理解linux cpu load - 什么时候应该担心了
Updated: 2018/10/17 图片被CSDN 吃了 重新上传
译文原文: http://blog.scoutapp.com/articles/2009/07/31/understanding-load-averages
你可能已经很熟悉linux的平均load. 平均load是3个数 (可以用uptime或者top命令查看), 他们看着像下面这样:
load average: 0.09, 0.05, 0.01
大多数人对这些数都有一个模糊的概念:三个数分别代表了一个随着更长时间上的一个平均值(1分钟, 5分钟, 15分钟). 并且值越小越好. 越大的数可能就表明有问题或者已经高负载了. 但是这个阈值是多少? 什么是状态好的/坏的负载?什么时候我们需要关心这个平均值, 什么时候我们需要赶紧起来修复它?
首先 需要一点背景来了解什么是load/负载, 我们将从最简单的case来看看:一个单核单处理器的机器.
#流量
一个单核单处理器的CPU就像一个只有一条车道.假想下你是一个桥梁的工作人员, 有时候,车辆太多了,所以有车辆都排成一条线通过.你想让后面的人知道这条路上的流量到底是多少.一个相当好的指标就是:某一时间有多少车在等待. 如果没有车在等待, 那么来的车就知道,他们可以直接通过. 如果有车在排队了,司机就知道他们要被延迟通过了.
所以,对收费员而言,用什么数字来表示呢?
-
0.00 表示桥上上没有任何流量. 事实上0.0 到1.00 之间的值都表示这条公路上没有任何阻塞,大家都可以及时通过.
- 1.00 表示这座桥刚好达到它的最大容量. 目前,工作都很正常,但是如果车更多一点,事情就开始变慢了. -
超过1.00表示已经有排队等待了 怎么看? 2.00 表示该有2条车道, 一条车道在桥上, 另外一条车道在排队等待. 3.00表示该有3条车道, 一条车道在桥上, 另外两条车道在排队等待. 诸如此类的.
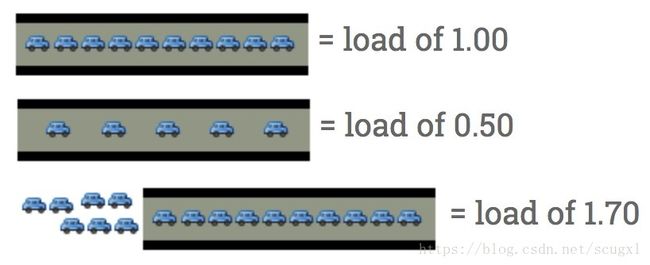
这就是CPU load的基本含义. 这里的汽车就是进程 (用cpu的时间片, 也就是通过这座桥 或者排队等待使用cpu). unix使用类似的概念runqueue length来表示:当前有多个正在等待的进程和正在执行的进程的个数总和.
作为桥梁操作员, 你肯定不希望你的汽车/进程有任何的等待. 所以你的cpu load理想情况下应该是低于1. 偶尔一下的超过1也是可以的. 但是如果一直超过1, 我们就需要担心了.
#那么理想的cpu load是1.00?
好吧, 并不是. 问题是当load是1.00的时候, 已经没有任何空闲空间了. 实际上, 许多系统管理员有一个经验值:0.70:
- 经验1:需要看下 - 0.70. 如果你的load一直大于0.70, 那么需要抽时间调查下了.
- 经验2:修复它 - 1.00. 如果你的load一直大于1.0,那么赶紧找到问题原因并修复它,否则你就会在半夜睡觉的时候被叫起来,那就不爽了.
- 经验3:啊 凌晨3点,WTF- 5.00. 如果你的load一直大于5.00,你可能真的遇上事了.你的任务可能被挂起了,或者放慢了.并且这会不可预期的在半夜或者你开会的时候发生. 必须解决它.
#多核处理器怎么说? load说是3.00 但是没啥问题呀!
对于一个4核处理器的系统, 一个load为3.00的时候 依然很健康.
在一个多处理器系统上, load是相对处理器核数来说的. 100%的使用率在一个单核处理器系统上load是1.00, 在一个双核处理器上就是2.00, 在一个4核处理器上就是4.00.
回到我们前面的桥梁操作员的例子中, 1.00 表示只有一条道有流量. 在一个只有一条道的桥梁上,意味着它被填满了. 在一个两条道的桥梁上, 1.00 表示只有50%的容量 - 只有一条道满了,另外一条道完全可以继续通行(空的).
CPU 也是如此: load 1.00表示: 在单核CPU上100%的占用率, 在一个双核CPU 上, load 2.00代表100%的占用率.
#多核心(multi-core)vs多处理器(multi-processor)
关于这个话题, 我们来看下多核心和多处器的区别. 对性能而言, 一个双核处理器和2个单核处理器是差不多的. 当然也有些微妙的关系比如(cache, 进程在多个处理器上的切换). 除开这些,对于load而言, 核心的个数才是最重要, 有多少个物理处理器不重要,也不管他们如何分布.
也就是下面的两个经验:
- 核心个数=最大load: 在一个多核系统中, 你的load不应该超过的你的核心数.
- 核心就是核心: 这些核心在CPU中是如何分布的是不关心的. 2个4核处理器=4个双核处理器=1个八核处理器. 这都是8个核心.
译者注:
多核心 multi-core 一个处理器上可能有多个core 核心. 多个核心可以在一个processor上
多处理器 multi-processor 1个处理器是一个晶元(die) 多个处理器就有多个晶元
参考mac上的配置:

一个晶圆:
#拿回家
让我们来看下uptime的输出:
~ $ uptime
23:05 up 14 days, 6:08, 7 users, load averages: 0.65 0.42 0.36
这是一个双核的CPU, 所以我们还有很多空间, 根本不需要担心直到它到了1.7或者更高.
那么这三个数字都是啥意思? 0.65是最近1分钟的平均load, 0.42是最近5分钟的平均load, 0.36是最近15分钟的平均负载.
那么这里有2个问题:
1.我该用哪个值? 1分钟, 5分钟还是15分钟?
对于这些数字而言, 你应该关注5分钟或者15分钟的值, 因为CPU 偶尔有spike是比较正常的, 而且一般都会正常工作. 如果最近15分钟这个值都很高, 那就真的要调查下了.
2.既然核心数这么重要, 我怎么知道我的系统有多少个核心?
在linux上可以:
cat /proc/cpuinfo
译者注:
比如我的一个虚拟机:
[root@centosvm64 ~]# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 70
model name : Intel(R) Core(TM) i7-4770HQ CPU @ 2.20GHz
stepping : 1
cpu MHz : 2194.969
cache size : 6144 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts xtopology tsc_reliable nonstop_tsc aperfmperf unfair_spinlock pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm ida arat epb xsaveopt pln pts dts fsgsbase bmi1 avx2 smep bmi2 invpcid
bogomips : 4389.93
clflush size : 64
cache_alignment : 64
address sizes : 42 bits physical, 48 bits virtual
power management:
processor : 1
vendor_id : GenuineIntel
cpu family : 6
model : 70
model name : Intel(R) Core(TM) i7-4770HQ CPU @ 2.20GHz
stepping : 1
cpu MHz : 2194.969
cache size : 6144 KB
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts mmx fxsr sse sse2 ss syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts xtopology tsc_reliable nonstop_tsc aperfmperf unfair_spinlock pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm ida arat epb xsaveopt pln pts dts fsgsbase bmi1 avx2 smep bmi2 invpcid
bogomips : 4389.93
clflush size : 64
cache_alignment : 64
address sizes : 42 bits physical, 48 bits virtual
power management: