python量化交易:Joinquant_量化交易基础【七】:获取典型常用数据
本文是量化交易零基础入门教程的第七篇。
摘要
- 聚宽数据
- 获取指数成分股
- 获取股票行情数据
- 获取股票财务数据
- 自测与自学
聚宽数据
- 在聚宽数据这个页面可以看到聚宽平台集成好的各大类数据,如下图,点击可以查看详情与用法。
- 但实际上可能有些数据要在API文档里才比较容易能找到,比如龙虎榜数据等。这时用ctrl+f进行网页搜索可以快速搜索需要的数据。

- 接下来会介绍几种常用数据的取用方法,这些取用方法比较典型,掌握后能覆盖基本的数据需求以及较容易的学会使用其他数据。
获取指数成分股
- 以免有人不知道指数成分股是什么,简单说明下。为了衡量股市中某一大类股票整体的涨跌情况,通常会用这一类的股票加权平均编制出一个指数,而这些股票则叫做该指数的成分股,一般指数的成分股选取会变动。比如上证指数是用所有上交所的股票编制而成,可以衡量上交所股票整体的涨跌情况,有的股票退市了也就会被剔除成分股。比较常见的指数有上证指数、深证综指、创业板指、沪深300指数、中证500指数、上证50指数等。可以在数据-指数数据-指数列表中找到聚宽支持的指数及其指数代码。同样要善用ctrl+f进行搜索。
- 获取指数成分股需要用到的API为get_index_stocks
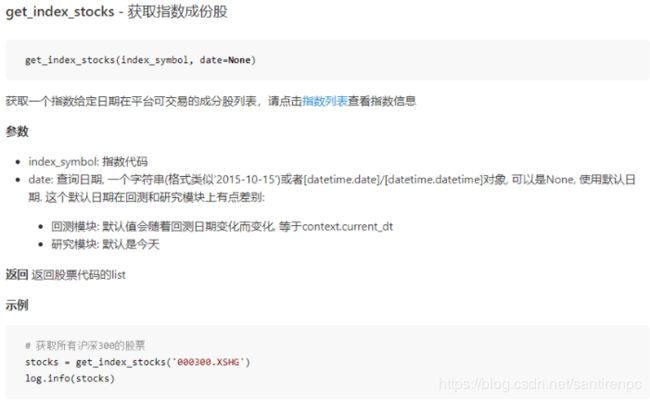
-
之前讲过怎么看API文档以及函数参数的含义,现在应该能直接看说明使用了。补充一个更详细点的例子应该就会用了。
# 获取20180301时,上证50指数(000016.XSHG)成分股 t=get_index_stocks("000016.XSHG","2018-03-01") print(t[0]) print(t) # 打印日志如下。股票代码在list中被打印出来前面会带有的u代表是对字符串进行unicode编码(略复杂,不懂没关系),只是显示效果,单独打印t[0]时就没有u。 # 600000.XSHG # [u'600000.XSHG', u'600016.XSHG', u'600019.XSHG', u'600028.XSHG', u'600029.XSHG', u'600030.XSHG', u'600036.XSHG', u'600048.XSHG', u'600050.XSHG', u'600104.XSHG', u'600111.XSHG', u'600309.XSHG', u'600340.XSHG', u'600518.XSHG', u'600519.XSHG', u'600547.XSHG', u'600606.XSHG', u'600837.XSHG', u'600887.XSHG', u'600919.XSHG', u'600958.XSHG', u'600999.XSHG', u'601006.XSHG', u'601088.XSHG', u'601166.XSHG', u'601169.XSHG', u'601186.XSHG', u'601211.XSHG', u'601229.XSHG', u'601288.XSHG', u'601318.XSHG', u'601328.XSHG', u'601336.XSHG', u'601390.XSHG', u'601398.XSHG', u'601601.XSHG', u'601628.XSHG', u'601668.XSHG', u'601669.XSHG', u'601688.XSHG', u'601766.XSHG', u'601800.XSHG', u'601818.XSHG', u'601857.XSHG', u'601878.XSHG', u'601881.XSHG', u'601985.XSHG', u'601988.XSHG', u'601989.XSHG', u'603993.XSHG']
获取股票行情数据
- 此处的股票行情数据指SecurityUnitData里面的所有基本属性,以下列举类常用字段,详情请看文档。
- open: 时间段开始时价格
- close: 时间段结束时价格
- low: 最低价
- high: 最高价
- volume: 成交的股票数量
- money: 成交的金额
- factor: 前复权因子
- avg: 这段时间的平均价
- pre_close: 前一个单位时间结束时的价格
- paused: 这只股票是否停牌,是则为1,否则为0
-
history
- API文档:history
- 可以同时获得多个股票的数据,但只能获得相同的一个数据字段。如获得 平安银行,建设银行,农业银行这3只股票,前3天的交易额。
- 默认不跳过不交易日期,由skip_paused参数控制。
- df参数控制返回结果的数据类型,默认是True代表dataframe类型,稍后我们会讲到,当df为False时就为之前讲过的dict类型。
- fq参数控制复权方式,往往可以不管它直接用默认的前复权即可。复权的含义不难,解释略麻烦,建议自行搜索学习下。
-
接下来介绍的API还会有skip_paused、df、fq参数,就不再提了。这三个参数新手可以以后慢慢了解,现在不管也没关系,如果不想用dataframe,会把df参数调成False(或0)就行。
# 例子 df=True,返回dataframe类型 w=history(count=3, field='money', security_list=['000001.XSHE','000002.XSHE']) print(w) # 结果如下: # 000001.XSHE 000002.XSHE # 2016-08-29 5.322954e+08 1.796321e+09 # 2016-08-30 5.618541e+08 2.072873e+09 # 2016-08-31 4.638758e+08 5.748581e+09 # 例子 df=False,返回dict类型 w=history(count=3, field='money', security_list=['000001.XSHE','000002.XSHE'],df=False) print(w) # 结果如下: # {'000001.XSHE': array([ 5.32295362e+08, 5.61854066e+08, 4.63875763e+08]), '000002.XSHE': array([ 1.79632055e+09, 2.07287325e+09, 5.74858107e+09])}
-
attribute_history
- API文档:attribute_history
- 只能获取单独一个股票的数据,但可以同时获得多个字段的数据。如获得 平安银行这一只股票,前3天的交易额,交易量,最高价,最低价等。
-
默认跳过不交易日期,由skip_paused参数控制。
# 例子 w=attribute_history(security='000001.XSHE',count=3, fields=['money','high']) print(w) # 结果如下: # money high # 2016-08-29 5.322954e+08 9.31 # 2016-08-30 5.618541e+08 9.33 # 2016-08-31 4.638758e+08 9.36
-
Pandas.DataFrame
-
返回的财务数据是DataFrame类型,这是一种二维表结构的功能强大的数据类型,常用于数据处理与分析。我们以刚刚的例子介绍下dataframe最常用的获取数据的方法。
# 一个dataframe类型的例子 w=attribute_history(security='000001.XSHE',count=3, fields=['money','high','open']) print(w) # 结果如下: # money high open # 2016-08-30 5.618541e+08 9.33 9.29 # 2016-08-31 4.638758e+08 9.36 9.32 # 2016-09-01 4.548486e+08 9.38 9.35 -
dataframe是一个二维表,包括index(行标签、索引)、columns(列标签)、values(值)三个部分。取用方法如下,注意三个部分的数据类型不是固定的,因此功能很灵活但也更难使用。
# 获取index print(w.index) # 结果如下,是datatimeindex类型,很特殊,不常用,建议新手回避。 # DatetimeIndex(['2016-08-30', '2016-08-31', '2016-09-01'], dtype='datetime64[ns]', freq=None, tz=None) # 获取columns print(w.columns) # 结果如下,是index类型 # Index([u'money', u'high', u'open'], dtype='object') # 可以用list()将其转成list print(list(w.columns)) # 结果如下 # ['money', 'high', 'open'] # 获取values print(w.values) # 结果如下,是一个嵌套的list # [[ 5.61854066e+08 9.33000000e+00 9.29000000e+00] # [ 4.63875763e+08 9.36000000e+00 9.32000000e+00] # [ 4.54848634e+08 9.38000000e+00 9.35000000e+00]] -
选择dataframe某几列
# 按标签获取某几列.loc[:,[列标签名,...]] print(w.loc[:,['open','high']]) # 结果如下 # open high # 2016-08-29 9.28 9.31 # 2016-08-30 9.29 9.33 # 2016-08-31 9.32 9.36 # 按位置获取某几列.iloc[:,[位置,...]],位置的含义是第几个,从0开始。下文同。 print(w.iloc[:,[0,2]]) # 结果如下 # money open # 2016-08-29 5.322954e+08 9.28 # 2016-08-30 5.618541e+08 9.29 # 2016-08-31 4.638758e+08 9.32 # : 即冒号,可以代表全部,iloc或loc都可以。 print(w.iloc[:,:]) # 结果如下 # money high open # 2016-08-29 5.322954e+08 9.31 9.28 # 2016-08-30 5.618541e+08 9.33 9.29 # 2016-08-31 4.638758e+08 9.36 9.32 # 选择后的数据依然是dataframe类型,用.values可以获取数据。对后文的行情况也成立。 print(w.iloc[:,[0,2]].values) # 结果如下,是个list # [[ 5.61854066e+08 9.29000000e+00] # [ 4.63875763e+08 9.32000000e+00] # [ 4.54848634e+08 9.35000000e+00]] -
选择dataframe某几行
# 按标签获取某几行.loc[[行标签名,...],:] print(w.loc[['2016-08-29','2016-08-31'],:]) # 此处这样写会报错,原因是当前的行标签类型是DatetimeIndex,不是字符串,所以使用标签名时要注意数据类型。而时间类型的数据处理往往非常麻烦,因此行或列标签名是日期情况下建议新手回避,改使用位置获取。 # 按位置获取某几行.iloc[[位置,...],:] print(w.iloc[[0,2],:]) # 结果如下 # money high open # 2016-08-29 5.322954e+08 9.31 9.28 # 2016-08-31 4.638758e+08 9.36 9.32 # : 即冒号,行情况下依然可以代表全部 print(w.loc[:,:]) # 结果如下 # money high open # 2016-08-29 5.322954e+08 9.31 9.28 # 2016-08-30 5.618541e+08 9.33 9.29 # 2016-08-31 4.638758e+08 9.36 9.32 -
dataframe 行列转置
# 行列转置的意思就是按对角线行列反转,方法是.T print(w.T) # 结果如下 # 2016-08-29 2016-08-30 2016-08-31 # money 5.322954e+08 5.618541e+08 4.638758e+08 # high 9.310000e+00 9.330000e+00 9.360000e+00 # open 9.280000e+00 9.290000e+00 9.320000e+00 - 回过头来解释下pandas的含义,pandas是一个模块或者叫库,可以让我们直接利用其中包含的已经设计好的函数或数据类型,加快我们的工作效率。pandas主要功能是数据处理与分析,其中dataframe就是属于pandas的,是原生的python语言没有的。随着深入的学习,你会遇到其他的功能模块,一般来说要使用一个模块是要用一行代码加载导入的,但pandas聚宽系统已经自动加载了,不必额外写代码导入了。
-
获取股票财务数据
-
股票财务数据这里是指发股票的公司发布的财务报表中的数据。可以在聚宽数据-股票财务数据查看数据详情。
-
财务报表简称财报,是用来向股东汇报企业经营情况的,上市公司必须按季度公布财报,一年有四季所以财报依发布次序一季报、半年报(也称中报)、三季报、年报,而具体的发布日期在一定期限内即可并非固定,年报要求年度结束四个月内披露,半年报是上半年结束后两个月内,一季报与三季报是季度结束后一个月内。特别的是像总市值、市盈率这种跟股价挂钩的市值数据是每天更新的。
- 获取股票财务数据需要用到的API为get_fundamentals。这个语句的用法较为复杂,下文对文档进行补充说明,文档还是要看的。
- 未来函数是什么?
- 我们做回测去验证策略时,其实是用历史数据去模拟当时的市场从而得知策略在历史上表现如何,但是如果策略利用了历史当时无法得到的信息,往往就会造成回测结果极大失真,这时我们会说这个策略有未来函数。
- 举一个典型的有未来函数的策略:每天买明天涨停的股票。 事实上你是不能知道明天哪个股票涨停的,所以现实中是不能实现的,但是我们做回测是用的历史数据,所以我们其实是能实现用2012年的数据对这个买明日涨停股的策略做回测的,毕竟现在已经过了2012年,2012年每天哪个股票会涨都是已经知道的了。这样的有未来函数的回测结果肯定是没价值的,因为现实中不能实现,尽管回测结果有时特别喜人。
- date与statDate的问题
- 传入date时,查询指定日期date 所能看到的最近的数据。 回测时不填则默认值会为回测日期的前一天(模拟现实,避免未来函数)。date参数的要求为格式类似'2015-01-15'的字符串,datetime类型的时间数据也是可以的,不过略复杂不展开。
- 传入statDate时, 查询 statDate 指定的季度(例如'2015q1'、 '2013q4'的字符串)或者年份(如'2015'、'2013'的字符串)的财务数据。这种用法需要注意的地方比较多,请注意文档中提到的问题。
- date和statDate参数只能同时传入其中一个。当 date 和 statDate 都不传入时,相当于使用 date 参数,date 的默认值会为回测日期的前一天。文档中提到的回测模块就是指我们编写策略的功能模块,研究模块我们之后会介绍。因此,为方便在回测中使用,date 和 statDate 都不传入。
- 单季度与报告期。
- 之前讲过,财务数据按季度发布,一般财经网站上提供的财务数据是默认按报告期提供的,即每季度统计的周期跨度分别为第一季度、前两个季度、前三个季度、前四个季度(全年)。
- 而聚宽考虑到量化分析,提供的财务数据全是单季度的,即每季度统计的周期跨度分别为第一季度、第二季度、第三季度、第四季度。
- 因此,当你发现聚宽财务数据比财经网站的财务数据差的很多时,很可能是单季度与报告期的差别造成的。
-
query_object参数以及快速上手模板
-
query_object参数是要求传入一个Query对象用于描述所需的数据,这个东西展开讲相当于一门小的编程语言,麻烦而不必要,这里提供一个快速上手的模板用来产生query_object参数,多数情况下往里套就可以了,例子如下,建议对比文档里的例子看看。
# 快速上手模板 # query(表.字段).filter(筛选条件).order_by(排序方法).limit(数量上限) #比较长的话可以分行写 -
表和字段可以在财务数据文档查看,如下。表和字段可以写多个用逗号隔开,只写表名不写字段代表选择该表的所有字段。注意看含义与单位。
-
筛选条件跟讲if判断时用的条件是一样的,多个条件用逗号隔开代表与(and)的关系。特别的是要用复杂的与或非的逻辑关系时,在此处and、or、not是不能用的,要对应的改用&(与)、|(或)、~(非)。
- 排序的写法比较简单,就是要作为排序标准的字段后面加.desc()即由大到小,或.asc()即由小到大。
-
数量上限可以自己设置,代表最多返回的数据条数。不过系统强制限制每次最多返回10000条,就算你自己在此处限制比10000多也没用。
# 例子 # 获取 市值表.股票代码,资产负债表.未分配利润 q=query(valuation.code,balance.retained_profit # 筛选 市值大于100 并且 市盈率小于10 ).filter(valuation.market_cap>100,valuation.pe_ratio < 10 # 排序 按市值从大到小排 ).order_by(valuation.market_cap.desc() # 数量 上限10条数据 ).limit(10) w=get_fundamentals(q) print(w) # 结果如下: # code retained_profit # 0 601398.XSHG 8.566400e+11 # 1 601939.XSHG 7.400340e+11 # 2 601288.XSHG 4.644490e+11 # 3 601988.XSHG 5.267460e+11 # 4 600036.XSHG 1.816520e+11 # 5 601328.XSHG 9.208500e+10 # 6 600000.XSHG 1.037620e+11 # 7 600016.XSHG 1.277570e+11 # 8 601166.XSHG 1.573490e+11 # 9 601998.XSHG 1.298680e+11
-
自学与自测
- 实践下文中例子。
- 浏览聚宽数据中包括的数据,试着取用下。
- 建议大致浏览下pandas.dataframe 专题使用指南,学有余力可以细致学习下。
- 获取任一股票最近5个交易日最高价的平均价。
- 生成一个list,list中为上证指数成分股中流通市值最大的5个股票的股票代码。