MySQL数据库管理-体系结构
MySQL数据库管理-体系结构
概述
MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,属于 Oracle 旗下产品。MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件之一。
MySQL 在整体架构上分为 Server 层和存储引擎层。
其中 Server 层,包括连接器、查询缓存、分析器、优化器、执行器等,存储过程、触发器、视图和内置函数都在这层实现。数据引擎层负责数据的存储和提取,如 InnoDB、MyISAM、Memory 等引擎。在客户端连接到 Server 层后,Server 会调用数据引擎提供的接口,进行数据的变更。
单点(Single),适合小规模应用,复制(Replication),适合中小规模应用,集群(Cluster),适合大规模应用。
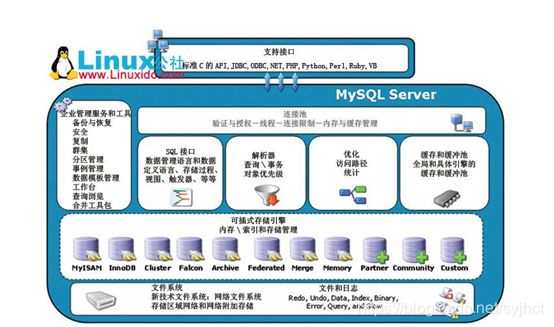

一 MySQL体系构架-解析
MySQL数据库组件:连接池组件,管理服务和工具组件,SQL接口组件,查询分析器组件,优化器组件,缓冲(Cache)组件,插件式存储引擎,物理文件。
MySQL不同于其他数据库,它的存储引擎是“可插拔”的,意思就是MySQL Server的核心基础代码和存储引擎是分离的,你可以使用最适合应用的引擎,也就是说MySQL支持不同的表使用不同的引擎。MySQL拥有20多 个引擎,
引擎。需要特别注意的是,存储引擎是基于表的,而不是数据库。
MySQL体系结构,它对于以后深人理解MySQL数据库会有极大的帮助。





连接器
负责和客户端建立连接,获取用户权限以及维持和管理连接。
通过show processlist来查询连接的状态。在用户建立连接后,即使管理员改变连接用户的权限,也不会影响到已连接的用户。默认连接时长为 8 小时,超过时间后将会被断开。
简单说下长连接:
1. 优势:在连接时间内,客户端一直使用同一连接,避免多次连接的资源消耗。
2. 劣势:在MySQL执行时,使用的内存被连接对象管理,由于长时间没有被释放,会导致系统内存溢出,被系统kill. 所以需要定期断开长连接,或执行大查询后,断开连接。MySQL 5.7 后,可以通过mysql_rest_connection初始化连接资源,不需要重连或者做权限验证。
查询缓存
当接受到查询请求时,会现在查询缓存中查询(key/value保存),是否执行过。没有的话,再走正常的执行流程。
但在实际情况下,查询缓存一般没有必要设置。因为在查询涉及到的表被更新时,缓存就会被清空。所以适用于静态表。在MySQL8.0后,查询缓存被废除。
分析器
1. 词法分析:如识别select,表名,列名,判断其是否存在等。
2. 语法分析:判断语句是否符合MySQL语法。
优化器
确定索引的使用,join表的连接顺序等,选择最优化的方案。
执行器
在具体执行语句前,会先进行权限的检查,通过后使用数据引擎提供的接口,进行查询。如果设置了慢查询,会在对应日志中看到rows_examined来表示扫描的行数。在一些场景下(索引),执行器调用一次,但在数据引擎中扫描了多行,所以引擎扫描的行数和rows_examined并不完全相同。
不预先检查权限的原因:如像触发器等情况,需要在执行器阶段才能确定权限,在优化器阶段无法验证。
1.1MySQL体系构架-文件类型
1.1.1参数文件:(位置)
mysql实例启动的时候在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了谋种内存结构的大小等设置,还介绍了参数类型以及定义作用域,Mysql实例启动时,会先读取配置参数文件my.cnf。
1.1.2日志文件: (位置)
记录mysq|对某种条件做出响应时候写入的文件,记录了影响mysql数据库的各种类型活动,常见的日志文件有错误日志、 二进制日志、慢查询日志、全查询日志、redo日志、undo日志。
错误日志:错误日志对mysql的启动、运行、关闭过程进行了记录,问题分析必看。
二进制日志:记录了对数据库进行变更的操作,但是不包括select操作以及show操作。主要用于恢复( recovery)、复制( replication )。
慢查询日志:记录运行较慢的sq|语句信息,给sq|语句的优化带来很好的帮助。
全查询日志:记录mysq|所有的请求,数据库审计+问题排查跟踪性,损失3%-5%性能。
redo日志:
数据库都是日志先行,先写日志,再写数据文件,保证恢复与完整性。这个对innodb存储引擎非常重要,因为它们记录了对于innodb存储引擎的事务日志。
undo日志:
里面存储了与redo相反的数据更新操作,如果rollback的话,就把undo段里面数据回写到数据文件里面。
Redo与undo他们并不是各自独立没有关系的,他们是有关联的,交替合作来保证数据的一致性和安全性。
1.1.3 其他文件
Socket文件:当用linux的mysq|l命令行窗口登录的时候需要的文件, Linux系统下本地连接mysq可以采用linux域套接字socket方式, 需要一个套接字socket发文件 ,可以有参数socket控制,一般默认在/tmp目录下
Pid文件: mysql实例的进程文件,当mysq|实例启动的时候,会将自己的进程id写入一个文件中,该文件即为pid文件,由参数pid_ file控制 ,默认路径位于数据库目录下
Mysq表结构文件:存放mysql表结构定义文件,如: *.frm ,*.ibd
存储引擎文件:记录存储引擎信息的文件, innodb存储引擎在存储设计上模仿了oracle ,该文件就是默认的表空间文件,可以用多个文件组成一个表空间。
1.2实例与数据库
数据库指的是文件的集合,是按照某种数据模型组织起来的并以二进制存储的数据集合。
数据库实例是应用程序,是位于用户与操作系统之间的一层数据管理软件,用户对数据库进行操作,包括定义表结构,数据查询,数据维护等控制,都是在数据库实例下进行的,可以这样理解,应用程序通过数据库实例才能和数据库打交道。
说的再明白点:数据库是由一个个的文件组成(一般来说都是二进制文件)的,要对这些文件进行SELECT、UPDATE、INSERT和DELETE这种数据库操作,不可能直接对这些二进制文件进行操作,来更新数据库中的数据,这个时候就需要数据库实例来完成对数据库的操作。

1MySQL是单进程多线程(而Oracle等是多进程),也就是说MySQL实例在系 统上表现就是一个服务进程,即进程(通过多种方法可以创建多实例,再安装一个端口号不同的mysql,或者通过workbench来新建一个端口号不同的 服务器实例等)。
2MySQL实例是线程和内存组成,实例才是真正用于操作数据库文件的(MySQL数据库是由一些列物理文件组成,类似于frm、MYD、MYI、ibd结尾的文件);
3一般情况下一个实例操作一个或多个数据库(Oracle一个实例对应一个数据库);集群情况下多个实例操作一个或多个数据库。

1.3MySQL体系构架-物理存储

二 MySQL存储引擎
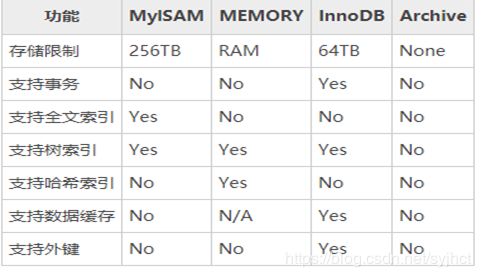
MySQL不同于其他数据库,它的存储引擎是‘可插拔”的,意思就是MySQL Server的核心基础代码和存储引擎是分离的,你可以使用最适合应用的引擎,也就是说MySQL支持不同的表使用不同的引擎。MySQL拥有20多个引擎,下面介绍几个常用的引擎。MySQL用得比较多的就三种存储引擎: MyISAM、InnoDB、 MEMORY。
MySQL 5.5以后默认使用InnoDB存储引擎,InnoDB通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了SQL标准的4种隔离级别,默认为REPEATABLE READ(可重复读)级别。基于行锁。
2.1 三种存储引擎: MyISAM,InnoDB,MEMORY介绍
2.1.1 MyISAM存储引擎
这种存储引擎不支持事务, 不支持行级锁(支持表锁),只支持并发插入的表锁,主要用于高负载的select。
支持3种不同的存储格式,分别是:静态表;动态表;压缩表
静态表:表中的字段都是非变长字段,这样每个记录都是固定长度的,优点存储非常迅速,容易缓存,出现故障容易恢复;缺点是占用的空间通常比动态表多(因为存储时会按照列的宽度定义补足空格)
动怂表:记录不是固定长度的,这样存储的优点是占用的空间相对较少;缺点:频繁的更新、删除数据容易产生碎片,需要定期得对表进行优化/检查/修复。
压缩表:因为每个记录是被单独压缩的,所以只有非常小的访问开支
2.1.2 InnoDB存储引擎
该存储弓|擎提供了具有提交、回滚和崩溃恢复能力的事务安全,支持行级锁、使用了B+Tree索引、支持自动增长列,支持外键约束。但是对比MyISAM引擎,写的处理效率会差一 些,并且会占用更多的磁盘空间以保留数据和索引。
2.1.3 MEMORY存储引擎:
使用存在于内存中的内容来创建表。
每个memory表只实际对应一个磁盘文件,格式是.frm ,该文件只存储表的结构,而其数据文件,都是存储在内存中,这样有利于对数据的快速处理,提高整个表的处理能力。memory因为它的数据是放在内存中的,但是一旦服务关闭 ,表中的数据就会丢失掉。
2.1.4 区别MyISAM,InnoDB,MEMORY
memory
存储引擎默认使用哈希( HASH )索引,其速度比使用B-+Tree型要快。
Hash索引结构:其检索效率非常高,索弓|的检索可以一次定位。
B-Tree索引:需要从根节点到枝节点,最后才能访问到页节点这样多次的I0访问。
所以Hash索弓|的查询效率要远高于B-Tree索引。
虽然Hash索引效率高,但是Hash索引本身由于其特殊性也带来了很多限制和弊端,功能有限,支持也有限。
MyISAM:默认的MySQL插件式存储引擎,它是在Web、数据仓储和其他应用环境下最常使用的存储引擎之一。注意,通过更改STORAGE_ENGINE配置变量,能够方便地更改MySQL服务器的默认存储引擎。
· InnoDB:用于事务处理应用程序,具有众多特性,包括ACID事务支持。(提供行级锁)
· BDB:可替代InnoDB的事务引擎,支持COMMIT、ROLLBACK和其他事务特性。
· Memory:将所有数据保存在RAM中,在需要快速查找引用和其他类似数据的环境下,可提供极快的访问。
· Merge:允许MySQL DBA或开发人员将一系列等同的MyISAM表以逻辑方式组合在一起,并作为1个对象引用它们。对于诸如数据仓储等VLDB环境十分适合。
· Archive:为大量很少引用的历史、归档、或安全审计信息的存储和检索提供了完美的解决方案。
· Federated:能够将多个分离的MySQL服务器链接起来,从多个物理服务器创建一个逻辑数据库。十分适合于分布式环境或数据集市环境。
· Cluster/NDB:MySQL的簇式数据库引擎,尤其适合于具有高性能查找要求的应用程序,这类查找需求还要求具有最高的正常工作时间和可用性。
· Other:其他存储引擎包括CSV(引用由逗号隔开的用作数据库表的文件),Blackhole(用于临时禁止对数据库的应用程序输入),以及Example引擎(可为快速创建定制的插件式存储引擎提供帮助)。
三 InnoDB存储引擎详解
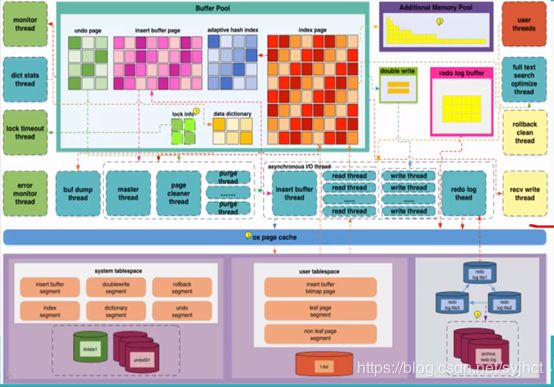
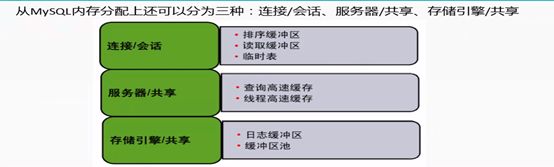
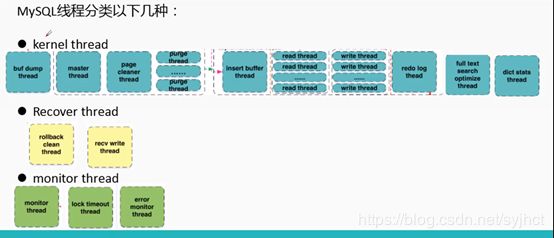
3.1 InnoDB存储引擎-内存结构
InnoDB Buffer Pool :不仅仅缓存索引数据,还会缓存表的数据,而且完全按照数据文件中的数据快结构信息来缓存,这一点和Oracle SGA中的database buffer cache非常类似。所以,InnoDB Buffer Pool对InnoDB存储引擎的性能影响之大就可想而知了。
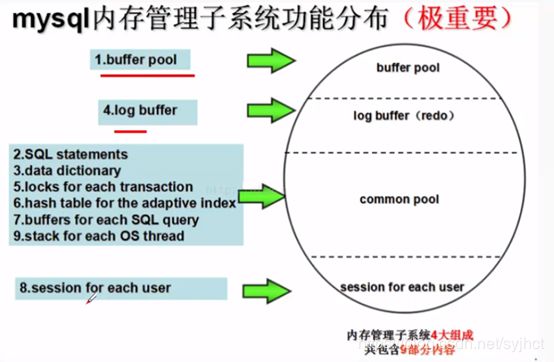
3.1.1 Buffer Pool
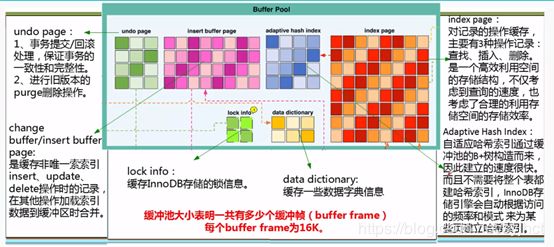
3.1.2 Additional Memory Pool: ;

其参数innodb_ additional mem_ pool_ size 是InnoDB用来保存数据字典信息和其他内部数据结构的内存池的大小,单位是byte ,参数默认值为8M。数据库中的表数量越多,参数值应该越大,如果InnoDB用完了内存池中的内存,就会从操作系统中分配内存,同时在error log中打入报警信息,这个参数以后会被弃用。
3.1.3 redo buffer
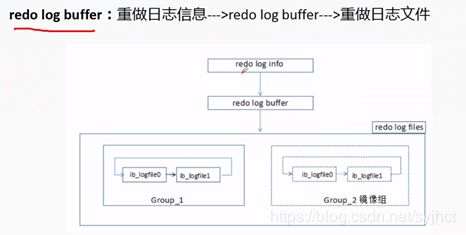
innodb_ log_ _byffer_ size的大小: (默认8M)
将重做日志缓冲中的内容刷新到外部磁盘的重做日志文件中的3种情况:
1、Master Thread每一秒将重做日志缓冲刷新到重做日志文件 ;
2、每个事务提交时会将重做日志缓冲刷新到重做日志文件;
3、当重做日志缓冲池剩余空间小于1/2时 ,重做日志缓冲刷新到重做日志文件。
3.1.4 二进制日志缓冲区( Binlog Buffer )
主要用来缓存由于各种数据变更操做所产生的Binary Log信息。为了提高系统的性能,MySQL并不是每次都是将二进制日志直接写入Log File,而是先将信息写入BinlogBuffer中,当满足某些特定的条件之后再一次写入Log File文件中。
二进制日志和重做日志的对比3 :
类型
二进制日志:记录MySQL数据库相关的日志记录,包括InnoDB , MyISAM等其它存储引擎的日志。重做日志:只记录InnoDB存储弓|擎本身的事务日志。
内容
二进制日志:记录事务的具体操作内容,是逻辑日志。重做日志:记录每个页的更改的物理情况。
时间
二进制日志:只在事务提交完成后进行写入,只写磁盘一次,不论这时事务量多大。
重做日志:在事务进行中,就不断有重做日志条目(redo entry)写入重做日志文件。
3.1.5 Doube Write :
Doube Write :
是innodb表空间ibdata中一块连续的128 page=2M的存储空间 ,它的作用的是处理产生partial write时候的data recovery。
比如:如果发生了极端情况(断电),InnoDB再次启动后,发现了一个Page数据已经损坏那么此时就可以从doublewrite buffer中进行数据恢复了。
它的主要工作原理:
A . dirty page刷新到数据文件之前,先刷到double write buffer里。
B .然后将page内容刷新到数据文件中。
3.2 InnoDB存储引擎-逻辑存储结构

Oracle是表空间、段、区、块
MySQL是表空间、段、区、页
表空间:所有的数据都放在表空间里面。
段:表空间有若干各段组成,常见的有数据段/索引|段/回滚段等
区:每64个连续的页组成区,因此区大小正好为1M。
页:页是InnoDB磁盘管理的最小单位,固定大小为16K。
行: InnoDB表中数据按行存储。
表空间:所有数据都是存放在表空间中的, 启用了参数innodb_file_per_table ,则每张表内的数据可以单独放到一个表空间中,每张表空间内存放的只是数据,索引和插入缓冲,其他类的数据,如undo信息,系统事务信息,二次写缓冲等还是存放在原来你的共享表空间。
段(segment) :常见的segment有数据段、索引段、回滚段。innodb是索引 |聚集表,所以数据就是索引,索引就是数据,那么数据段即是B+树的页节点(leaf node segment) ,索|段即为B+树的非索引节点(non-leaf node segment) ,而且段的管理是由引|擎本身完成的。
区(extend):区是由64个连续的页主成,每个页大小为16K,即每个区的大小为(64* 1 6K)=1MB,对于大的数据段,mysql每次最多可以申请4个区,以此保证数据的顺序性能。
页(page)页是innodb磁盘管理最小的单位,innodb每个页的大小是16K,且不可更改。
常见的类型有:
数据页B-tree Node ;
undo页Undo Log Page ;
系统页System Page ;
事务数据页Transaction system Page ;
插入缓冲位图页Insert Buffer Bitmap ;
插入缓冲空闲列表页Insert Buffer freeBitmap ;
未压缩的二进制大对象页Uncompressed BLOB Page ;
压缩的二进制大对象页Compressed BLOB Page.
行:innodb存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存放。每个页最多可以存放16K/2 ~ 200行,也就是7992个行。
四 MySQL 日志模块
如前面所说,MySQL整体分为Server层和数据引擎层,而每层也对应了自己的日志文件。如果选用的是InnoDB引擎,对应的是redo log文件。Server层则对应了binlog文件。至于为什么存在了两种日志系统,咱们往下看。
4.1. redo log
redo log是InnoDB特有日志,为什么要引入redo log呢,想象这样一个场景,MySQL为了保证持久性是需要把数据写入磁盘文件的。我们知道,在写入磁盘时,会进行文件的 IO,查找操作,如果每次更新操作都这样的话,整体的效率就会特别低,根本没法使用。
既然直接写入磁盘不行,解决方法就是先写进内存,在系统空闲时再更新到磁盘就可以了。但光更新内存不行,假如系统出现异常宕机和重启,内存中没有被写入磁盘的数据就会被丢掉,数据的一致性就出现问题了。
这时redo log就发挥了作用,在更新操作发生时,InnoDb会先写入redo log日志(记录了数据发生了怎么样的改变),然后更新内存,最后在适当的时间再写入磁盘。先写日志,在写磁盘的操作,就是常说到的WAL(Write-Ahead- Logging)技术。
redo log的出现,除了在效率上有了很大的改善,还保证了MySQL具有了crash-safe的能力,在发生异常情况下,不会丢失数据。
在具体实现上redo log的大小是固定的,可配置一组为 4 个文件,每个文件1GB,更新时对四个文件进行循环写入。
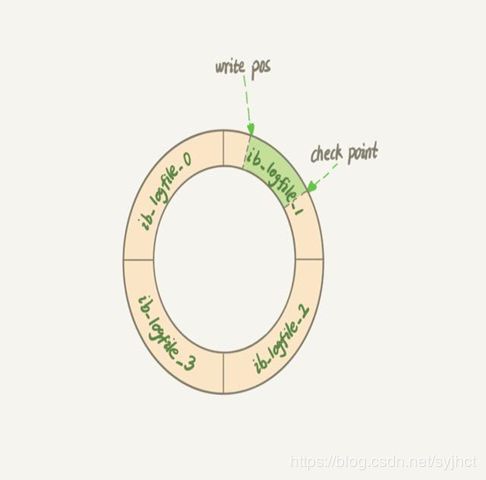
write pos记录当前写入的位置,写完就后移,当第写入第4个文件的末尾时,从第0号位置重新写入。
check point表示当前可以擦除的位置,当数据更新到磁盘时,check point就向后移动。
write pos和check point之间的位置,就是可以记录更新操作的空间。当write pos追上check point ,不在能执行新的操作,先让check point去写入一些数据。
可以将innodb_flush_log_at_trx_commit设置成1,开启redo log持久化的能力。
4.2. binlog
binlog则是Server层的日志,主要用于归档,在备份,主备同步,恢复数据时发挥作用,常见的日志格式有row, mixed, statement三种。
可以通过sync_binlog=1开启binlog写入磁盘。
这里对binlog和 redo进行下区分:
所有者不同:binlog是 Server层,所有引擎都可使用。redo log是 InnoDB特有的。
类型不同:binlog是逻辑日志,记录的是语句的原始逻辑(比 statement)。redo log是物理日志,记录某个数据页被做了怎样的修改。
数据写入的方式不同:binog日志会一直追加,而redo log是循环写入。
功能不同:binlog用于归档,而redo log用于保证crash-safe。
3. 两阶段提交
一条更新语句,在InnoDB引擎下的更新过程如下。在更新内存后,将写入redolog和写入 binlog放在一起成为一个事务最后一起写入redo log和 binlog的过程就是常说的两阶段提交。用于保证当有意外情况发生时,数据的一致性。

这里假设下,如果不采用两阶段提交会发生什么?
先写redo log后写binlog假设在写入redo log后,MySQL发生异常重启,此时binlog没有写入。在重启后,由于redolog已经写入,此时数据库的内容是没有问题的。但此时,如果想要拿binlog进行备份或恢复,发现会少了最后一条的更新逻辑,导致数据不一致。
先写binlog和redo log. binlog写入后,MySQL异常重启,redo log没有写入。此时重启后,发现redo log没有成功写入,认为这个事务无效,而此时binlog却多了一条更新语句,拿去恢复后自然数据也是不一致的。
再分析下两阶段提交的过程:
在写redo log prepare阶段奔溃,重启后,发现redo log没写入,回滚此次事务。
如果在写binlog时奔溃,重启后,发现binlog未被写入,回滚操作
如果在写入redo log和binlog后崩溃,重启后,发现没提交,则进行commit。
总结
在文章开始部分,说明了MySQL的整体架构分为Server层和引擎层,并简要说明了一条语句的执行过程。接着MySQL在5.5后选用InnoDB作为默认的引擎,就是因为比原生的MyISAM多了事务以及crash-safe的能力。
而crash-safe就是由redo log实现的。与redo log类似的日志文件还有binlog,是Server引擎的日志,用于归档和备份数据。
最后提到了,为了保证数据的一致性,将redo log和binlog放入相同的事务中,也就是常提到的两阶段提交操作。