public class Book {
private Integer id;
private String bookName;
private String author;
}
②编写一个继承于ElasticsearchRepository接口的接口,注意泛型:前者表是操作类型,后者表示主键的数据类型
public interface BookRepository extends ElasticsearchRepository<Book, Integer> {
}
③测试使用:
@Autowired
BookRepository bookRepository;
@Test
public void indexBook(){
Book book = new Book();
book.setId(1);
book.setBookName("西游记");
book.setAuthor("吴承恩");
bookRepository.index(book);
}
结果:
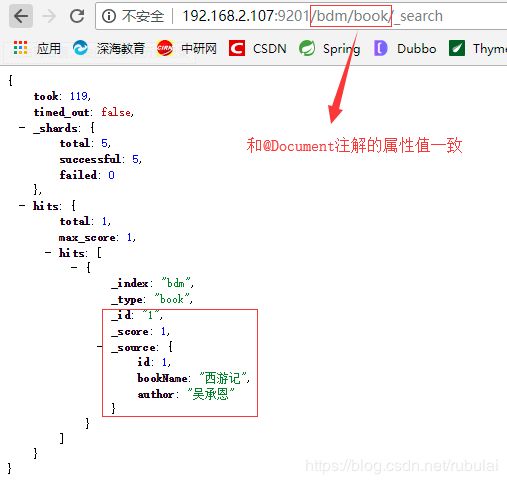
我们也可以在接口中自定义一些方法(无需我们实现,SpringData已为我们实现),但是这些方法有一些约定,具体可看官方文档:自定义查询方法的命名
public interface BookRepository extends ElasticsearchRepository<Book, Integer> {
public List<Book> findByBookNameLike(String bookName);
}
也支持自定义查询:
public interface BookRepository extends ElasticsearchRepository<Book, String> {
@Query("{"bool" : {"must" : {"field" : {"name" : "?0"}}}}")
Page<Book> findByName(String name,Pageable pageable);
}
3、使用ElasticsearchTemplate
private ElasticsearchTemplate elasticsearchTemplate;
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(matchAllQuery())
.withFilter(boolFilter().must(termFilter("id", documentId)))
.build();
Page<SampleEntity> sampleEntities =
elasticsearchTemplate.queryForPage(searchQuery,SampleEntity.class);