Linux服务器下给当前用户安装自己的CUDA|简记
CUDA10.0安装
服务器是团队或者项目组的,因此cuda还是自己的好用!!!
1:官网下载地址
cat /proc/version (Linux查看当前操作系统版本信息)

2:进行安装
先把安装包《cuda_10.0.130_410.48_linux.run》的属性进行修改为可执行;
chmod 755 cuda_10.0.130_410.48_linux.run
不要使用 sudo 进行安装
sh cuda_10.0.130_410.48_linux.run
过程如下,按空格读完协议,进行如下图的操作:
备注:这里没有安装新的驱动,是因为:
1: root 用户 安装的 驱动 能够 支持当前 CUDA10.0的运行;
2: 驱动的更新安装,需要 root 权限 (也就是说 一台 Linux 服务器 只能 安装 一个 驱动),团队的服务器,我没有 权限 去 更新 服务器的 显卡驱动;
3:如果服务器本身 驱动版本 高 能够 同时 支持 CUDA10 和 CUDA9 ,那么我们这里安装的 CUDA10.0,后面运行程序便是 可行的;
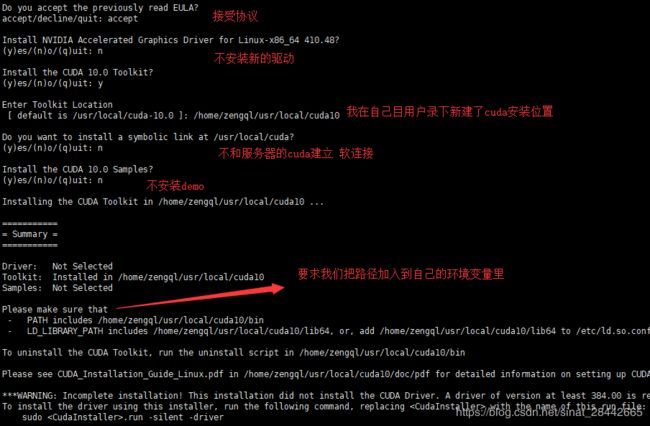
3:环境变量的配置
cd /home/zengql
vim .bashrc
在最下方添加刚刚安装cuda的路径:
---
export PATH="/home/zengql/usr/local/cuda10/bin:$PATH"
export LD_LIBRARY_PATH="/home/zengql/usr/local/cuda10/lib64:$LD_LIBRARY_PATH"
---
保存之后,使配置生效:
source .bashrc
命令行输入 nvcc -V 查看cuda版本,效果如下:
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2018 NVIDIA Corporation
Built on Sat_Aug_25_21:08:01_CDT_2018
Cuda compilation tools, release 10.0, V10.0.130
说明 cuda10.0此次安装OK,已经不再使用服务器公共的cuda了。
配置自己的cudnn,这里配置的cudnn版本为:7.6.0
TensorFlow1.2~2.1各GPU版本与CUDA对应版本|简记
1:官网下载
这个下载需要邮箱注册和登录,容易忘记密码,就很烦有没有。。。
2:解压 cudnn
从Nvidia官网上下载下来的cudnn for linux的文件格式是.solitairetheme8,想要解压的话需要先转成tgz格式再解压(这个操作我也被惊到了):
cp cudnn-10.0-linux-x64-v7.6.0.64.solitairetheme8 cudnn-10.0-linux-x64-v7.6.0.64.tgz
tar -zxvf cudnn-10.0-linux-x64-v7.6.0.64.tgz
3: 安装
cp cuda/include/cudnn.h /home/zengql/usr/local/cuda10/include/
cp cuda/lib64/libcudnn.s* /home/zengql/usr/local/cuda10/lib64/
chmod 755 /home/zengql/usr/local/cuda10/include/cudnn.h
查看cudnn版本
cat /home/zengql/usr/local/cuda10/include/cudnn.h | grep CUDNN_MAJOR -A 2
我得到的正确输出如下:

我上面安装的cuda10.0 和 cudnn 7.6.0 是因为代码训练TensorFlow-GPU 版本为2.0 ,各位需要根据自己的需求情况来安装相应的 cuda 和 cudnn版本,版本不匹配会导致很多麻烦呐。
TensorFlow2.0-GPU 训练走起。。。