爬虫学习(一)
爬虫学习(一)
- 1.1 学习get与post请求
- 1.2 尝试用requests发送get请求
- 1.3 申请返回的状态码
- 1.4 请求头
- 2.1 正则表达式
- 2.2 豆瓣top250爬取实战
- 3 遇到的问题
- 参考资料
1.1 学习get与post请求
get 和 post是HTTP中请求数据的方法:
GET 请求指定的页面信息,并返回实体主体;
POST 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。POST请求可能会导致新的资源的建立和/或已有资源的修改。
get与post的区别:
1.GET请求的数据会附在URL之后,以?分割URL和传输数据,参数之间以&相连,POST把提交的数据则放置在是HTTP包的包体中。
2.GET的长度受限于url的长度,而url的长度限制是特定的浏览器和服务器设置的,理论上GET的长度可以无限长。
3.POST是没有大小限制的,HTTP协议规范也没有进行大小限制,起限制作用的是服务器的处理程序的处理能力。
4.POST的安全性要比GET的安全性高。
1.2 尝试用requests发送get请求
import requests
#get请求
r=requests.get("http://www.baidu.com");
r.encoding="itf-8";
print(r.text);
返回结果:
 断网后返回
断网后返回
requests.exceptions.ConnectionError: HTTPConnectionPool(host='www.baidu.com', port=80): Max retries exceeded with url: / (Caused by NewConnectionError(': Failed to establish a new connection: [Errno 11001] getaddrinfo failed',))
1.3 申请返回的状态码
HTTP状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型,后两个数字没有分类的作用。HTTP状态码共分为5种类型:
HTTP状态码分类
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
详细的状态码可以参考http状态码。
1.4 请求头
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成:
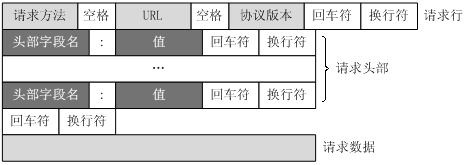
HTTP请求头,以明文的字符串格式传送,是以冒号分隔的键/值对,如:Accept-Charset: utf-8,每一个消息头最后以回车符(CR)和换行符(LF)结尾。HTTP消息头结束后,会用一个空白的字段来标识,这样就会出现两个连续的CR-LF。
常用请求头:
| 请求头 | 说明 | 示例 | 状态 |
|---|---|---|---|
| Accept | 可接受的响应内容类型(Content-Types)。 | Accept: text/plain | 固定 |
| Accept-Charset | 可接受的字符集 | Accept-Charset: utf-8 | 固定 |
| Accept-Encoding | 可接受的响应内容的编码方式。 | Accept-Encoding: gzip, deflate | 固定 |
| Accept-Language | 可接受的响应内容语言列表。 | Accept-Language: en-US | 固定 |
| Accept-Datetime | 可接受的按照时间来表示的响应内容版本 | Accept-Datetime: Sat, 26 Dec 2015 17:30:00 GMT | 临时 |
| Authorization | 用于表示HTTP协议中需要认证资源的认证信息 | Authorization: BasicOSdjJGRpbjpvcGVuIANlc2SdDE== | 固定 |
| Cache-Control | 用来指定当前的请求/回复中的,是否使用缓存机制。 | Cache-Control: no-cache | 固定 |
| Connection | 客户端(浏览器)想要优先使用的连接类型 | Connection: keep-alive | 固定 |
| Cookie | 由之前服务器通过Set-Cookie(见下文)设置的一个HTTP协议Cookie | Cookie: $Version=1; Skin=new; | 固定:标准 |
| Content-Length | 以8进制表示的请求体的长度 | Content-Length: 348 | 固定 |
| Content-MD5 | 请求体的内容的二进制 MD5 散列值(数字签名),以 Base64 编码的结果 | Content-MD5: oD8dH2sgSW50ZWdyaIEd9D== | 废弃 |
| Content-Type | 请求体的MIME类型 (用于POST和PUT请求中) | Content-Type: application/x-www-form-urlencoded | 固定 |
| Date | 发送该消息的日期和时间(以RFC 7231中定义的"HTTP日期"格式来发送) | Date: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Expect | 表示客户端要求服务器做出特定的行为 | Expect: 100-continue | 固定 |
| From | 发起此请求的用户的邮件地址 | From: [email protected] | 固定 |
| Host | 表示服务器的域名以及服务器所监听的端口号。如果所请求的端口是对应的服务的标准端口(80),则端口号可以省略。 | Host: www.itbilu.com:80 | 固定 |
| If-Match | 仅当客户端提供的实体与服务器上对应的实体相匹配时,才进行对应的操作。主要用于像 PUT 这样的方法中,仅当从用户上次更新某个资源后,该资源未被修改的情况下,才更新该资源。 | If-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Modified-Since | 允许在对应的资源未被修改的情况下返回304未修改 | If-Modified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| If-None-Match | 允许在对应的内容未被修改的情况下返回304未修改( 304 Not Modified ),参考 超文本传输协议 的实体标记 | If-None-Match: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Range | 如果该实体未被修改过,则向返回所缺少的那一个或多个部分。否则,返回整个新的实体 | If-Range: “9jd00cdj34pss9ejqiw39d82f20d0ikd” | 固定 |
| If-Unmodified-Since | 仅当该实体自某个特定时间以来未被修改的情况下,才发送回应。 | If-Unmodified-Since: Dec, 26 Dec 2015 17:30:00 GMT | 固定 |
| Max-Forwards | 限制该消息可被代理及网关转发的次数。 | Max-Forwards: 10 | 固定 |
| Origin | 发起一个针对跨域资源共享的请求(该请求要求服务器在响应中加入一个Access-Control-Allow-Origin的消息头,表示访问控制所允许的来源)。 | Origin: http://www.itbilu.com | 固定: 标准 |
| Pragma | 与具体的实现相关,这些字段可能在请求/回应链中的任何时候产生。 | Pragma: no-cache | 固定 |
| Proxy-Authorization | 用于向代理进行认证的认证信息。 | Proxy-Authorization: Basic IOoDZRgDOi0vcGVuIHNlNidJi2== | 固定 |
| Range | 表示请求某个实体的一部分,字节偏移以0开始。 | Range: bytes=500-999 | 固定 |
| Referer | 表示浏览器所访问的前一个页面,可以认为是之前访问页面的链接将浏览器带到了当前页面。Referer其实是Referrer这个单词,但RFC制作标准时给拼错了,后来也就将错就错使用Referer了。 | Referer: http://itbilu.com/nodejs | 固定 |
| TE | 浏览器预期接受的传输时的编码方式:可使用回应协议头Transfer-Encoding中的值(还可以使用"trailers"表示数据传输时的分块方式)用来表示浏览器希望在最后一个大小为0的块之后还接收到一些额外的字段。 | TE: trailers,deflate | 固定 |
| User-Agent | 浏览器的身份标识字符串 | User-Agent: Mozilla/…… | 固定 |
| Upgrade | 要求服务器升级到一个高版本协议。 | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 | 固定 |
| Via | 告诉服务器,这个请求是由哪些代理发出的。 | Via: 1.0 fred, 1.1 itbilu.com.com (Apache/1.1) | 固定 |
| Warning | 一个一般性的警告,表示在实体内容体中可能存在错误。 | Warning: 199 Miscellaneous warning | 固定 |
创建请求头:
header={'User-Agent': 'python-requests/2.21.0', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
r=requests.get("http://www.baidu.com",headers=header);
2.1 正则表达式
简介:
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
re 模块使 Python 语言拥有全部的正则表达式功能。
compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象。该对象拥有一系列方法用于正则表达式匹配和替换。
re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数。
re模块:
| 方法 | 参数 | 返回值 | 作用 |
|---|---|---|---|
| match | pattern,string,flag | 匹配成功返回一个匹配的对象,否则返回None | 从字符串的起始位置匹配一个模式 |
| search | pattern,string,flag | 匹配成功返回一个匹配的对象,否则返回None | 扫描整个字符串并返回第一个成功的匹配 |
| sub | pattern, repl, string, count=0, flags=0 | 用repl替换模式匹配串pattern次数为count,count为0表示全部替换 | 替换字符串中的匹配项 |
| compile | pattern,flags | 返回编译后的正则表达式对象 | 编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用 |
| findall | string,pos,endpos | 返回一个匹配的所有子串的列表,如果没有找到匹配的,则返回空列表 | 找到正则表达式所匹配的所有子串 |
| finditer | pattern, string, flags | 作为一个迭代器返回匹配的所有子串 | 找到正则表达式所匹配的所有子串,生成一个迭代器 |
| split | pattern, string[, maxsplit=0, flags=0] | 按照能够匹配的子串将字符串分割后返回列表 | 按照能够匹配的子串将字符串分割 |
修饰符flag:
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
正则表达式模式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
2.2 豆瓣top250爬取实战
import requests;
import re;
#get请求
header={'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 5.2)Gecko/2008070208 Firefox/3.0.1', 'Accept-Encoding': 'gzip, deflate', 'Accept': '*/*', 'Connection': 'keep-alive'}
numbers=0
for num in range(0,250,25):
url="https://movie.douban.com/top250?start=%s&filter="%num
r = requests.get(url,headers=header);
r.encoding="utf-8";
sub=re.compile(r".*?(.*?)"
r'.*?(.*?)'
r'.*? / (.*?)'
r'.*?.*?: (.*?) .*? (\d+).*?
'
r'.*?'
r'.*?(.*?)',re.S )
res=re.findall(sub,r.text)
for i in res:
rank = i[0]
title = i[1]
title_other = i[2]
author = i[3]
year = i[4]
scores = i[5]
paragraph = i[6]
sup = {'rank': rank, 'title': title + ' / ' + title_other, 'author': author, 'year': year,
'score': scores, 'paragraph': paragraph}
print(sup)
结果:

3 遇到的问题
1.中文正则表达式匹配[u4e00-u9fa5] ;
2.爬取结果经正则表达式处理后没有250行数据,待解决;
3.写正则式借鉴了其他人的代码,但效果还是不够理想。
参考资料
常用的HTTP请求头与响应头
python正则表达式
爬虫入门