Scrapy中设置User-Agent(本文主要目的是学习如何为爬虫程序的每次请求随机分配User-Agent)
初学scrapy中,以为在settings.py中的USER_AGENT = 'xxxx' 设置随机的User-Agent(UA)可以达到每次请求都有不同的UA的效果.>>>>>其实不是,这只能在每次运行时随机调用其中的一个UA.(看图)
(在spider中打印User-Agent看看究竟)


(可以看到每次运行scrapy时会有不同的User-Agent)

(改改代码,设置一下回调,看看能不能打印出两条User-Agent)
![]()
(打印结果很明确了,两次都是同一个User-Agent,原因如下)
因为,运行(scrapy crawl xxxx)时,scrapy引擎传达发送请求的任务给scheduler调度器,此时scheduler将请求入队列,发给Downloader下载器,取获取目标页面的response响应,Downloader得到response响应,给spider,spider处理后,给pipeline或者再给scrapy,传给scheduler,再请求入队列,给Downloader...
整个过程中没有再去查看settings文件中的设置...
所以这种设置只能在每次运行scrapy时,scrapy crawl xxxx时才会随机获得UA...
但是整个过程中,请求每次入队列,再给Downloader时,都会经过一个中间件,DownloaderMiddlewares,这个就很有用了,在这个中间件里面设置随机的UA,就可以在每次请求经过中间件时获得随机的UA...

那么来写一下中间件.
第一种方法较为简单直接:
在中间件中middlewares.py中写类,初始化UA列表,方法process_request(self,request,spider)中写随机获得UA
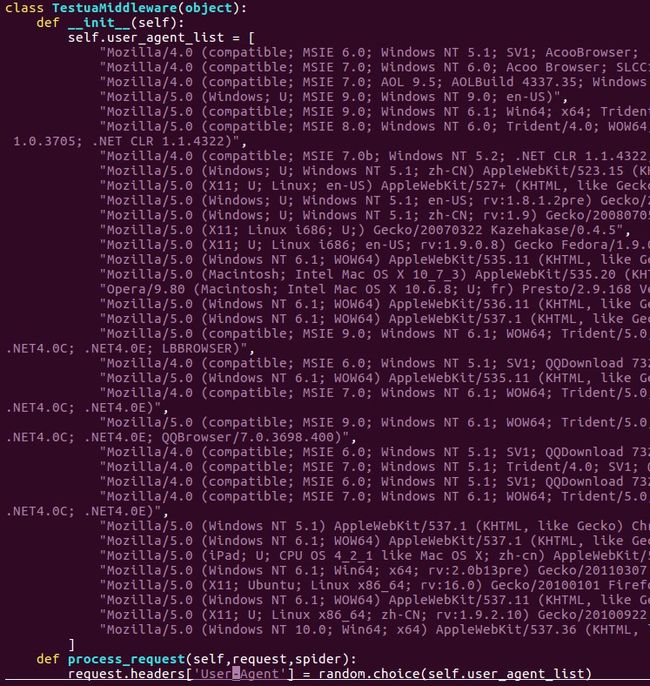
requset.headers['User-Agent'] = 随机的UA
这个可以覆盖scrapy自己默认的UA,就是下图中的UA,很明显是scrapy自己的UA>>>>同时也可以起到每次请求经过中间件时,被process_request方法捕获到,并给request写入一个随机的UA
![]()
在settings中启用下载中间件

还是第一步写的代码,这里再运行一下,试试,(可以先注释掉settings中USER_AGENT那一行)>>>
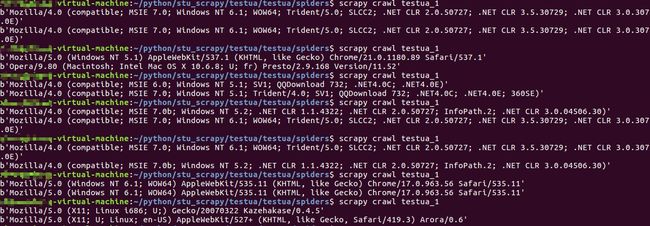
这里spider一共就发起两次请求,可以发现,每次请求的UA会有所变化,当然也有相同的时候,可以再增多UA列表的内容,使每次请求的UA更为随机...
还可以这样写中间件...
就是继承scrapy下载器中间件中useragent.py文件中的UserAgentMiddleware类

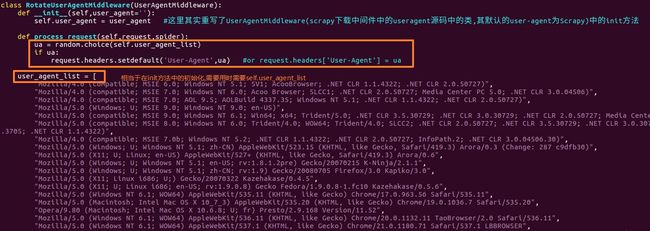
与上一个方法原理其实基本一致,这里,第一步继承UserAgentMiddleware类之后,重写init方法,user_agent默认为""
之后的process_requset就是每次请求经过中间件的时候,获取request,并为request的请求头加上UA,setdefault('User-Agent',ua) 与直接中headers中的键值对添加,是一样的效果.
启用这个中间件...(因为settings.py 和middlewares.py 在同一个目录下,所以可以直接在settings的设置中,直接写)

还是之前的代码,运行试试即可...

两次请求有不一样的UA,完成...
当然还有其他可以对每次请求随机分配UA的,这里还需要再次研究,其中还有使用第三方user-agent库(fake-useragent)实现设置agent方法..可以继续深入研究一下...