PageRank 笔记
转载自:
https://blog.csdn.net/weixin_43378396/article/details/90322422
PageRank
要说到 PageRank 算法的来源,这个要从搜索引擎的发展讲起。最早的搜索引擎采用的是分类目录的方法,即通过人工进行网页分类并整理出高质量的网站。那时 Yahoo 和国内的 hao123 就是使用这种方法。
后来网页越来越多,人工分类已经不现实了。搜索引擎进入了文本检索的时代,即计算用户查询关键词与网页内容的相关程度来返回搜索结果。这种方法突破了数量的限制,但是搜索结果不是很好。因为总有某些网页来回地倒腾某些关键词使自己的搜索排名靠前。
于是我们的主角登场了。谷歌的两位创始人,当时还是美国斯坦福大学研究生的佩奇和布林开始了对网页排序问题的研究。他们借鉴了学术界评判学术论文重要性的通用方法,那就是看论文的引用次数。由此想到网页的重要性也可以根据这种方法来评价。于是 PageRank 的核心思想就诞生了。
如果一个网页被很多其他网页链接到的话,说明这个网页比较重要,也就是 PageRank 值会相对较高。
如果一个 PageRank 值很高的网页链接到一个其他的网页,那么链接到的网页的 PageRank 值也会相应地提高。
PageRank 算法计算每一个网页的 PageRank 值,然后根据这个值的大小对网页的重要性进行排序。它的思想是模拟一个悠闲的上网者,上网者首先随机选择一个网页打开,然后在这个网页上呆了几分钟,跳转到该网页所指向的链接,这样无所事事、漫无目的地在网页上跳来跳去,PageRank 就是估计这个悠闲的上网者分布在各个网页上的概率。
PageRank 背后的两个基本假设:
数量假设:更重要的网页可能被更多的网页链接到。
质量假设:有更高的 PageRank 的网页将会传递更高的权重。
PageRank 模型
我们可以将 Web 作如下抽象:
- 将每个网页抽象成一个节点;
- 如果一个页面 A 有链接直接链向 B,则存在一条有向边从 A 到 B。
因此,整个 Web 被抽象为一张有向图。
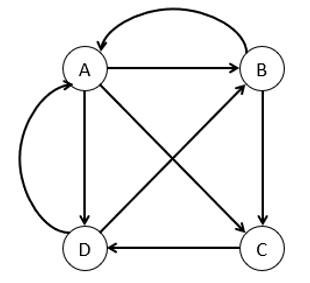
此时,我们需要用一种合适的数据结构来表示页面以及页面间的连接关系。假设当一个用户停留在某页面时,跳转到它所链接的所有页面的概率是相同的。例如,上图中 A 页面链向 B、C、D,所以用户从 A 页面跳转到 B、C、D 的概率各为 1/3。设一共有 N 个网页,则可以组织这样一个 N 维矩阵:其中 i 行 j 列的值表示用户从页面 j 跳转到页面 i 的概率。这样的一个矩阵叫做转移矩阵(Transition Matrix)。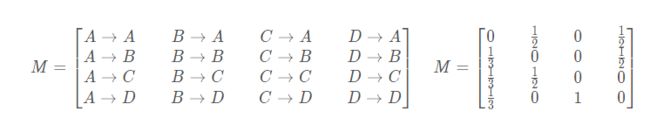
观察转移矩阵可以发现:
矩阵的每一列代表一个具体网页的出链,简单地说就是当前网页向其他网页的链接;
矩阵的每一行代表一个具体网页的入链,简单地说就是其他网页向当前网页的链接。
PageRank 初始化
PageRank 值的物理意义是一个网页被访问的概率,初始时用户访问每个页面的概率均等,假设一共有 N 个网页,每个网页的初始 PR 值 = 1 / N。我们可以将这些网页的初始 PR 值保存到一个向量中。
继续沿用先前的图,初始 PR 值向量![]()
PageRank 计算
继续使用先前的例子,由 A、B、C、D 四个页面组成的 Web。
对于页面 A 来说,有 B、D 页面链向它,那么 A 的 PR 值(PageRank 值)将是 B、D 页面 PR 值之和。
![]()
由于页面 B 也有链接到页面 C,一个页面不能投票 2 次,所以 B 给每个页面半票。同样的,D 投出的票也只有 1/2 算到了 A 的 PageRank 上。
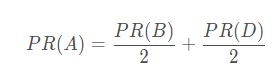
我们再把上面的公式简化一下,将其推广到更大的范围。
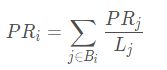
![]()
这样,我们就可以计算任意一个网页的 pagerank 值。那么要怎么计算呢?观察 PR(A) 的计算公式我们可以发现,PR(A) 实际上等于转移矩阵 M 的第一行乘上初始 PR 值。我们回想一下转移矩阵的性质,每一行表示其他网页链接到当前网页的概率,这一行的概率指相加实际上就是我们上述推导的公式。所以,如果要同时计算 Web 上的所有页面,我们可以直接计算转移矩阵 M 每一行的概率值累加和。
由于我们计算的是概率值,且初始每个页面的概率都相等,因此我们可求出在经过上述出链和入链后,各个页面的停留概率。

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cKD0rPuB-1584525452315)(https://s2.ax1x.com/2019/04/28/EQ86Qx.jpg)]
终止点问题
先前所举的例子是一个理想状态:假设所有网页组成的有向图是强连通的,即从一个网页可以到达任意网页。但实际的网络链接环境没有这么理想,有一些网页不指向任何网页,或不存在指向自己的链接。

【终止点】:一个没有任何出链的网页,例如上图的 C 点。上网者浏览到 C 网页将终止于该网页,而无法继续浏览其他网页。
根据上图我们可以写出转移矩阵 M:

可以看到,经过多次跳转之后,所有网页的 PR 值都是 0,这样的计算结果是无意义的。为什么会这样?因为转移矩阵 M 的第 3 列全为 0,这是导致迭代结果最终归零的“罪魁祸首”。

【解决方案】:当访问到终止点 C 而“走投无路”时,以等概率随机跳转到下一个网页,从而开启一次新的访问。
改造终止点 C,使它能够等概率地游走到网络中的所有页面,即添加从 C 到包括它本身的所有页面的链接。
在上例中就是将转移矩阵 M 的第三列的每一项改为 1/4。这样改造后,每一个节点都有出链,相应的 M 的每一列的列累加和都为 1。
陷阱问题


随机浏览模型
假定一个上网者从一个随机的网页开始浏览,此时有两种选择:
- 通过点击当前页面的其他链接开始下一次浏览;
- 通过在浏览器的地址栏输入新的地址以开启一个新的网页。
其中,上网者通过点击链接开启新页面的概率为 d(d 也称阻尼系数,通常取 0.85)。此时,我们的 PageRank 模型变为:在每一个页面,用户都有 d 的概率通过点击链接进入下一个页面;此外,还有 1 - d 的概率随机跳转,此时跳转到其他页面的概率为 1 / N(当前页面的其他链接数)。

随机浏览模型的收敛性

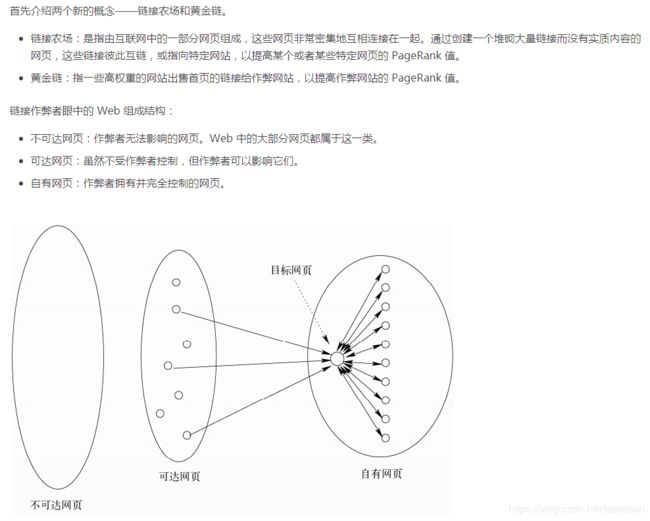
Link Spam 与反作弊

PageRank 算法缺点
- 主题漂移问题:PageRank 算法仅利用网络的链接结构,无法判断网页内容上的相似性;且算法根据向外链接平均分配权值使得主题不相关的网页获得与主题相关的网页同样的重视度,出现主题漂移。
- 没有过滤广告链接和功能链接:例如常见的“分享到微博”,这些链接通常没有什么实际价值,前者链接到广告页面,后者常常链接到某个社交网站首页。
- 对新网页不友好:一个新网页的入链相对较少,即便它的内容质量很高,但要成为一个高 PR 值的页面仍需要很长时间的推广。
其他:搜索引擎的发展趋势
- 社会化搜索
随着Facebook的流行,社交网络平台和应用占据了互联网的主流,社交网络平台强调用户之间的联系和交互,这对传统的搜索技术提出了新的挑战。
传统搜索技术强调搜索结果和用户需求的相关性,社会化搜索除了相关性外,还额外增加了一个维社交网络内其他用户发布的信息、点评或验证过的信息则更容易信赖,这是与用户度,即搜索结果的可信赖性。对某个搜索结果,传统的结果可能成千上万,但如果处于用户的心里密切相关的。社会化搜索为用户提供更准确、更值得信任的搜索结果。
- 实时搜索
随着微博的个人媒体平台兴起,对搜索引擎的实时性要求日益增高,我想这也是搜索时引擎未来的一个发展方向。
实时搜索最突出的特点是时效性强,越来越多的突发事件首次发布在微博上,实时搜索核心强调的就是“快”,用户发布的信息第一时间能被搜索引擎搜索到。
不过在国内,实时搜索由于各方面的原因无法普及使用,比如 Google 的实时搜索是被重置的,百度也没有明显的实时搜索入口。
- 多媒体搜索
目前搜索引擎的查询还是基于文字的,即使是图片和视频搜索也是基于文本方式。那么未来的多媒体搜索技术则会弥补查询这一缺失。多媒体形式除了文字,主要包括图片、音频、视频。
多媒体搜索比纯文本搜索要复杂许多,一般多媒体搜索包含 4 个主要步骤:多媒体特征提取、多媒体数据流分割、多媒体数据分类和多媒体数据搜索引擎。
思维导图
————————————————
版权声明:本文为CSDN博主「clvsit」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43378396/article/details/90322422