Google的锁,才是分布式锁?
早年Google的四大基础设施,分别是GFS, MapReduce, BigTable, Chubby, 前三个比较有名,今天来说说最后一个,Chubby。
Chubby是什么?
Chubby是早年Google四大基础设施之一,提供粗粒度的分布式锁服务。
Chubby的使用者不需要关注复杂的同步协议,而是通过已经封装好的客户端直接调用锁服务,通过分布式锁,满足各种分布式场景下的一致性需求。
Chubby有什么典型的业务场景?
Chubby具有广泛的应用场景,例如:
(1)GFS选主;
(2)BigTable中的表锁;
Chubby的内核本质是什么?
Chubby本质上是一个分布式文件系统,存储大量小文件。每个文件就代表一个锁,并且可以保存一些应用层面的小规模数据。
用户通过打开、关闭、读取文件来获取共享锁或者独占锁;并通过反向通知机制,向用户发送更新信息。
Chubby系统设计目标是什么?
Chubby系统设计之初,主要想满足以下几点:
(1)粗粒度的锁服务;
(2)高可用、高可靠;
(3)可直接存储服务信息,而无需另建服务;
(4)高扩展性;
Chubby的整体架构是怎么样的?
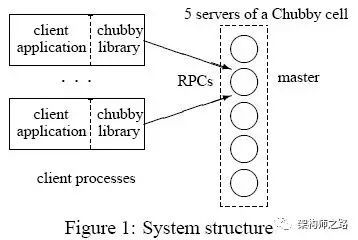
Chubby架构并不复杂,如上图所示,其核心是这两个重要组件:
(1)Chubby客户端:以库的方式提供,可以通过相应API接口,申请锁服务,获取数据信息,同时保持与服务端的连接;
(2)Chubby服务端:服务端集群,一般由5个节点组成(至少3个节点),其中一台主节点(master),维护与客户端的所有通信;其他节点不断和主节点通信,获取用户操作;
在系统实现时,还使用了以下特性:
(1)客户端缓存,以减少对主节点的访问;
(2)反向通知机制,锁变化时,会反向通知客户端;
Chubby的实现关键点有哪些?
其一,文件系统。
Chubby文件系统类似于简单的unix文件系统。
文件系统由许多Node组成,每个Node代表一个文件,或者一个目录。文件系统使用Berkeley DB来保存每个Node的数据。文件系统提供的API很少:创建文件系统、文件操作、目录操作等简易操作。
其二,基于ICE的通信机制。
Chubby基于ICE的通信机制,核心就是异步,部分组件负责发送,部分组件负责接收。
其三,客户端与主节点通信。
(1)使用长连接,连接有效期内,锁服务、客户端缓存数据均一直有效;
(2)定时双向keepalive;
(3)出错回调;
下面将说明正常、客户端租约过期、主节点租约过期、主节点出错等情况。
(1)正常情况
keepalive会周期性发送,它有两方面功能:
一来,延长租约有效期,携带事件信息告诉客户端更新。
二来,执行回调,例如文件内容修改、子节点增删改、主节点出错等。
(2)客户端租约过期
客户端没有收到主节点的keepalive,租约随之过期,将会进入一个“危险状态”。由于此时不能确定主节点是否已经终止,客户端必须主动让本地缓存失效,同时,进入一个寻找新的主节点的阶段。
这个阶段中,客户端会轮询服务集群,访问非主节点的其他节点,当客户端收到一个肯定的答复时,他会向新的主节点发送keepalive信息,告之自己处于“危险状态”,并和新的主节点建立会话,然后把本地缓存中的信息刷新。
(3)主节点租约过期
主节点一段时间没有收到客户端的keepalive,会进入一段等待期,此期间内客户端仍没有响应,则主节点认为客户端失效。失效后,主节点会把客户端获得的锁,打开的临时文件清理掉,并通知各副本节点,以保持一致性。
(4)主服务器出错
主节点出错,需要内部进行重新选举,各副本节点只响应客户端的读取命令,而忽略写命令。
其四,服务器集群间的一致性操作。
这里需要解决的问题是,当主节点收到客户端请求时(主要是写),如何将操作同步到其他服务器节点,以保证数据的一致性。
(1)节点数目
一般来说,节点数为5,至少要是3。
(2)关于复制
收到客户端请求时,主节点会将请求复制到所有成员,并在消息中添加最新被提交的请求序号。副本节点收到这个请求后,获取主节点处被提交的请求序号,然后执行这个序列之前的所有请求,并把其记录到内存的日志里。
各副本节点会向主节点回复消息,主节点收到半数以上的消息(集群包含5个节点时,至少要收到3个节点),才能够进行确认,执行请求,并返回客户端。
画外音:半数以上确认,才认为成功。
如果某个副本节点出现暂时的故障,没有收到部分消息也没关系,副本节点重新启动后,主动从主节点处获得已执行的,自己却还没有完成的日志,并进行执行。
画外音:像不像MySQL的binlog。
最终,所有成员都会获得一致性的数据,正常情况下,至少有3个节点包含一致,且最新的数据。
最后,举几个Chubby使用场景的例子。
例子一,集群选主
(1)集群中每个节点都试图创建/打开同一个文件,并在该文件中记录自己的服务信息,任何时刻,肯定只有一个服务器能够获得该文件的控制权;
(2)首先创建该文件的节点成为主,并写入自己的信息;
(3)后续打开该文件的节点成为从,并读取主的信息;
画外音:是不是很巧妙?
例子二,进程监控
(1)各个进程都把自己的状态写入指定目录下的临时文件里;
(2)监控进程通过阅读该目录下的文件信息来获得进程状态;
(3)各个进程随时有可能死亡,因此指定目录的数据状态会发生变化;
(4)通过事件机制通知监控进程,读取相关内容,获取最新状态,达到监控目的;
总结
Google Chubby提供粗粒度锁服务,它的本质是一个松耦合分布式文件系统。开发者不需要关注复杂的同步协议,直接调用库来取得锁服务,并保证了数据的一致性。
最后要说明的是,最终Chubby系统代码共13700多行,其中ICE自动生成6400行,手动编写约8000行。
这就是Google牛逼的地方:强大的工程能力,快速稳定的实现,快速解决各种业务问题。
近期被罚了,原创功能被关了,申诉也失败了:
《账号被罚了,有点不开心》
《账号被罚了,申诉的结果出来了,果然》