Spark_Spark优化_使用kryo 序列化
参考文章:
1.Spark 配置Kryo序列化机制
https://www.jianshu.com/p/68970d1674fa
2.Spark kyro Serialization
https://www.jianshu.com/p/141bb0244f64
3.Spark中使用kyro序列化
https://blog.csdn.net/wangweislk/article/details/78999814
4.【Spark七十八】Spark Kyro序列化
https://www.iteye.com/blog/bit1129-2186449
基于Spark 2.2.0
首先说一下自己的感受,虽然这个 kryo 序列化是非常小的问题,但是网上文章,没有什么靠谱的,还需要亲自去实践。
为什么选用 Kryo 序列化
因为更快,flink 1.10.1 已经默认使用 kyro 序列化实现了,不知道 Spark 什么时候才能做到这个地步。
优势
Spark支持使用Kryo序列化机制。Kryo序列化机制,比默认的Java序列化机制,
1)速度要快,
2)序列化后的数据要更小。所以Kryo序列化优化以后,可以让网络传输的数据变少;在集群中耗费的内存资源大大减少。
前提
将自定义的类型作为RDD的泛型类型时(比如JavaRDD
Kyro序列化与Java序列化的对比
Spark 目前支持两种序列化机制:java native serialization 和 kryo serialization,默认使用的是Java native serialization。两者的区别:
| 类别 | 优点 | 缺点 | 备注 |
|---|---|---|---|
| java native serialization | 兼容性好、和scala更好融合 | 序列化性能较低、占用内存空间大(一般是Kryo Serialization 的10倍) | 默认的serializer |
| Kryo Serialization | 序列化速度快、占用空间小(即更紧凑) | 不支持所有的Serializable类型、且需要用户注册要进行序列化的类class | shuffle的数据量较大或者较为频繁时建议使用 |
Spark 中使用 Kryo序列化
步骤
Spark 中使用 Kryo 序列化主要经过两个步骤
1.声明使用 kryo 序列化
2.注册序列化类
1.声明使用 kryo 序列化
可以在程序中指定,例如
val conf = new SparkConf conf .set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
另一种方式,可以在 spark-submit 通过
--conf spark.serializer=org.apache.spark.serializer.KryoSerializer
2.注册序列化类
这里有两种方式
1.传递classes数组
2.在指定类中,通过kyro注册
1.传递classes数组
private[udf] case class User(id: Int, name: String, city: String)
val conf = new SparkConf
conf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// .set("spark.kryo.registrationRequired", "true")
//方法一
.set("spark.kryo.registrator", "com.spark.test.offline.udf.MyKryoRegistrator")
//方法二
.registerKryoClasses(
Array(
classOf[com.spark.test.offline.udf.User]
//, classOf[scala.collection.mutable.WrappedArray.ofRef[_]]
))
2.在指定类中,通过kyro注册
private[udf] case class User2(id: Int, name: String, city: String)
private[udf] case class User2(id: Int, name: String, city: String) class MyKryoRegistrator extends KryoRegistrator { override def registerClasses(kryo: Kryo): Unit = { kryo.register(classOf[User2]) kryo.register(classOf[scala.collection.mutable.WrappedArray.ofRef[_]]) } }
相关参数
- spark.serializer
spark 序列化使用的类,这里应该填写 org.apache.spark.serializer.KryoSerializer
- spark.kryo.registrator
spark kryo 序列化注册器类,(选填)
- spark.kryo.registrationRequired
是否相关类必须注册, 默认值 false
注意:应该设置为 true, 不过我遇到了一系列问题现在也没有解决 !!!
官方文档
Whether to require registration with Kryo. If set to 'true', Kryo will throw an exception if an unregistered class is serialized. If set to false (the default), Kryo will write unregistered class names along with each object. Writing class names can cause significant performance overhead, so enabling this option can enforce strictly that a user has not omitted classes from registration.
- spark.kryoserializer.buffer
如果要被序列化的对象很大,这个时候就最好将配置项spark.kryoserializer.buffer 的值(默认64k)设置的大些,使得其能够hold要序列化的最大的对象。
注意事项
spark.kryo.registrationRequired 是否相关类必须注册, 默认值 false
注意:应该设置为 true, 不过我遇到了一系列问题现在也没有解决 !!!
如果你没有注册需要序列化的class,Kyro依然可以照常工作,但会存储每个对象的全类名(full class name),这样的使用方式往往比默认的 Java serialization 还要浪费更多的空间。
代码示例
package com.spark.test.offline.optimize
import com.esotericsoftware.kryo.Kryo
import org.apache.spark.SparkConf
import org.apache.spark.serializer.KryoRegistrator
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
private[optimize] case class User(id: Int, name: String, city: String) extends Serializable
private[optimize] case class User2(id: Int, name: String, city: String) extends Serializable
class MyKryoRegistrator extends KryoRegistrator {
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[User2])
kryo.register(classOf[scala.collection.mutable.WrappedArray.ofRef[_]])
}
}
/**
* Created by szh on 2020/5/30.
*/
object SparkOptimizeKryo {
def main(args: Array[String]): Unit = {
val conf = new SparkConf
conf
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
//.set("spark.kryo.registrationRequired", "true")
//方法一
.set("spark.kryo.registrator", "com.spark.test.offline.optimize.MyKryoRegistrator")
//方法二
.registerKryoClasses(
Array(
classOf[User]
//, classOf[scala.collection.mutable.WrappedArray.ofRef[_]]
))
val spark = SparkSession
.builder()
.appName("sparkSql")
.master("local[1]")
.config(conf)
.getOrCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
//sc.setLogLevel("DEBUG")
val orgRDD = sc.parallelize(Seq(
User(1, "cc", "bj")
, User(2, "aa", "bj")
, User(3, "qq", "bj")
, User(4, "pp", "bj")
))
spark
.createDataFrame(orgRDD).show()
println("---------------------------")
println("---------------------------")
println("---------------------------")
val orgRDD2 = sc.parallelize(Seq(
User2(1, "cc", "bj")
, User2(2, "aa", "bj")
, User2(3, "qq", "bj")
, User2(4, "pp", "bj")
))
spark
.createDataFrame(orgRDD2).show()
//序列化方式存储大小比对
val arrTuple = new ArrayBuffer[(String, Int, String, String)]
val arrUser = new ArrayBuffer[User]
val nameArr = Array[String]("lsw", "yyy", "lss")
val genderArr = Array[String]("male", "female")
val addressArr = Array[String]("beijing", "shanghai", "shengzhen", "wenzhou", "hangzhou")
for (i <- 1 to 1000000) {
val name = nameArr(Random.nextInt(3))
val age = Random.nextInt(100)
val gender = genderArr(Random.nextInt(2))
val address = addressArr(Random.nextInt(5))
arrTuple.+=((name, age, gender, address))
arrUser.+=(User(age, name, address))
}
//序列化的方式将rdd存到内存
val rddTuple = sc.parallelize(arrTuple)
rddTuple.persist(StorageLevel.MEMORY_ONLY_SER)
rddTuple.count()
val rddUser = sc.parallelize(arrUser)
rddUser.persist(StorageLevel.MEMORY_ONLY_SER)
rddUser.count()
Thread.sleep(60 * 10 * 1000)
spark.stop()
}
}
输出
+---+----+----+
| id|name|city|
+---+----+----+
| 1| cc| bj|
| 2| aa| bj|
| 3| qq| bj|
| 4| pp| bj|
+---+----+----+
---------------------------
---------------------------
---------------------------
+---+----+----+
| id|name|city|
+---+----+----+
| 1| cc| bj|
| 2| aa| bj|
| 3| qq| bj|
| 4| pp| bj|
+---+----+----+
20/05/31 15:09:22 WARN TaskSetManager: Stage 2 contains a task of very large size (10171 KB). The maximum recommended task size is 100 KB.
20/05/31 15:09:25 WARN TaskSetManager: Stage 3 contains a task of very large size (5264 KB). The maximum recommended task size is 100 KB.
代码分析
1)代码演示了2种注册序列化类的方式
2)代码比较了两种 序列化方式的大小 :java 原生序列化大小 和 kryo 序列化大小
对比图
原生序列化
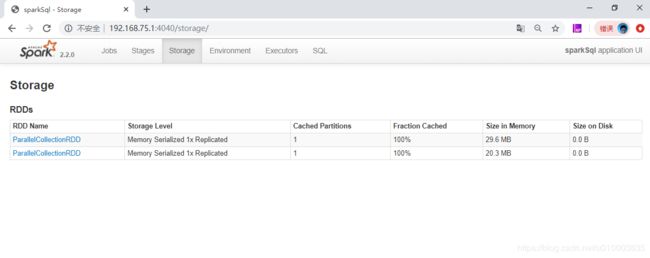
kryo 序列化
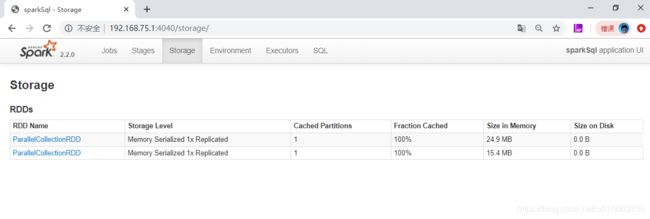
可以看出来 kyro 序列化占用的空间更小。
出现的问题与解决方法
1. 运行报错 java.lang.IllegalArgumentException: Class is not registered: scala.collection.mutable.WrappedArray$ofRef
完整错误信息
java.lang.IllegalArgumentException: Class is not registered: scala.collection.mutable.WrappedArray$ofRef
Note: To register this class use: kryo.register(scala.collection.mutable.WrappedArray$ofRef.class);
at com.esotericsoftware.kryo.Kryo.getRegistration(Kryo.java:488)
at com.esotericsoftware.kryo.util.DefaultClassResolver.writeClass(DefaultClassResolver.java:97)
at com.esotericsoftware.kryo.Kryo.writeClass(Kryo.java:517)
at com.esotericsoftware.kryo.Kryo.writeClassAndObject(Kryo.java:622)
at org.apache.spark.serializer.KryoSerializationStream.writeObject(KryoSerializer.scala:207)
at org.apache.spark.rdd.ParallelCollectionPartition$$anonfun$writeObject$1$$anonfun$apply$mcV$sp$1.apply(ParallelCollectionRDD.scala:65)
at org.apache.spark.rdd.ParallelCollectionPartition$$anonfun$writeObject$1$$anonfun$apply$mcV$sp$1.apply(ParallelCollectionRDD.scala:65)
at org.apache.spark.util.Utils$.serializeViaNestedStream(Utils.scala:184)
at org.apache.spark.rdd.ParallelCollectionPartition$$anonfun$writeObject$1.apply$mcV$sp(ParallelCollectionRDD.scala:65)
at org.apache.spark.rdd.ParallelCollectionPartition$$anonfun$writeObject$1.apply(ParallelCollectionRDD.scala:51)
at org.apache.spark.rdd.ParallelCollectionPartition$$anonfun$writeObject$1.apply(ParallelCollectionRDD.scala:51)
at org.apache.spark.util.Utils$.tryOrIOException(Utils.scala:1269)
at org.apache.spark.rdd.ParallelCollectionPartition.writeObject(ParallelCollectionRDD.scala:51)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at java.io.ObjectStreamClass.invokeWriteObject(ObjectStreamClass.java:1028)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1496)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1548)
at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1509)
at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1432)
at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1178)
at java.io.ObjectOutputStream.writeObject(ObjectOutputStream.java:348)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:43)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:100)
at org.apache.spark.scheduler.Task$.serializeWithDependencies(Task.scala:246)
at org.apache.spark.scheduler.TaskSetManager$$anonfun$resourceOffer$1.apply(TaskSetManager.scala:452)
at org.apache.spark.scheduler.TaskSetManager$$anonfun$resourceOffer$1.apply(TaskSetManager.scala:432)
at scala.Option.map(Option.scala:146)
at org.apache.spark.scheduler.TaskSetManager.resourceOffer(TaskSetManager.scala:432)
at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$org$apache$spark$scheduler$TaskSchedulerImpl$$resourceOfferSingleTaskSet$1.apply$mcVI$sp(TaskSchedulerImpl.scala:264)
at scala.collection.immutable.Range.foreach$mVc$sp(Range.scala:160)
at org.apache.spark.scheduler.TaskSchedulerImpl.org$apache$spark$scheduler$TaskSchedulerImpl$$resourceOfferSingleTaskSet(TaskSchedulerImpl.scala:259)
at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$resourceOffers$3$$anonfun$apply$8.apply(TaskSchedulerImpl.scala:333)
at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$resourceOffers$3$$anonfun$apply$8.apply(TaskSchedulerImpl.scala:331)
at scala.collection.IndexedSeqOptimized$class.foreach(IndexedSeqOptimized.scala:33)
at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:186)
at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$resourceOffers$3.apply(TaskSchedulerImpl.scala:331)
at org.apache.spark.scheduler.TaskSchedulerImpl$$anonfun$resourceOffers$3.apply(TaskSchedulerImpl.scala:328)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.scheduler.TaskSchedulerImpl.resourceOffers(TaskSchedulerImpl.scala:328)
at org.apache.spark.scheduler.local.LocalEndpoint.reviveOffers(LocalSchedulerBackend.scala:85)
at org.apache.spark.scheduler.local.LocalEndpoint$$anonfun$receive$1.applyOrElse(LocalSchedulerBackend.scala:64)
at org.apache.spark.rpc.netty.Inbox$$anonfun$process$1.apply$mcV$sp(Inbox.scala:117)
at org.apache.spark.rpc.netty.Inbox.safelyCall(Inbox.scala:205)
at org.apache.spark.rpc.netty.Inbox.process(Inbox.scala:101)
at org.apache.spark.rpc.netty.Dispatcher$MessageLoop.run(Dispatcher.scala:213)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
2018-01-08 10:40:41 [ dispatcher-event-loop-2:29860 ] - [ ERROR ] Failed to serialize task 0, not attempting to retry it.解决方法
sparkConf.registerKryoClasses(
Array(classOf[scala.collection.mutable.WrappedArray.ofRef[_]],
classOf[MyClass]))对 Array 进行注册